


AWS EMR에서 S3 사용 시 주의사항
📅 September 09, 2017
•⏱️3 min read
AWS EMR에서 Spark을 사용하는 경우, S3를 저장소로 사용하는 경우가 많습니다. 이때 주의해야 할 사항들을 정리해보았습니다.
- 최근 수정사항 : 해당 이슈는 EMR 최신 버전에서 대부분 해결되었습니다.
- 자세한 내용은 Parquet 형식의 EMRFS S3 최적화 커미터를 통한 Apache Spark 쓰기 성능 개선하기 에서 확인하시기 바랍니다.
AWS EMR, Spark 그리고 S3
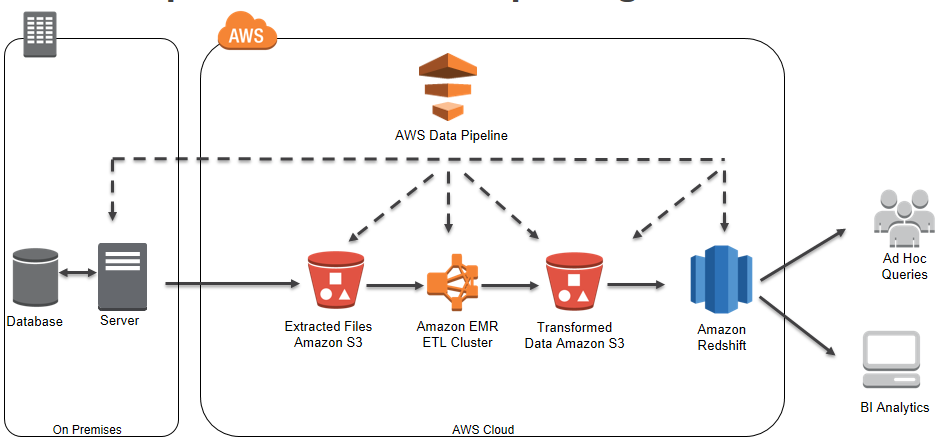
Daily로 돌려야 하는 ETL 작업의 경우 위와 같이 간단한 아키텍쳐로 구성하는 경우가 많습니다. 대부분의 경우 저장소로 S3를 적극 활용하게 됩니다. 최초 입수되는 로그를 저장하기도 하고, Transformation 작업 이후 중간 또는 최종 데이터로 저장하기도 합니다.
문제 상황
java.io.IOException: Connection reset by peer
ERROR ContextCleaner: Error cleaning broadcast 5최근 Spark RDD 코드를 DataFrame으로 리팩토링 하던 중에 위와 같은 오류를 겪었습니다. 일별 로그를 불러와서 전처리하고 다시 저장하는데 s3 write 부분에서 갑자기 Executor의 Connection이 끊기는 문제였습니다.
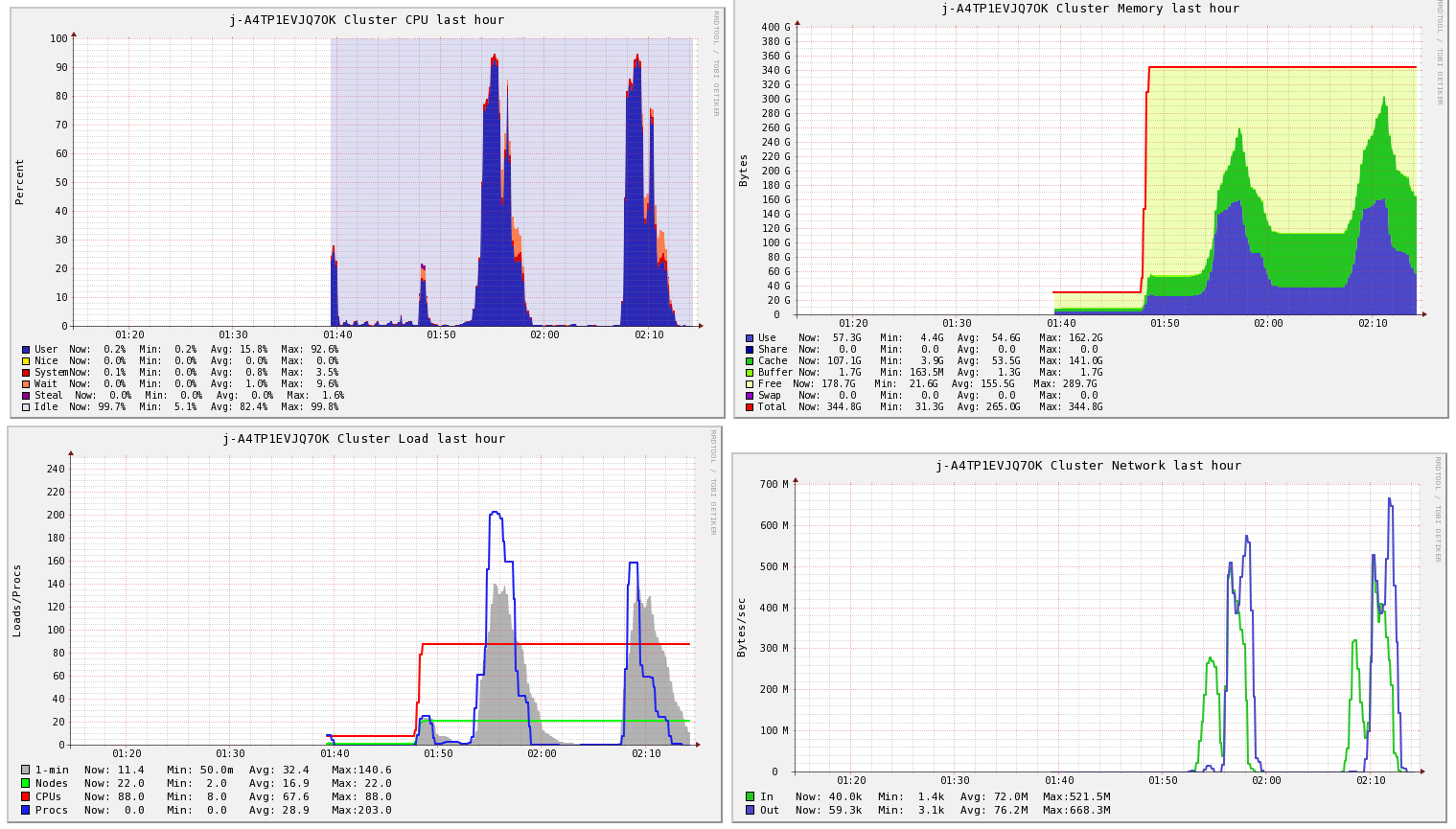
Ganglia 모니터링 결과를 보면 중간에 약 15분의 공백이 있는데, 이 부분이 Connection이 중간에 끊기고 다시 뜰 때까지 걸리는 시간입니다.
S3N, S3A, S3
먼저 S3는 File System이 아닌 Object Storage 라는 점을 알고 계셔야 합니다.
따라서, S3에 분산저장하는 경우, 우리는 Hadoop 클라이언트를 거쳐 저장하게 됩니다.
Hadoop은 S3N, S3A, S3 이렇게 세 가지 시스템 클라이언트를 제공합니다. 각 클라이언트는 URI 스키마를 통해 접근할 수 있습니다.
- S3N (s3n://) : S3N은 S3에 일반 파일을 읽고 쓰는 기본 파일 시스템입니다. S3N은 안정적이며 널리 사용되고 있지만 현재는 업데이트가 중단되었습니다. S3N의 단점은 파일 엑세스가 한번에 5GB로 제한되어 있다는 점입니다.
- S3A (s3a://) : S3A는 S3N을 개선한 다음 버전의 파일 시스템입니다. S3A는 Amazon의 라이브러리를 사용하여 S3와 상호 작용합니다. S3A는 5GB 이상의 파일 액세스를 지원하며 성능이 많이 향상되었습니다.
- S3 (s3://) : S3는 Hadoop 0.10 버전부터 나온 블록 기반의 S3 파일 시스템 입니다. 따라서 파일이 HDFS에 있는 것과 같이 블록으로 저장됩니다.
EMR은 EMRFS 라는 파일 시스템이 별도로 존재합니다. EMR의 S3 파일 시스템과 Hadoop에서의 S3 파일 시스템은 서로 다르기 때문에 항상 주의하셔야 합니다. EMR의 경우 s3 로 사용하는 것을 권장하고 있습니다. 반면에 s3a의 경우 EMRFS와 호환되지 않는다고 합니다. 물론 실행 될 때도 있지만 위와 같은 오류가 발생할 수도 있습니다.
Parquet 저장 성능 개선하기
위의 오류는 URI를 s3로 수정해서 해결할 수 있었습니다. 하지만 S3에 parquet로 저장하는 속도가 너무 느려 이 부분을 개선해보기로 했습니다.
먼저 Spark에는 Parquet 빌드 속도를 개선하기 위해 DirectParquetOutputCommitter라는 기능이 있었습니다.
하지만, S3에 저장할 때 이 기능을 사용하는 경우 데이터 유실이 발생할 수 있었습니다.
SPARK-10063 JIRA 티켓 참고
이러한 이유로 Spark 2.0 버전부터 이 옵션은 사라졌습니다. 그러나, 성능 개선이 필요했기 때문에 Spark 사용자들은 대안을 요구했습니다. 본래의 FileCommiter가 느린 이유는 rename 연산 때문이었습니다. 실제 파일 시스템(HDFS)에서 rename 연산은 대상 파일 시스템의 임시 디렉토리로 출력 한 다음, 디렉토리의 이름을 커밋하는 방식으로 O(1)이 소요됩니다. 하지만 Object Storage에 저장하는 경우, 데이터 사이즈만큼 O(N)이 소요됩니다.
이 문제는 s3guard와 s3a의 도움으로 해결되었습니다. getFileStatus()에서의 S3 HTTP 콜을 생략하고 dynamo metadata 저장 등을 통해 해결했다는데 자세한 내용은 MAPREDUCE-4815 JIRA 티켓을 보시는게 나을 듯 합니다.
spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version 2
spark.speculation False적용하는 방법은 위의 Spark property 옵션을 추가해주시면 됩니다. Spark 2.1, Hadoop 2.7.2 버전 이상부터 사용가능 합니다. 하지만 Spark 문서에도 나와있듯이 아직 failure에 대한 보장이 떨어집니다. 따라서 먼저 로컬 HDFS에 임시저장 후 distcp 명령어를 사용하여 S3로 저장해주시면 됩니다. Hadoop 2.8 버전부터는 s3guard가 기본으로 들어가기 때문에 안정화 될 것 이라고 합니다.
결과는 로그 1억 건 기준 약 10배 의 성능 개선을 확인할 수 있었습니다. 두서없이 정리하다보니 좀 글이 복잡해졌네요. 결론은 '옵션을 추가하자' 입니다.