


Airflow worker에 KEDA AutoScaler 적용한 후기
📅 June 24, 2022
•⏱️4 min read
Airflow에서 실행되는 배치 작업들은 특정 시간 또는 야간에 많이 수행되고 이외의 시간은 상대적으로 여유로운 경우가 많습니다. 이러한 상황에서 오토스케일링을 적용한다면 효율적으로 리소스를 최적화하여 사용할 수 있습니다.
만약 쿠버네티스 위에서 Celery Executor를 사용한다면 worker의 오토스케일링을 위해 KEDA를 고려해볼 수 있습니다. 이 글에서는 Airflow worker에 KEDA AutoScaler를 적용하면서 겪었던 여러 문제들과 해결 과정에 대해 정리해보려 합니다.
KEDA AutoScaler
KEDA는 쿠버네티스에서 이벤트 기반 오토스케일링을 쉽게 구현할 수 있도록 지원하는 컴포넌트입니다. 쿠버네티스의 HPA와 함께 동작하며 다양한 built-in scaler를 통해 유연하게 오토스케일링 조건을 설정할 수 있습니다.
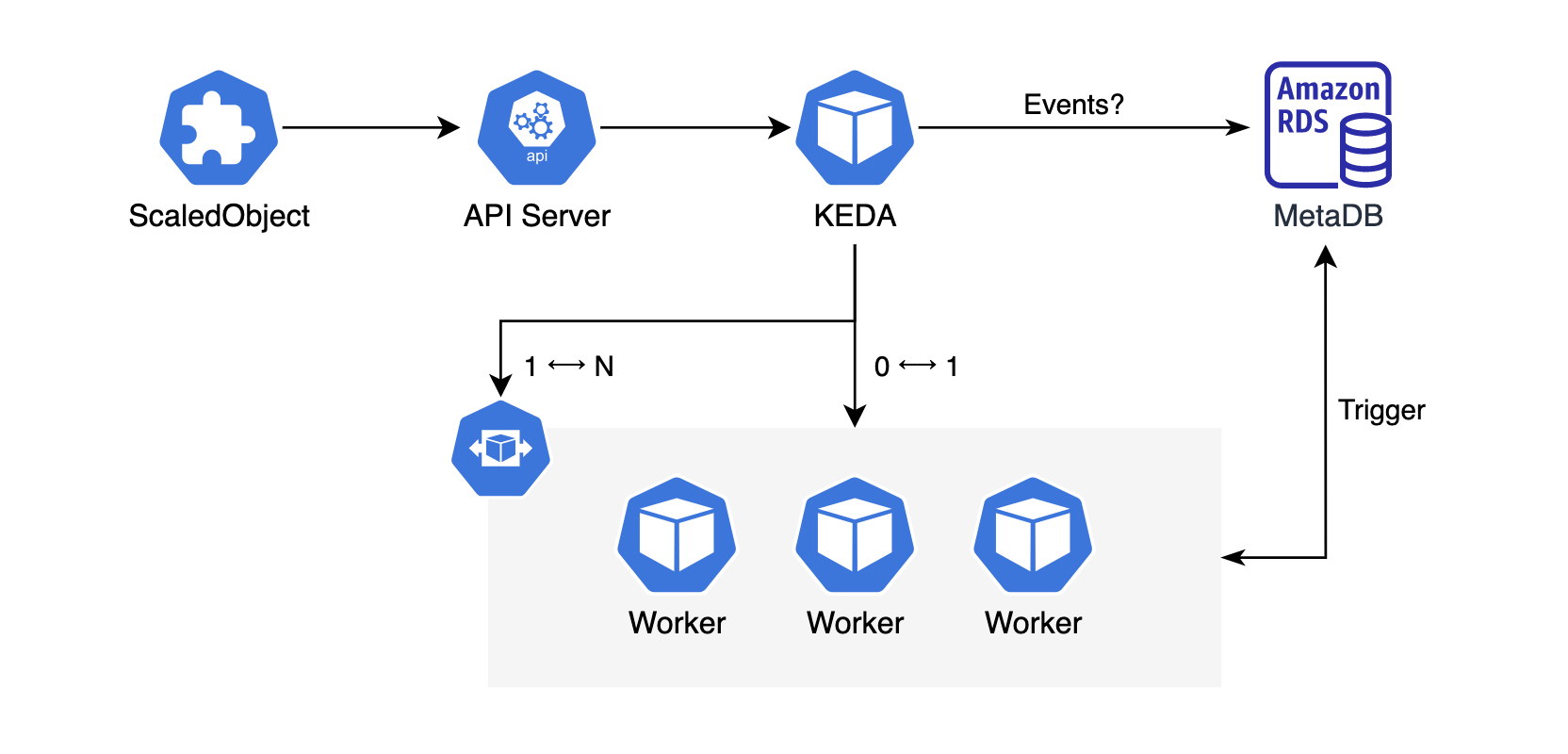
만약 Airflow에 적용한다면 위의 그림과 같은 형태로 구성됩니다.
사용자는 KEDA의 ScaledObject CRD를 생성하여 클러스터에 배포합니다.
KEDA는 쿠버네티스의 API Server와 통신하며 Operator와 같은 형태로써 컨트롤 루프에 따라 동작합니다.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: airflow-worker
spec:
scaleTargetRef:
name: airflow-worker
pollingInterval: 10
cooldownPeriod: 30
minReplicaCount: 3
maxReplicaCount: 10
triggers:
- type: postgresql
metadata:
connectionFromEnv: AIRFLOW_CONN_AIRFLOW_DB
query: ""ScaledObject는 위와 같이 무엇을 기준으로 트리거할지, 스케일링 정책 등을 정의할 수 있습니다. KEDA는 minReplicaCount에 따라 다르게 동작하는데 minReplicaCount가 0인 경우, KEDA가 trigger 지표를 통해 직접 처리하지만 1 이상인 경우에는 KEDA가 Metrics Server에 전달만하고 HPA를 통해 처리됩니다. 각 옵션에 대한 자세한 설명은 공식 문서에서 확인할 수 있습니다.
SELECT ceil(COUNT(*)::decimal / {{ celery.worker_concurrency }})
FROM task_instance
WHERE state='running' OR state='queued'Airflow에서 사용하는 ScaledObject의 트리거 쿼리는 위와 같이celery.worker_concurrency 설정을 기준으로 하고 있습니다. 예를 들어 concurrency 설정이 12이며 running 또는 queued 상태의 task instance가 10에서 23으로 증가한 상황이라고 가정해보겠습니다. desired state가 1에서 2로 변경되었기 때문에 deployment의 replica 수는 2로 확장 됩니다. 스케줄이 모두 종료된 이후 다시 task instance가 10으로 줄어들면 replica 수는 1로 축소 됩니다.
Airflow 공식 차트에서는 KEDA 관련 옵션을 지원하고 있기 때문에 공식 문서를 통해 쉽게 적용할 수 있습니다.
하지만 문제는 적용한 이후에 발생했습니다.
적용 후에 발생한 문제
적용 후에 실행 중인 task의 로그가 갑자기 끊기면서 강제로 실패 처리되는 문제가 있었습니다.
시간을 보니 worker가 Scale-In 되는 시점에 발생했고 크게 두 가지 문제를 확인할 수 있었습니다.
1. HPA의 replica flapping 문제
먼저 의도한 것보다 Scale-In/Out이 너무 빈번하게 발생했습니다. 새로 노드가 뜨는데 시간이 소요되므로 배치가 많은 시간 대에도 잦은 스케일 조정이 발생하는 것은 비효율적입니다. 이러한 문제를 HPA에서는 replica flapping 이라고 말합니다. HPA는 이를 제어하기 위해 안정화 윈도우와 스케일링 정책을 지원하고 있습니다.
behavior:
scaleDown:
stabilizationWindowSeconds: 600위와 같이 stabilizationWindowSeconds 설정을 600으로 설정하면 이전 10분 동안의 모든 목표 상태를 고려해서 가장 높은 값으로 설정합니다. 현재 시점에 scaleDown 조건을 만족하더라도 즉시 수행되는게 아니라 10분이 지난 시점에 scaleDown이 수행됩니다. 이를 통해 잦은 스케일 조정을 제한할 수 있습니다.
behavior:
scaleDown:
policies:
- type: Pods
value: 1
periodSeconds: 300scaleDown.polices를 통해 Scale-In 발생 시 replica 변경 허용에 대한 정책을 지정할 수 있습니다. 위의 예시는 5분 내에 최대 1개의 replica를 scaleDown 하도록 허용하는 정책입니다. 이를 통해 계단식으로 천천히 pod를 축소할 수 있습니다.
현재 Airflow 공식 차트에서는 KEDA의 advanced 옵션을 지원하지 않아 PR을 추가했습니다.
차트 1.7 버전부터 사용하실 수 있습니다.
2. Worker Warm Shutdown 문제
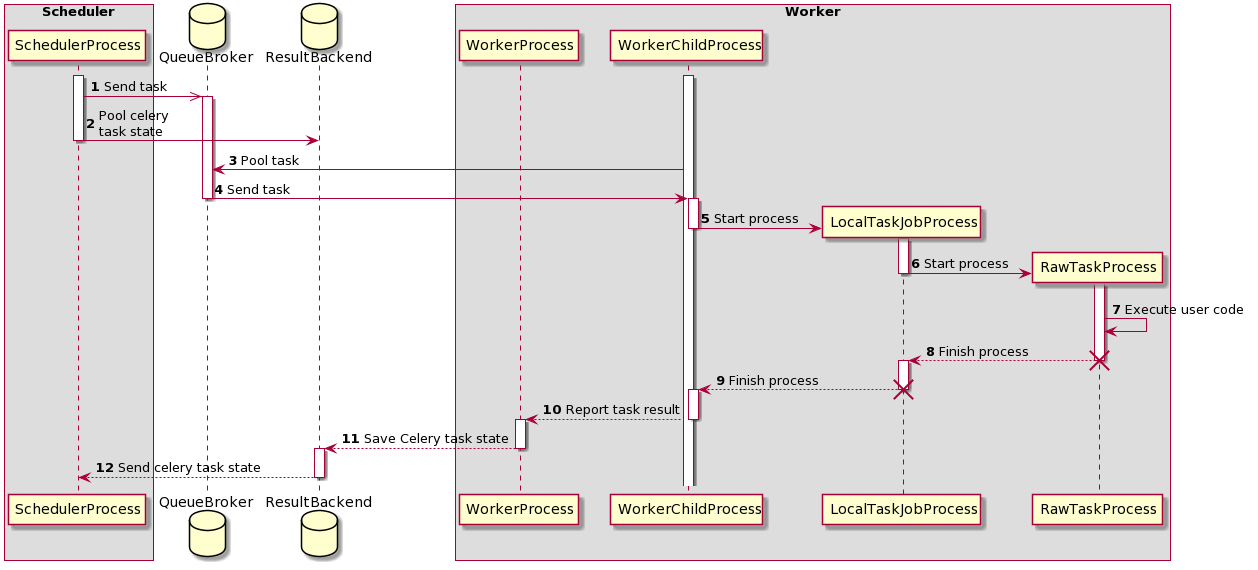
celery worker의 warm shutdown이 제대로 이루어지지 않았기 때문에 task의 로그가 갑자기 끊기면서 강제로 실패 했습니다. Airflow의 CeleryExecutor는 위와 같이 여러 프로세스를 통해 수행됩니다. 이 때 실제로 task를 실행하는 프로세스는 main 프로세스가 아니라 subprocess 입니다. celery에서는 실행 중인 task가 처리된 이후에 종료할 수 있도록 warm shutdown을 지원하고 있습니다. worker의 main process가 SIGTERM을 받으면 task가 종료될때까지 기다리게 됩니다.
# warm shutdown log
worker: Warm shutdown (MainProcess)
-------------- celery@fcd56490a11f v4.4.7 (cliffs)
--- ***** -----
-- ******* ---- Linux-5.4.0-1045-aws-x86_64-with-debian-10.8
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: airflow.executors.celery_executor:0x7f95
- ** ---------- .> transport: redis://redis:6379/0
- ** ---------- .> results: postgresql://airflow:**@postgres/airflow
- *** --- * --- .> concurrency: 16 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> default exchange=default(direct) key=default
[tasks]
. airflow.executors.celery_executor.execute_command이전 글에서 설명한 것처럼 Airflow 공식 차트에서 worker pod은 DUMB_INIT_SETSID=0으로 이미 설정되어 있기 때문에 메인 프로세스에만 SIGNAL이 전파되고 task process는 계속 실행됩니다. 하지만
scaleDown이 발생한다면, 실행 중이던 worker pod이 종료되기 때문에 pod 내에 있던 task process도 함께 강제 종료되면서 task가 실패하게 됩니다. 장시간 수행되는 task 일수록 이러한 문제를 마주칠 가능성이 높습니다.
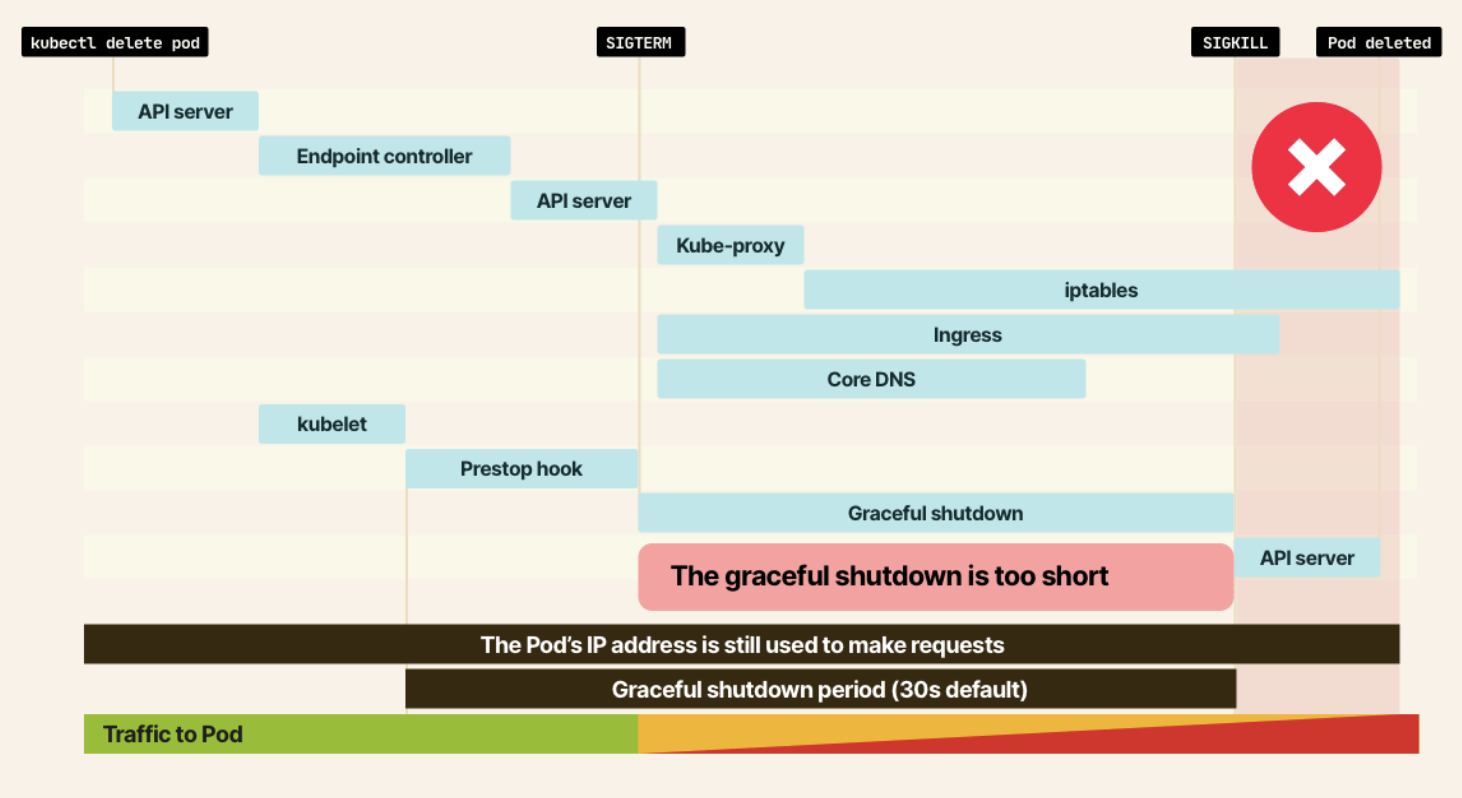
이를 해결하기 위해 task의 execution_timeout 시간까지 pod가 종료되지 않도록 terminationGracePeriodSeconds를 지정해주었습니다. 이제 각 컨테이너 내부의 프로세스 1에 SIGTERM이 전달되더라도 pod의 graceful shutdown 시간 동안 대기하므로 task process는 계속 실행됩니다. 시간이 모두 지나면 SIGKILL을 통해 모든 프로세스가 종료되고 pod도 삭제됩니다.
적용 후기
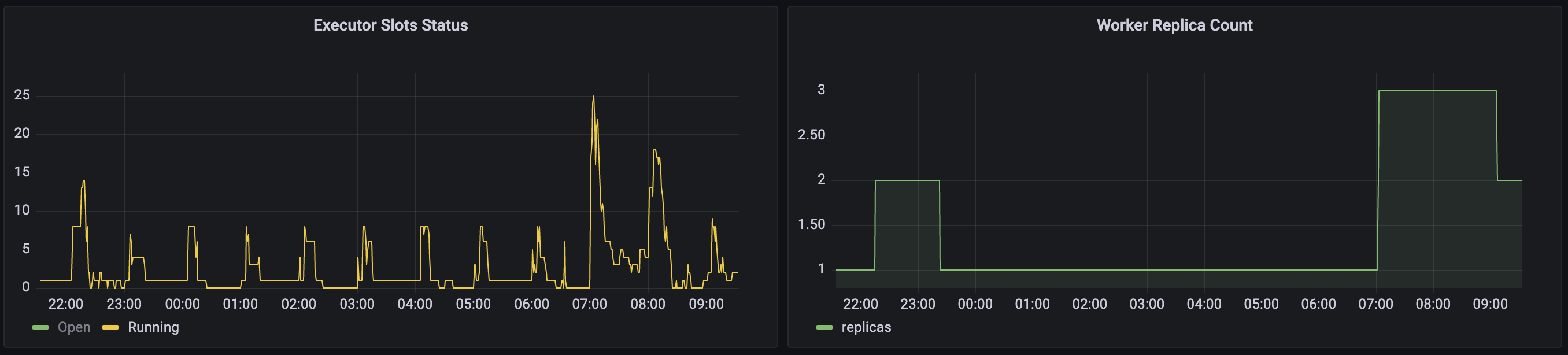
위의 문제들을 모두 수정한 이후부터 안정적으로 worker의 확장, 축소가 이루어졌습니다.
위 그림과 같이 개발 환경에 동시성 테스트를 위한 DAG을 먼저 만들어서 slot 지표에 따라 replica count가 어떻게 변화하는지 확인해본다면 안정적으로 적용할 수 있습니다.