


머신러닝을 시작하기 위한 기초 지식 (1)
📅 February 05, 2017
•⏱️3 min read
이 글의 목차나 그림은 Sebastian Rashka - Python Machine Learning 을 참고하였습니다.
사실 기계학습, 인공지능에 대한 연구는 예전부터 존재했지만 발전이 없었으며 소수에 연구원들에 의한 주제였기에 대중화 될 수 없었습니다. 하지만 풍부한 데이터의 확보, 컴퓨팅 성능향상, 오픈소스 라이브러리로 인해 많은 개발자들이 인공지능 연구에 참여하게 되었습니다.
이 글에서는 기계학습에 대한 간략한 소개와 데이터 분석 시스템을 어떻게 디자인해야 되는지, 마지막으로 파이썬을 이용한 데이터 분석에 대해 소개해드리겠습니다.
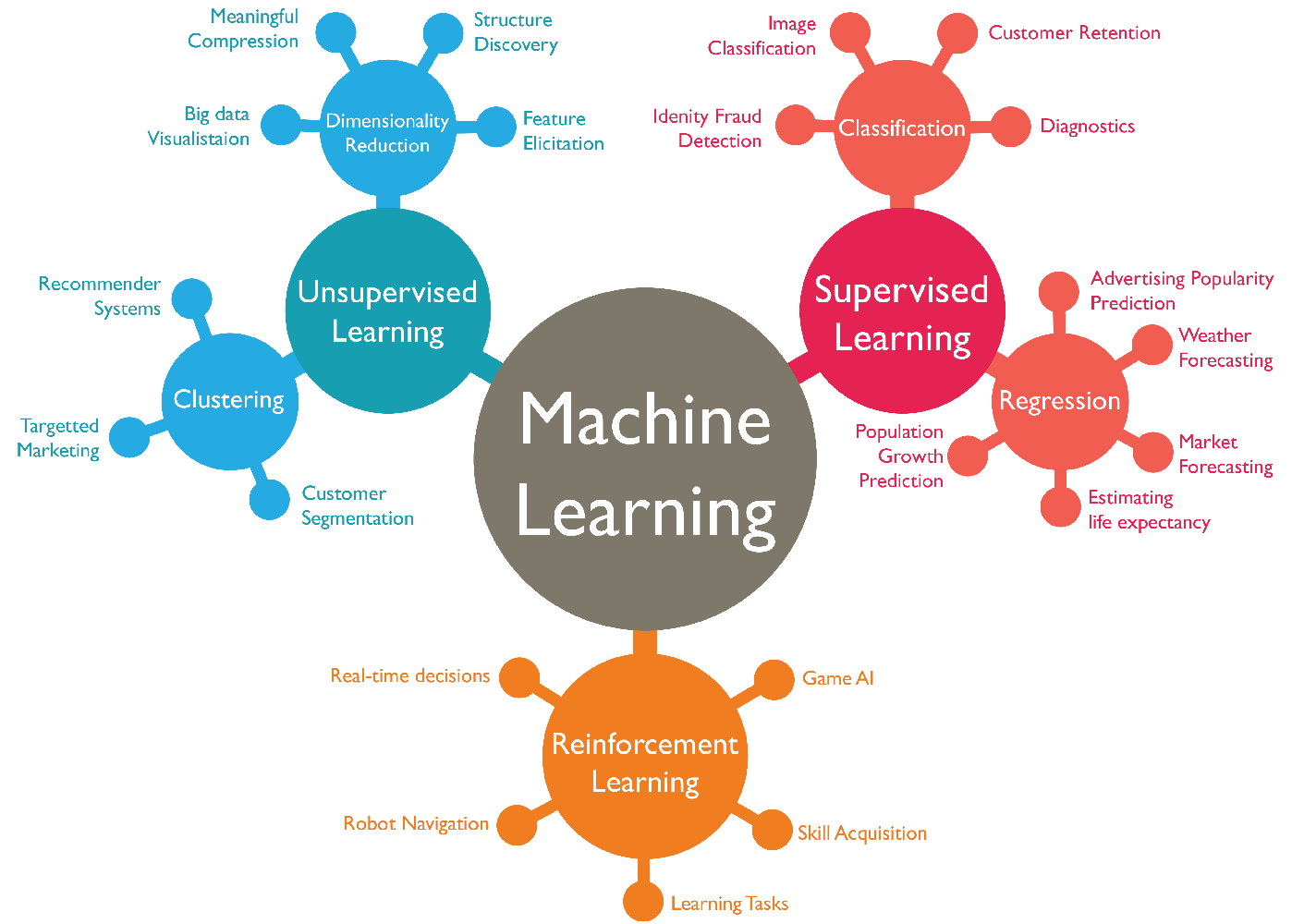
요즘에는 머신러닝을 크게 3가지 분야로 나누어 볼 수 있습니다. 흔히 알고있는 지도학습(Supervised Learning) 과 비지도학습(Unsupervised Learning) 이 있으며, 마지막으로 알파고에 적용되었던 강화학습(Reinforcement Learning) 이 있습니다. 이제 세 가지 다른 알고리즘 간의 근본적인 차이점에 대해 알아보고, 실제로 어떤 문제에 적용되는지 알아보겠습니다.
Supervised Learning
지도학습과 비지도학습의 궁극적인 목표는 모두 과거, 현재의 데이터로부터 미래를 예측하는 것이라 할 수 있습니다. 다만, 두 가지 방법의 차이점은 라벨링 된 데이터인지 아닌지에 따라 결정됩니다.
만일 내가 가지고 있는 데이터가 라벨링 되어 있다면 지도학습이라고 볼 수 있습니다. 여기에서 라벨링 된 데이터(Labeled data)란 데이터에 대한 답이 주어져 있는 것 (평가가 되어 있는 것) 을 말합니다.

Classification
지도학습은 Classification과 Regression으로 나누어집니다. 먼저, Classification은 주어진 데이터를 정해진 카테고리에 따라 분류하는 문제를 말합니다. 최근에 많이 사용되는 이미지 분류도 Classification 문제 중에 하나입니다.
예를 들어, 이메일이 스팸메일인지 아닌지를 예측한다고 하면 이메일은 스팸메일 / 정상적인 메일로 라벨링 될 수 있을 것입니다. 비슷한 예시로 암을 예측한다고 가정했을 때 이 종양이 악성종양인지 / 아닌지로 구분할 수 있습니다. 이처럼 맞다 / 아니다로 구분되는 문제를 Binary Classification 이라고 부릅니다.
분류 문제가 모두 맞다 / 아니다로 구분되지는 않습니다. 예를 들어, 공부시간에 따른 전공 Pass / Fail 을 예측한다고 하면 이는 Binary Classifiaction 으로 볼 수 있습니다. 반면에, 수능 공부시간에 따른 전공 학점을 A / B / C / D / F 으로 예측하는 경우도 있습니다. 이러한 분류를 Multi-label Classification 이라고 합니다.
Regression
다음으로 Regression은 연속된 값을 예측하는 문제를 말합니다. 주로 어떤 패턴이나 트렌드, 경향을 예측할 때 사용됩니다. Coursera에서는 Regression을 설명할 때 항상 집의 크기에 따른 매매가격을 예로 듭니다. 아까와 유사한 예를 들자면, 공부시간에 따른 전공 시험 점수를 예측하는 문제를 예로 들 수 있습니다.
Unsupervised Learning
비지도학습은 앞에서 언급한 것 처럼 라벨링이 되어 있지 않은 데이터로부터 미래를 예측하는 학습방법입니다. 평가되어 있지 않은 데이터로부터 숨어있는 패턴이나 형태를 찾아야 하기 때문에 당연히 더 어렵습니다. 비지도학습도 데이터가 분리되어 있는지 (Categorial data) 연속적인지 (Continuous data)로 나누어 생각할 수 있습니다.
대표적으로 클러스터링 (Clustering) 이 있습니다. 실제로는 그 데이터의 label이나 category가 무엇인지 알 수 없는 경우가 많기 때문에 이러한 방법이 중요하다고 볼 수 있습니다. 이외에도 차원축소(Dimentionality Reduction), Hidden Markov Model 등이 있습니다.
Reinforcement Learning
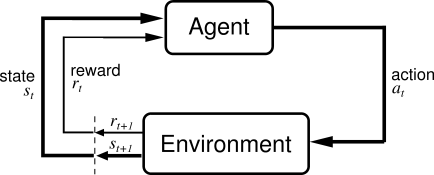
마지막으로 강화학습은 앞서 말했던 학습방법과는 조금 다른 개념입니다. 데이터가 정답이 있는 것도 아니며, 심지어 주어진 데이터가 없을 수도 있습니다. 강화학습이란, 자신이 한 행동에 대한 "보상"을 알 수 있어서 그로부터 학습하는 것을 말합니다.
예를 들면, 아이가 걷는 것을 배우는 것처럼 어떻게 행동할 줄 모르지만 환경과 상호작용하면서 걷는 법을 알아가는 것과 같은 학습 방법을 강화학습이라고 합니다.
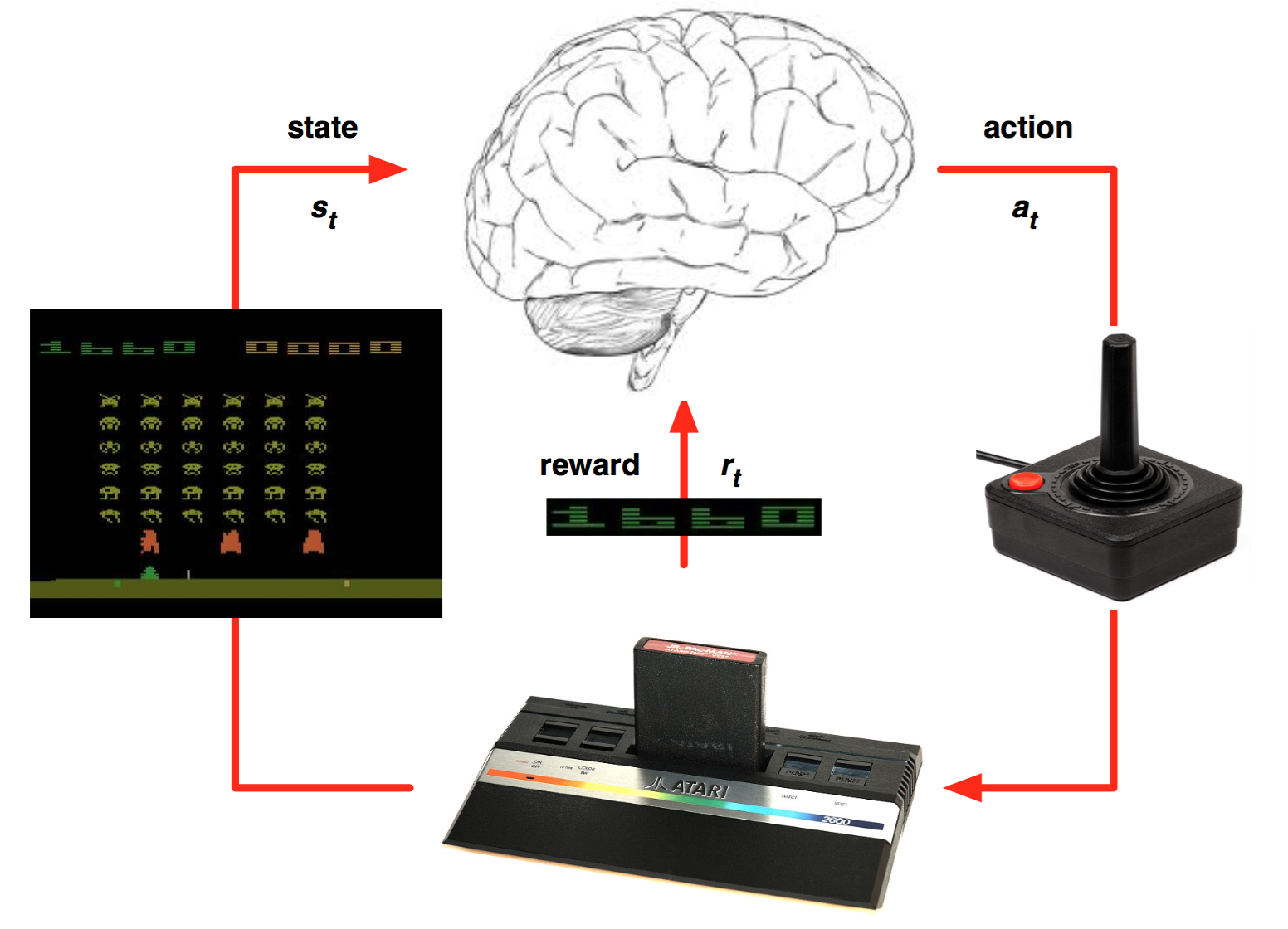
보통 아타리 게임 인공지능을 많이 예시로 드는데, 여기에서 학습 대상 (agent) 은 움직이면서 적을 물리치는 존재입니다. 이 학습 대상은 움직이면서 적을 물리치면 보상 (reward) 을 받게 됩니다. 이러한 과정을 스스로 반복 학습 (Trial and Error) 하면서 점수를 최대화하는 것이 목표입니다.
How?
처음에는 공부를 시작하기에 막막한데 다행히 아주 좋은 강의와 자료들이 많이 있습니다.
Machine Learning / Deep Learning
- Coursera - Andrew Ng : https://www.coursera.org/learn/machine-learning
- 모두의 딥러닝 : https://hunkim.github.io/ml/
- CS231n : http://cs231n.stanford.edu/
Reinforcement Learning
- 모두의 연구소 깃북 : https://dnddnjs.gitbooks.io/rl/content/
- Deep Mind - David Silver : https://www.youtube.com/watch?v=2pWv7GOvuf0