


EKS Karpenter를 활용한 Groupless AutoScaling
📅 May 13, 2022
•⏱️5 min read
21년 12월 EKS에서 새로운 쿠버네티스 클러스터 오토스케일러인 Karpenter를 발표했습니다.
이후로 많은 사용자들이 오픈소스에 참여하면서 버전도 많이 올라갔고 안정적으로 사용하고 있습니다. 이 글에서는 Karpenter와 기존에 사용하던 Cluster AutoScaler를 비교하고 이관할 때 알아두면 좋은 내용에 대해 정리해보려 합니다.
Cluster AutoScaler가 가진 한계점
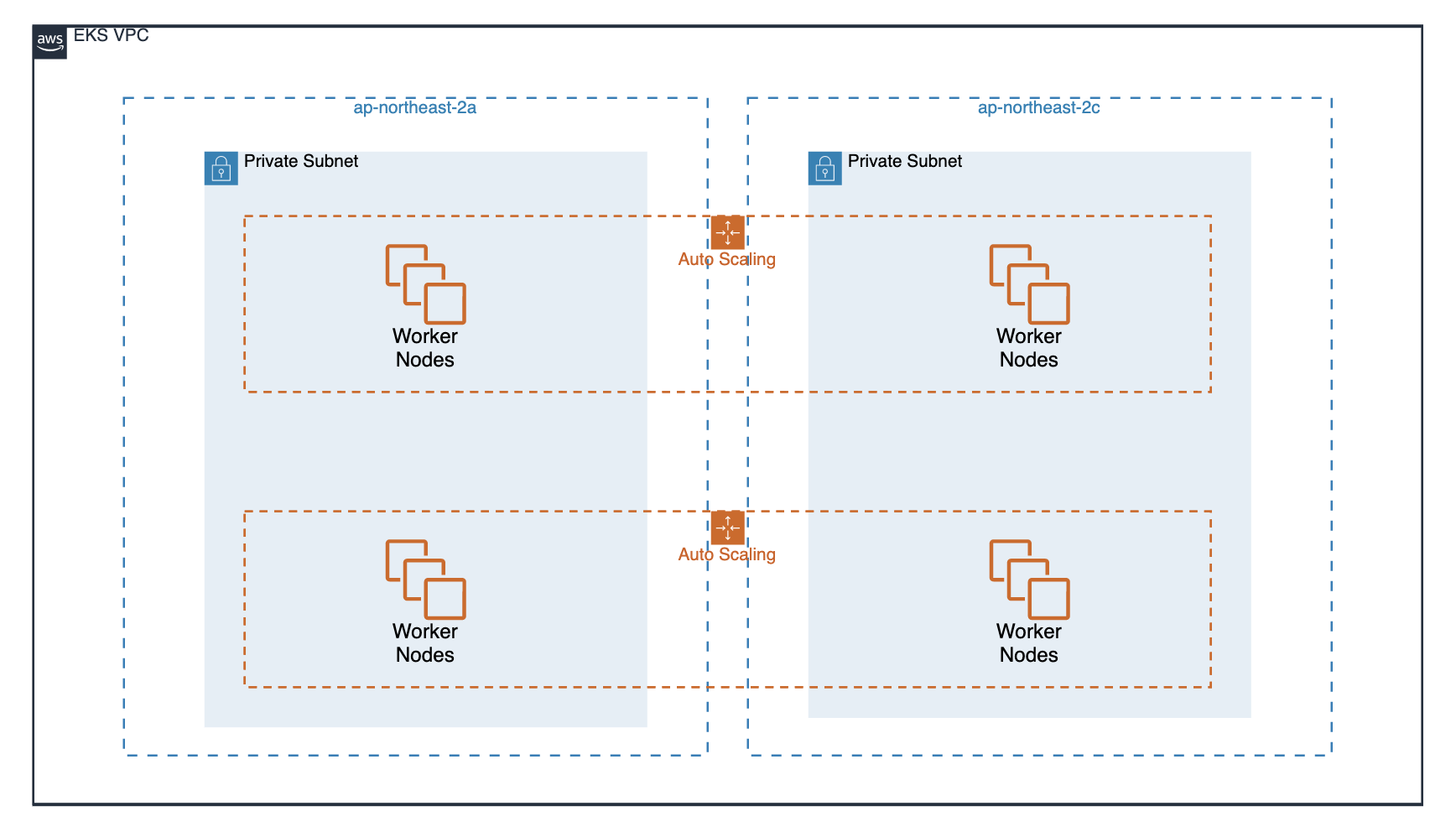
그 동안 EKS의 Cluster AutoScaler는 AWS의 AutoScaling Group(ASG) 을 활용하고 있었습니다. ASG는 주기적으로 현재 상태를 확인하고 Desired State로 변화하는 방식으로 동작합니다. 사용자는 목적에 맞게 노드 그룹을 나누고 ASG의 Min, Max 설정을 통해 클러스터 노드 수를 제한할 수 있습니다. 이를 통해 기존 AWS 사용자가 직관적인 구조를 그대로 활용할 수 있었습니다. 하지만 클러스터의 규모가 커질수록 ASG 활용으로 인해 불편한 점이 존재했습니다.
1. 번거로운 ASG 노드 그룹 관리
K8S 클러스터는 여러 조직이 함께 사용할 수 있는 멀티테넌트 구조를 지원합니다. 두 조직이 서비스의 안정적인 운영을 위해 노드 그룹을 격리해야 하는 요구사항이 생기면 EKS 운영자는 새로운 ASG 노드 그룹을 생성하고 관리해주어야 합니다. 많은 운영자가 EKS의 IaC 구현을 위해 terraform-aws-eks 모듈을 사용하는데 여기에 매번 설정을 업데이트하고 반영하는 일은 번거롭고 각 조직에게 역할을 위임하기도 애매합니다.
또 다른 예시는 리소스 활용 목적에 따라 노드 그룹을 분리할 때 입니다. 많은 CPU가 필요한 워크로드는 컴퓨팅 최적화 인스턴스 유형을 사용하고 메모리가 필요한 워크로드는 메모리 최적화 인스턴스 유형을 사용하는 것이 효율적입니다. 그리고 비용 최적화를 위해 spot 인스턴스 유형을 사용할 수도 있습니다. 이를 구현하기 위해 ASG에서는 c타입, r타입, spot 인스턴스를 가지는 각 노드 그룹을 만들어주어야 합니다.
2. ASG로 인한 노드 프로비저닝 시간 지연
EKS Cluster AutoScaler는 K8S의 Cluster AutoScaler에 ASG를 활용하여 AWS cloud provider를 구현한 형태입니다. 클러스터 내에서 어플리케이션 로드를 감지한 이후, 중간에 AWS 리소스 요청을 거치기 때문에 즉시 처리되기가 어렵습니다.
Karpenter 소개
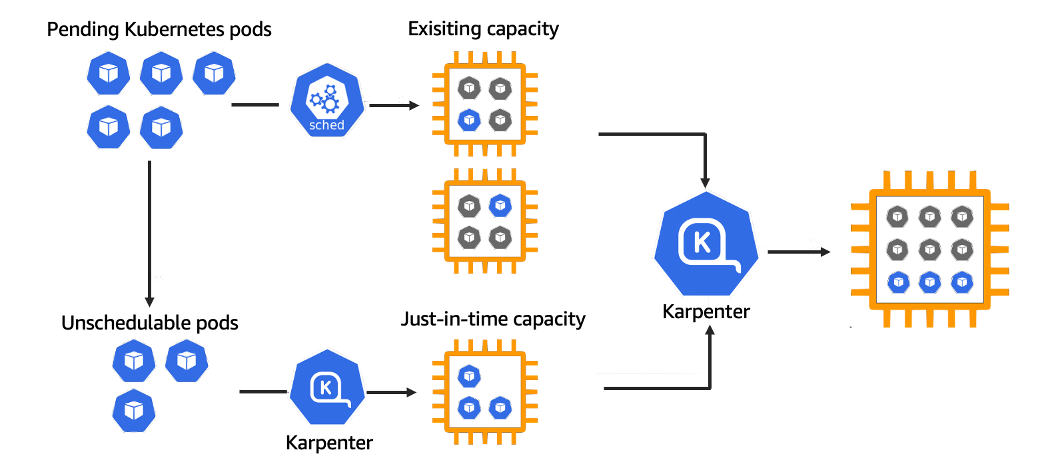
Karpenter는 다음과 같이 세 가지 컴포넌트로 구성되어 있습니다.
- Controller: K8S controller 형태로 구현되어 pod 상태를 감시하고 노드 확장 및 축소
- Webhook: Provisioner CRD에 대한 유효성 검사 및 기본값을 지정
- Provisioner: Karpenter에 의해 생성되는 노드와 Pod에 대한 제약조건을 지정
Karpenter Helm Chart를 통해 설치하면 controller와 webhook pod가 생성됩니다. 이후에 provisioner CRD를 정의하고 클러스터에 배포하면 사용할 수 있습니다. provisioner는 ASG 노드 그룹과 유사한 개념입니다. 따라서 default를 사용하는게 아니라 기존에 사용하던 설정에 맞게 새로 만들어야 합니다. Scale In/Out 관련된 내용은 다음과 같습니다.
Scale Out 기준
- pending 상태의 pod 수, 리소스 요청량에 따라 수행
- 신규 노드가 15분 동안 NotReady 상태라면 종료하고 새로 생성
- kubernetes well-known label 설정 가능
Scale In 기준
- 노드에 예약된 pod가 없는 경우
- 해당 노드에 대해 cordon, drain을 수행하고 삭제
karpenter.sh/do-not-evict설정을 통해 보호 가능
Karpenter vs AutoScaler
앞서 언급했던 Cluster AutoScaler와 Karpenter를 비교해보면 다음과 같습니다.
1. Provisioner API를 통해 간편한 노드 관리
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.large", "m5.2xlarge"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["ap-northeast-2a", "ap-northeast-2c"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]Karpenter는 노드 프로비저닝을 위해 ASG 노드 그룹을 생성할 필요가 없습니다. 대신 yaml을 통해 Provisioner CRD만 생성하면 됩니다. 현재 노드 프로비저닝을 위한 instance type, subnet, volume, SG 등 대부분의 설정을 지원하고 있습니다.
2. 수 많은 인스턴스 유형에 대해 유연하게 처리
Karpenter는 노드 프로비저닝을 위해 EC2 Fleet API를 사용합니다. 사용자는
여러 유형의 인스턴스를 지정할 수 있으며 어떤 유형의 인스턴스를 생성할지는 Karpenter가 결정합니다. 예를 들어 pending 상태의 pod가 1CPU, 4GB 리소스를 요청한다면 m5.large 인스턴스를 생성합니다. spot 인스턴스의 경우, Fleet API의 최저 입찰 경쟁에 따라 저렴한 비용으로 사용할 수 있습니다.
3. 노드 프로비저닝 시간 단축
Karpenter는 Cluster AutoScaler와 동일한 역할을 하지만 자체 구현된 오픈소스로 JIT(Just-In-Time)을 지원합니다. 적용한 이후 실제로 약 2배 정도 프로비저닝 시간이 단축되었습니다. Karpenter를 통해 생성된 노드는 pre-pulling을 통해 이미지를 미리 받아올 수 있으며 빠른 컨테이너 런타임 준비를 통해 pod를 즉시 바인딩할 수 있습니다.
두 가지 AutoScaler는 여러 장단점이 존재하기 때문에 적절하게 선택할 필요가 있습니다. 데이터 영역에서 활용하는 클러스터는 다양한 인스턴스 유형을 사용하고 빈번하게 스케일 조정이 일어나는 경우가 많습니다. 따라서 Karpenter가 가지는 장점을 최대로 활용할 수 있습니다.
Karpenter 이관 가이드
최근에 공식 이관 가이드가 나와서 제가 사용했던 이관 방법들과 주의사항 위주로 정리해보았습니다.
이관 방법
- 기존에 사용하던 설정들과 Scale In/Out에 대한 테스트는 karpenter 문서에서 안내하는 inflate pod을 통해 진행할 수 있습니다.
- Cluster AutoScaler의 일부 노드 그룹을 Provisioner로 이관하는 방식으로 진행하면 점진적으로 옮겨갈 수 있습니다.
- Provisioner yaml 설정에 익숙하지 않다면 launch template을 만들어 정의하는 방법도 있습니다. 하지만 동일 설정이 있다면 Karpenter에서는 Provisioner yaml을 우선시하기 때문에 launch template 사용하는 방법을 권장하지 않습니다.
- Scale In에서 노드가 종료되는 시간을 조정하기 위해 TTL 설정을 사용하는 것이 좋습니다. TTL 설정이 너무 작으면 잠시 재시작하는 상황에서도 Scale In/Out이 빈번하게 발생할 수 있습니다.
- karpenter 관련 pod는 karpenter에 의해 생성된 노드에 띄울 수 없습니다. 따라서 ASG 노드 그룹이 적어도 하나는 존재해야 합니다.
Karpenter가 가지는 제한 사항
- Karpenter에 의해 생성되는 노드는 현재 ASG max 설정과 같은 클러스터 상한선 기준이 없습니다. 따라서 노드에 대한 모니터링과 알림이 필요합니다. Karpenter에서는 프로메테우스 메트릭을 제공하고 있습니다.
- Karpenter의 Binpacking 로직은 VPC CNI 네트워크 사용을 가정하기 때문에 커스텀 CNI를 사용한다면 제대로 동작하지 않을 수 있습니다.
- 0.10 이전 버전에서는
podAffinity,podAntiAffinity를 지원하지 않습니다. 따라서 하위 버전을 사용한다면nodeSelector,topologySpreadConstraints를 활용하셔야 합니다.