


DecisionTree와 RandomForest에 대하여
📅 February 10, 2017
•⏱️3 min read
의사결정트리 (DecisionTree)
의사결정나무는 다양한 의사결정 경로와 결과를 나타내는데 트리 구조를 사용합니다. 보통 어렸을 때의 스무고개 놀이를 예로 드는 경우가 많습니다.
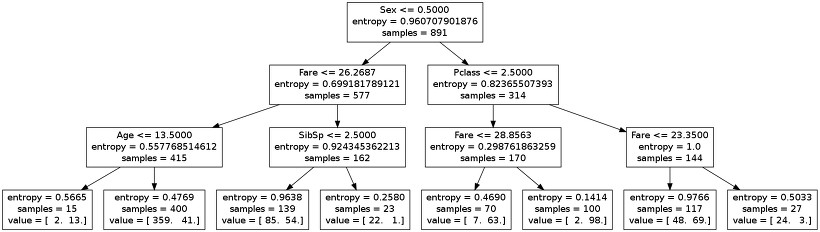
위의 그림은 타이타닉 생존자를 찾는 의사결정트리 모델입니다. 첫번째 뿌리 노드를 보면 성별 <= 0.5 라고 되어있는데 이는 남자냐? 여자냐? 라고 질문하는 것과 같습니다.
최종적으로, 모든 승객에 대한 분류(Classification)를 통해 생존확률을 예측할 수 있게 됩니다.
이처럼, 숫자형 결과를 반환하는 것을 회귀나무(Regression Tree) 라고 하며, 범주형 결과를 반환하는 것을 분류나무(Classification Tree) 라고 합니다. 의사결정트리를 만들기 위해서는 먼저 어떤 질문을 할 것인지, 어떤 순서로 질문을 할 것인지 정해야 합니다.
가장 좋은 방법은 예측하려는 대상에 대해 가장 많은 정보를 담고 있는 질문을 고르는 것이 좋습니다. 이러한 '얼마만큼의 정보를 담고 있는가'를 엔트로피(entropy) 라고 합니다. 엔트로피는 보통 데이터의 불확실성(?)을 나타내며, 결국 엔트로피가 클 수록 데이터 정보가 잘 분포되어 있기 때문에 좋은 지표라고 예상할 수 있습니다.
그림과 같이 의사결정트리는 이해하고 해석하기 쉽다는 장점이 있습니다. 또한 예측할 때 사용하는 프로세스가 명백하며, 숫자형 / 범주형 데이터를 동시에 다룰 수 있습니다. 그리고 특정 변수의 값이 누락되어도 사용할 수 있습니다.
하지만 최적의 의사결정트리를 찾는 것이 정말 어려운 문제입니다. (어떤 것들을 조건(Feature)으로 넣어야 할지, 깊이(Depth)는 얼마로 정해야 할지…) 그리고 의사결정트리의 단점은 새로운 데이터에 대한 일반화 성능이 좋지 않게 오버피팅(Overfitting)되기 쉽다는 것입니다.
잠깐 오버피팅에 대해 설명하자면, 오버피팅이란 Supervised Learning에서 과거의 학습한 데이터에 대해서는 잘 예측하지만 새로 들어온 데이터에 대해서 성능이 떨어지는 경우를 말합니다. 즉, 학습 데이터에 지나치게 최적화되어 일반화가 어렵다는 말입니다. 이러한 오버피팅을 방지할 수 있는 대표적인 방법 중 하나가 바로 앙상블 기법을 적용한 랜덤포레스트(Random Forest) 입니다.
랜덤포레스트 (RandomForest)
랜덤포레스트는 위에서 말한 것과 같이 의사결정트리를 이용해 만들어진 알고리즘입니다.
랜덤포레스트는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로,
훈련 과정에서 구성한 다수의 결정 트리로부터 분류 또는 평균 예측치를 출력함으로써 동작한다.
즉, 랜덤포레스트란 여러 개의 의사결정트리를 만들고, 투표를 시켜 다수결로 결과를 결정하는 방법입니다.
위의 그림은 고작 몇 십개의 트리노드가 있지만 실제로는 수 백개에서 수 만개까지 노드가 생성될 수 있습니다. 이렇게 여러 개의 트리를 통해 투표를 해서 오버피팅이 생길 경우에 대비할 수 있습니다.
그런데 보통 구축한 트리에는 랜덤성이 없는데 어떻게하면 랜덤하게 트리를 얻을 수 있나? 라는 의문이 듭니다. 랜덤포레스트에서는 데이터를 bootstrap 해서 포레스트를 구성합니다.
bootstrap aggregating 또는 begging 이라고 하는데, 전체 데이터를 전부 이용해서 학습시키는 것이 아니라 샘플의 결과물을 각 트리의 입력 값으로 넣어 학습하는 방식입니다. 이렇게 하면 각 트리가 서로 다른 데이터로 구축되기 때문에 랜덤성이 생기게 됩니다. 그리고 파티션을 나눌 때 변수에 랜덤성을 부여합니다. 즉, 남아있는 모든 변수 중에서 최적의 변수를 선택하는 것이 아니라 변수 중 일부만 선택하고 그 일부 중에서 최적의 변수를 선택하는 것입니다.
이러한 방식을 앙상블 기법(ensemble learning) 이라고 합니다. 랜덤포레스트는 아주 인기가 많고 자주 사용되는 알고리즘 중 하나입니다. 샘플링되지 않은 데이터를 테스트 데이터로 이용할 수 있기 때문에 데이터 전체를 학습에 사용할 수 있으며, 의사결정트리에 비해 일반화도 적용될 수 있습니다.
하지만 실제로 테스트 해보면 꼭 모든 경우에 뛰어나다고 할 수는 없습니다. (예를 들면 데이터 셋이 비교적 적은 경우)
실제로 사용해보자
이렇게 이론을 공부하고 나면 실제로 적용해보는 예측모델을 만들고 싶어집니다. 정말 고맙게도 파이썬의 scikit-learn에 다양한 트리 모델이 구현되어 있습니다. 다른 앙상블 모델 뿐만 아니라 RandomForest까지 제공합니다.
공식 레퍼런스는 아래의 링크를 참조
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
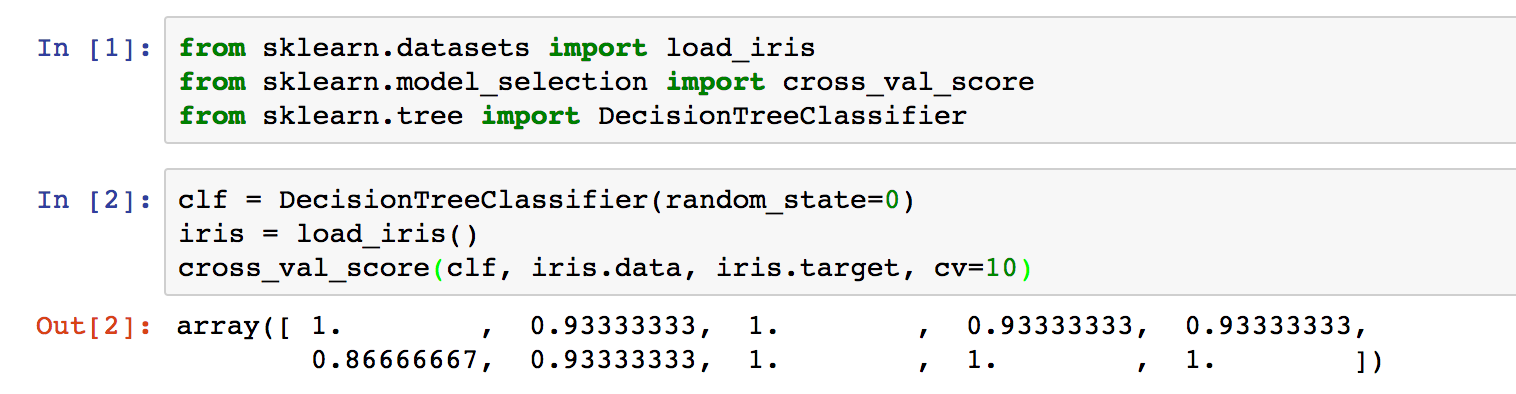
방법은 간단합니다. sklearn.tree에 있는 model 을 import 합니다. skikit-learn의 모델들은 대부분 파라메터로 X, y 값을 넣는다는 공통점이 있습니다. 여기서 X는 input 또는 feature가 되고, y는 output이 됩니다.

model.fit(X, y)를 하면 모델에 대한 정보가 출력됩니다. 최초에 모델을 로드할 때 random_state 값만 조정했기 때문에 전부 다 default 값이 적용된 걸 볼 수 있습니다.
RandomForest나 DecisionTree 같은 경우에는 max_depth, n_estimator에 따라 결과 값이 달라집니다. 데이터에 따라 다르지만, 보통 100-150 사이의 값 중에 성능이 가장 잘 나오는 값으로 결정합니다.
Kaggle Titanic에 적용한 스크립트는 아래의 링크를 참조하시면 됩니다.
https://github.com/Swalloow/Kaggle/blob/master/Titanic%20Survivors/Titanic%20Tree%20Modeling.ipynb