


Raft consensus algorithm
📅 September 01, 2018
•⏱️2 min read
Consensus란 분산 시스템에서 노드 간의 상태를 공유하는 알고리즘을 말합니다. 가장 유명한 알고리즘으로 Paxos가 있고, Zookeeper에서 사용하는 Zab이 있습니다. Raft는 이해하기 어려운 기존의 알고리즘과 달리 쉽게 이해하고 구현하기 위해 설계되었습니다. (PS. 이 글은 블록체인에서의 Consensus 알고리즘을 말하는 것이 아닙니다)
What is consensus problem
하나의 클라이언트와 서버가 있고 클라이언트가 서버에게 데이터를 전달한다고 가정해보겠습니다. 서버는 하나의 노드로 이루어져있기 때문에 합의가 이루어지는건 아주 쉬운 문제입니다. (여기에서 말하는 합의는 공유된 상태라고 이해하시면 됩니다)
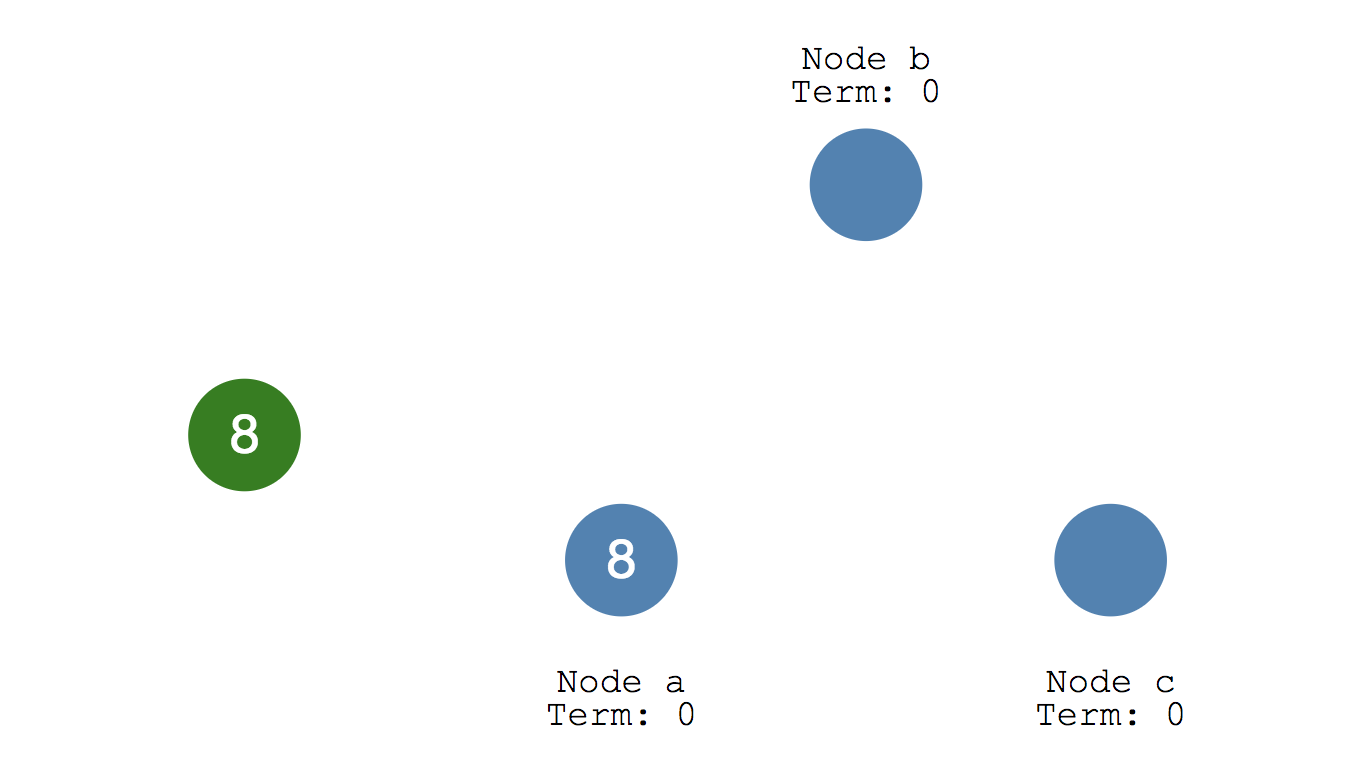
만일 위 그림처럼 여러 노드로 이루어진 분산 서버에서 합의를 이루어내야한다면 어떻게 해야할까요? 이러한 문제를 distributed consensus problem 이라고 합니다.
Raft Algorithm
Raft의 node는 Follower, Candidate, Leader라는 3가지 state를 가집니다. 모든 노드는 처음에 Follower state를 가지고 시작합니다. 만일 Follower가 Leader의 응답을 받지 못하면 Candidate 상태로 전환될 수 있습니다.
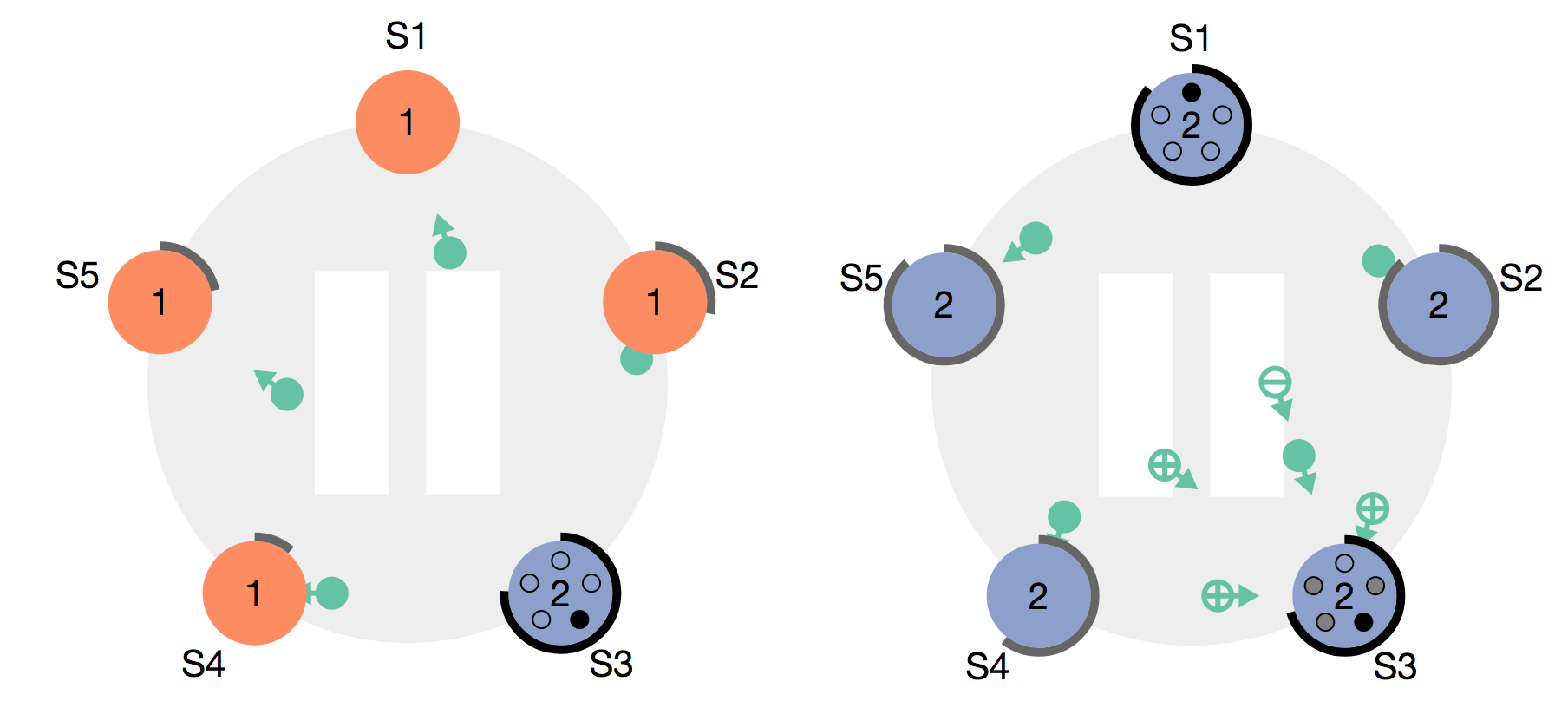
Candidate는 다른 노드들에게 투표를 요청하고 노드들은 투표 결과를 응답으로 전달합니다. 노드 중 가장 많은 표를 얻은 노드는 Leader가 될 수 있습니다. 이러한 프로세스를 Leader Election 이라고 부릅니다.
Leader Election
Raft는 투표를 관리하기 위해 두 가지 timeout 설정을 가지고 있습니다. 첫 번째는 Election timeout 입니다. Election timeout 이란, Follower에서 Candidate로 전환되기 위해 기다리는 시간을 의미합니다. 일반적으로 Election timeout은 150ms에서 300ms 사이의 값으로 랜덤하게 설정됩니다.
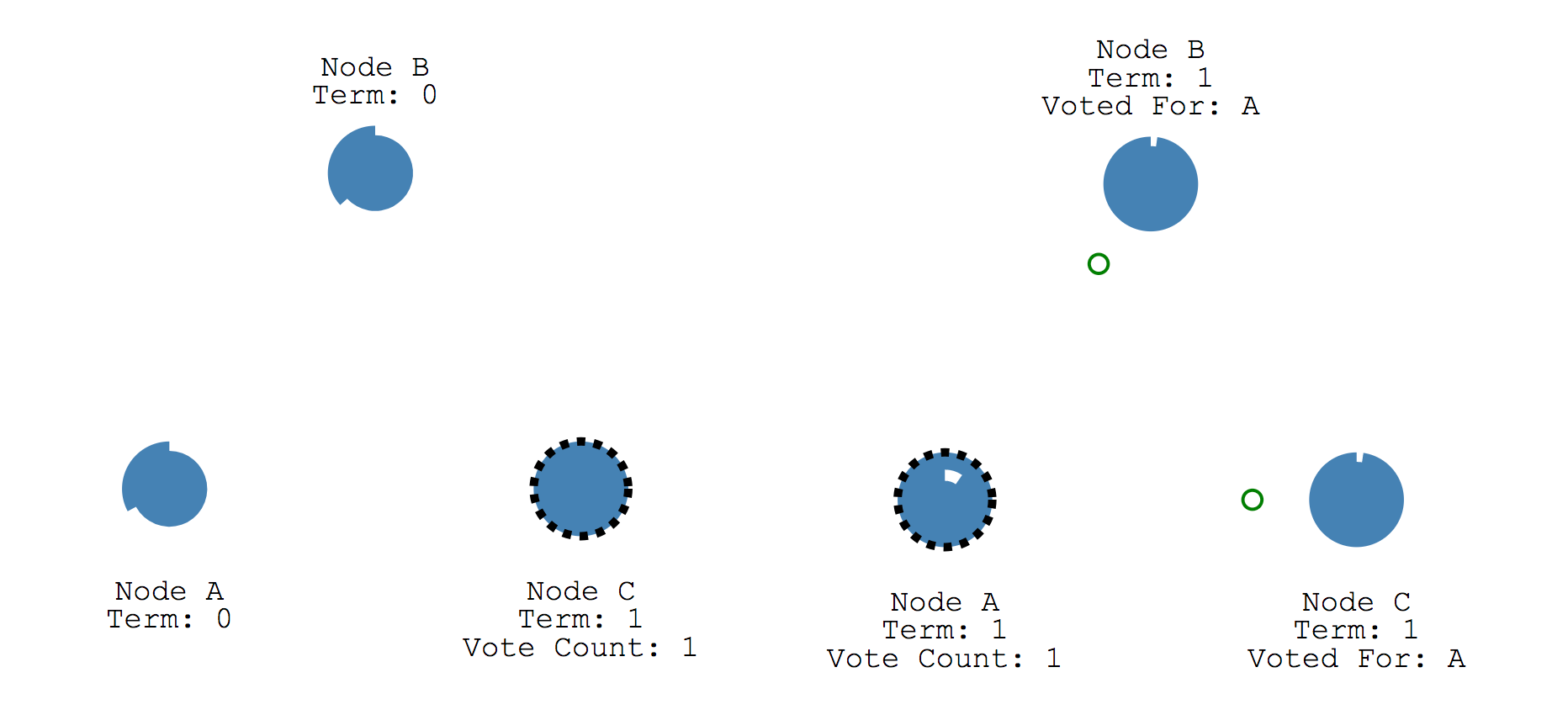
- Election timeout이 끝나면 Follower는 Candidate가 되고 Election term을 시작합니다.
- Candidate는 본인에게 투표를 하고 다른 노드들에게 투표 요청 메세지를 전달합니다.
- 만일 메세지를 받는 노드가 해당 Election term에서 아직 투표를 하지 않았다면, 먼저 메세지를 전달해준 Candidate에게 투표합니다.
- 투표를 마친 해당 노드는 Election timeout이 초기화 됩니다.
- 가장 많은 표를 받은 노드가 Leader로 선정됩니다.
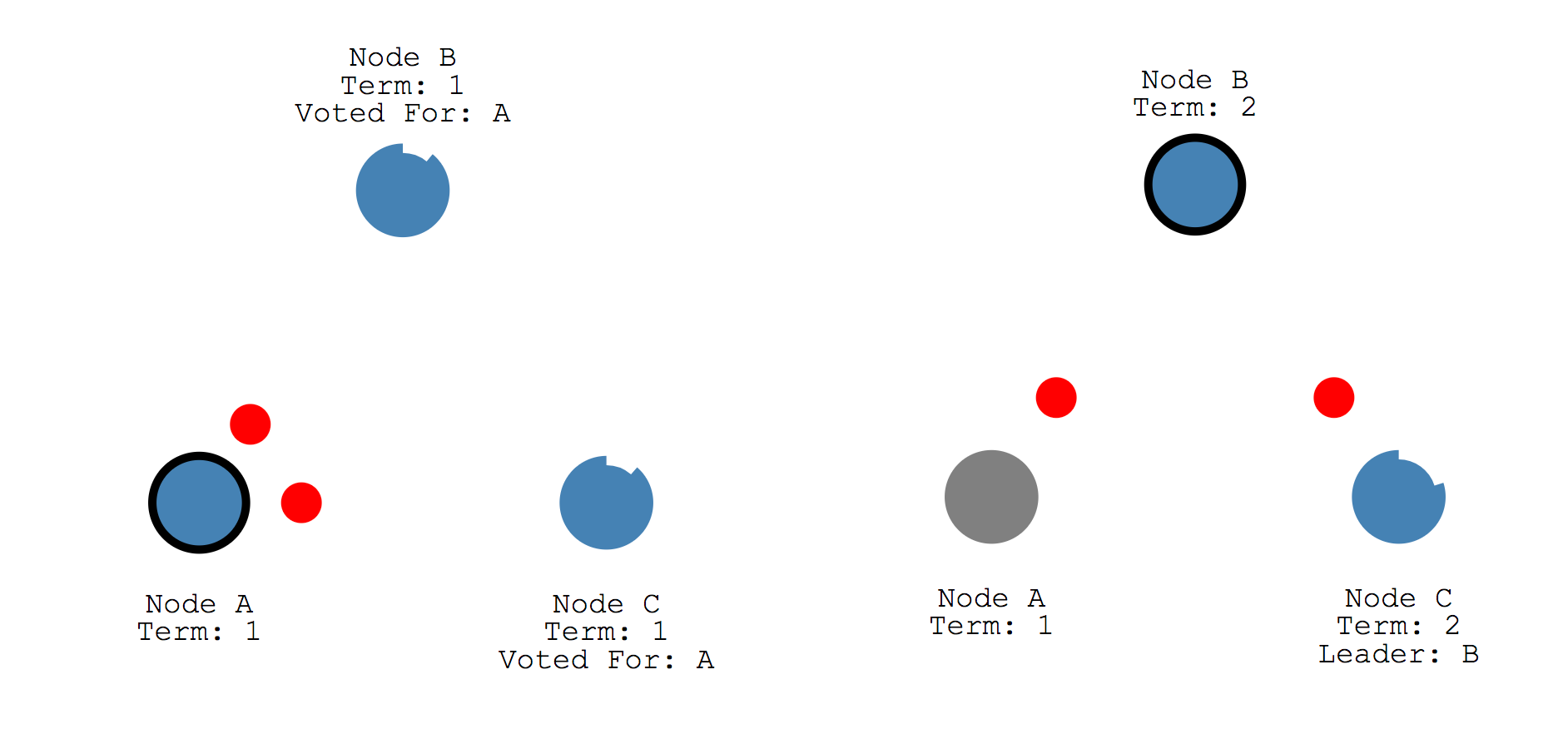
- 선정 이후 Leader는 Append Entries 메세지를 Follower들에게 전송합니다.
(이 메세지는 Heartbeat timeout 에 설정된 간격마다 보내게 됩니다) 2. Follower들은 Append Entries 메세지를 받으면 Election timeout이 초기화되고 메세지에 대한 응답을 Leader에게 보냅니다. 3. 만일 Follower에게 Heartbeat가 도달하지 않으면 다시 Election term이 시작되고, Follower는 Candidate 상태로 전환됩니다. (위 그림은 노드A가 죽고 난 이후 노드B가 Leader로 선정되고 Heartbeat 메세지를 전달하는 예시입니다)
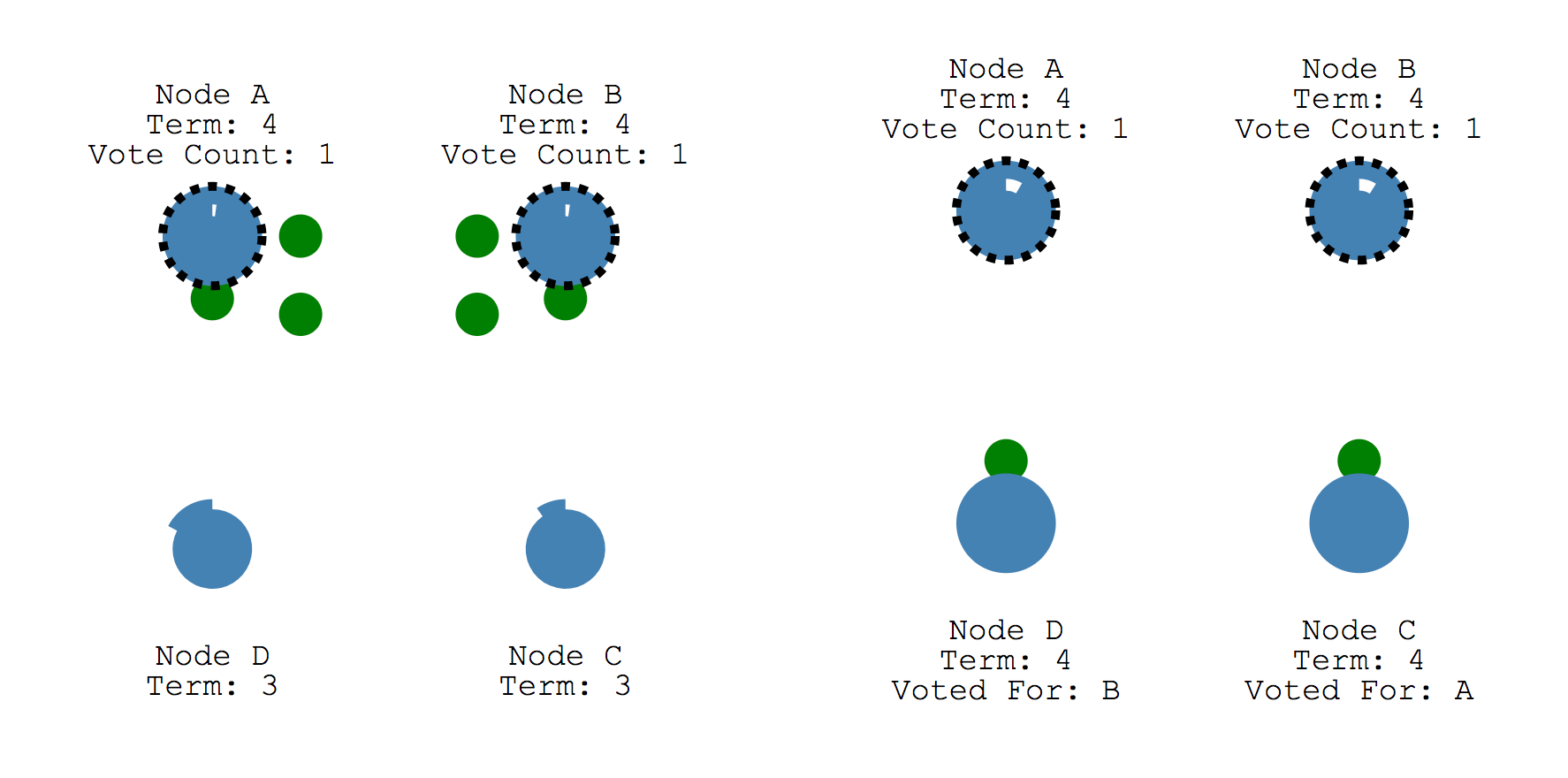
- 만일 두 개의 노드가 동시에 Election term을 시작하고 메세지가 동시에 Follower에게 도달한다고 가정해보겠습니다.
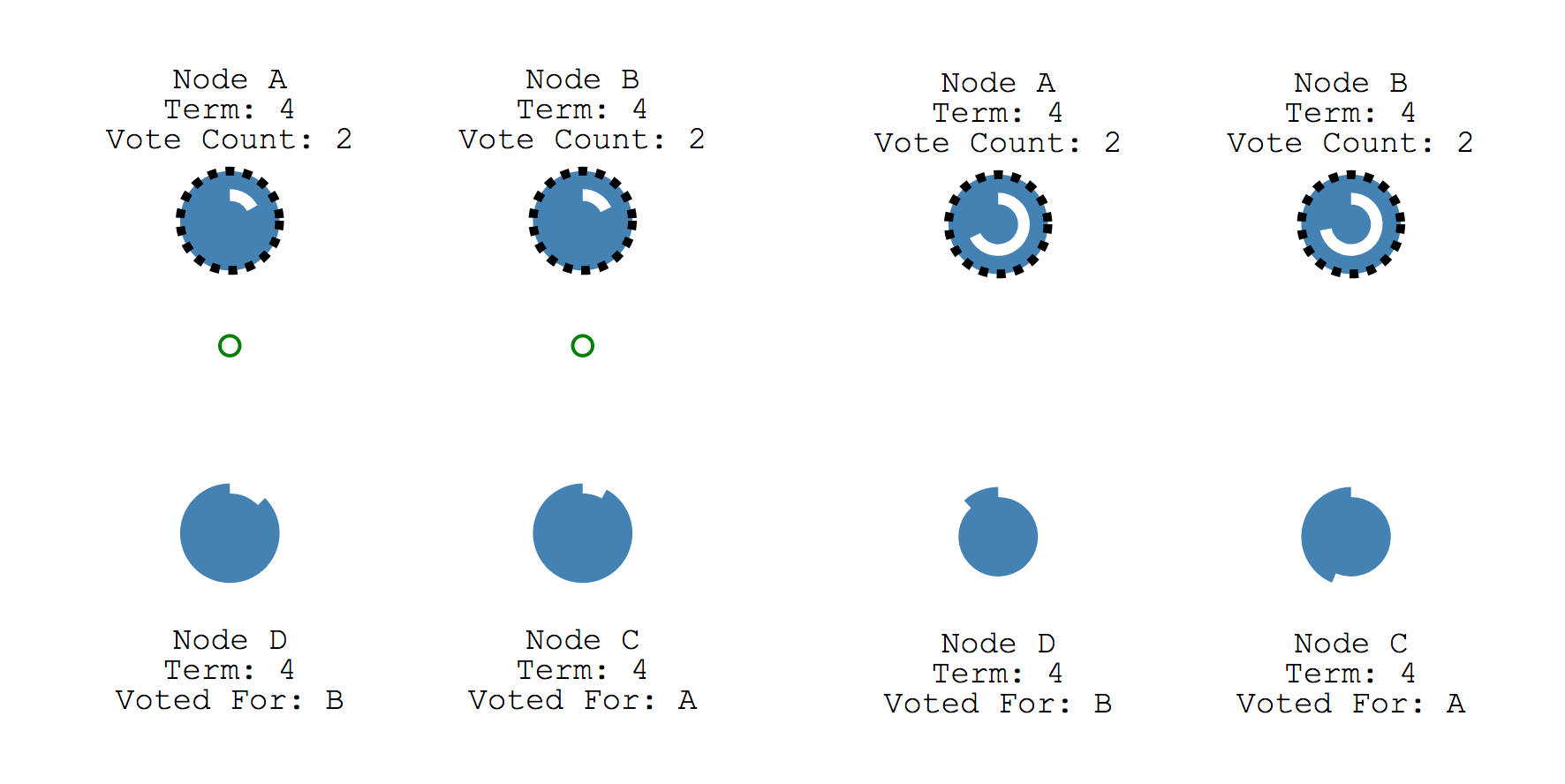
- 이러한 경우 노드A, 노드B는 2표씩 얻게 되고, 표가 동일하므로 해당 Election term에는 Leader가 선정되지 않습니다.
- Leader가 선정되지 않았으므로 Election timeout에 따라 새로운 Election term을 시작하게 됩니다.
Log Replication
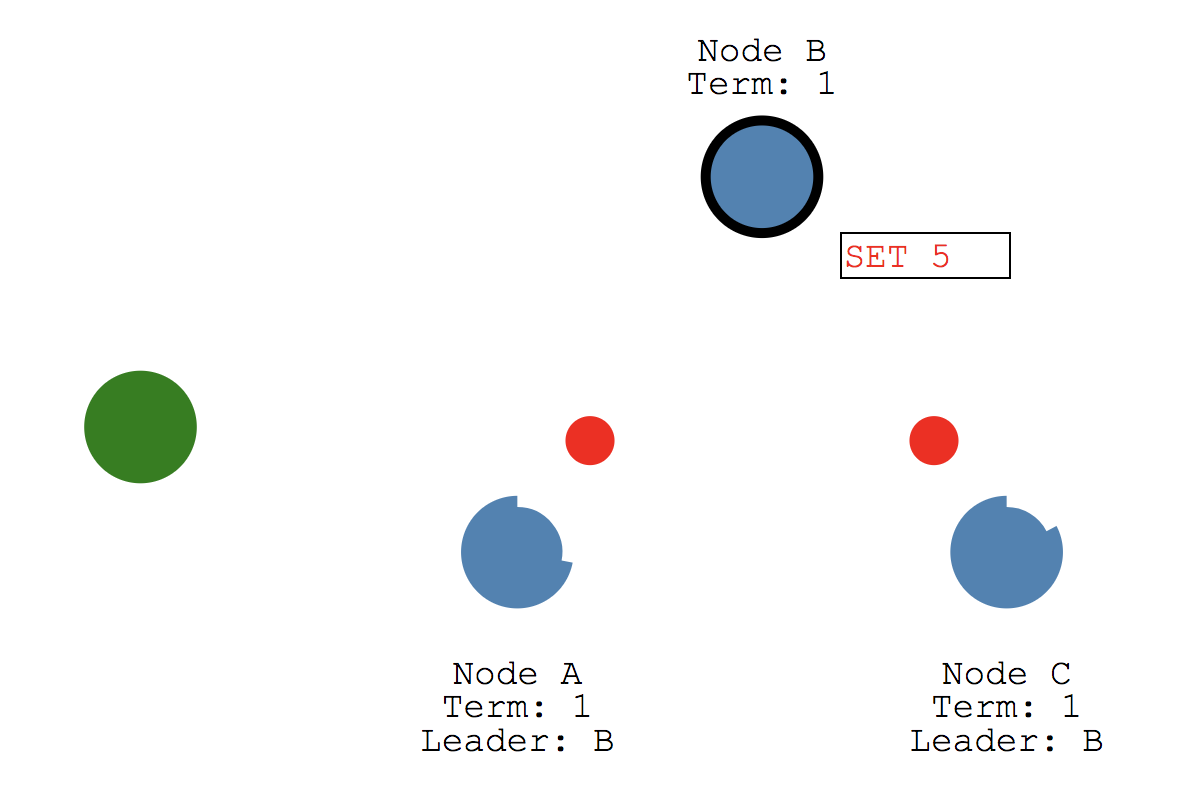
Leader가 선정되고 난 이후, 시스템의 모든 변화는 Leader를 통해 이루어집니다. 클라이언트는 Leader에게 데이터를 전달하고, Leader는 데이터의 복제하여 Follower에게 전달합니다. 이 과정은 앞서 언급했던 Append Entries 메세지를 통해 이루어집니다.
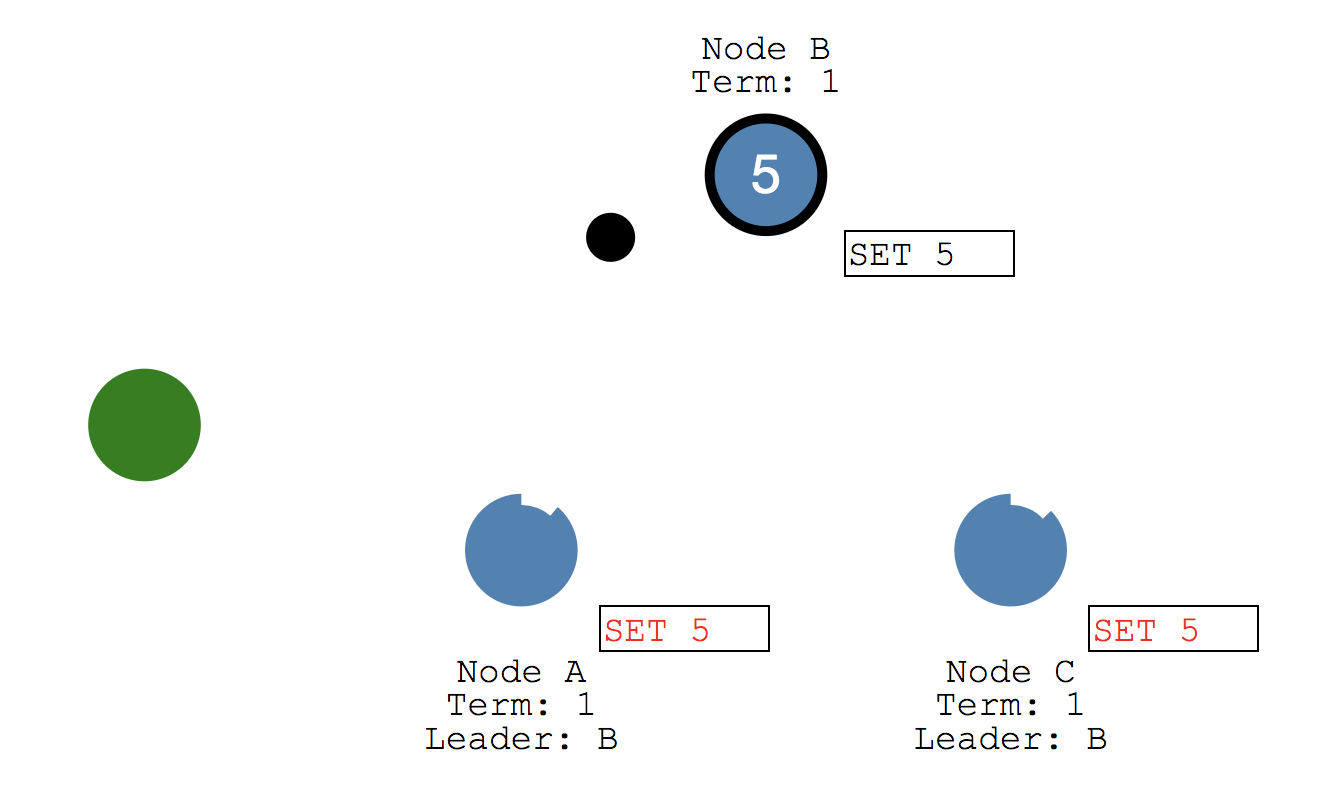
Follower는 받은 데이터를 commit 하고 결과를 Leader에게 전달합니다. Leader는 Follow로부터 받은 결과를 Client에게 전달합니다.
Reference
정리하자면 분산 시스템은 fault-tolerence를 보장하기 위해 consensus algorithm을 사용하고 있고, 분산 시스템을 다루는 프레임워크마다 Consensus 구현이 조금씩 다를 수 있습니다. 그리고 원활한 Leader Election을 위해 클러스터 노드의 개수는 홀수로 구성하는 것이 좋습니다.
Raft의 경우 Redis cluster에서 응용하여 사용하고 있고, Elasticsearch cluster 또한 quorum-based consensus algorithm을 사용하고 있습니다. 아래의 Raft 논문과 시각화 자료 링크를 보시면 더 쉽게 이해할 수 있습니다.