


Kafka Connect로 S3에 데이터를 저장해보자
📅 November 16, 2018
•⏱️4 min read
Kafka에는 정말 유용한 컴포넌트들이 존재합니다. 오늘은 그 중 하나인 Kafka-Connect에 대해 알아보고, Confluent에서 제공하는 Kafka-Connect-S3를 활용하여 S3로 데이터를 저장하는 방법에 대해 정리해보려고 합니다.
Kafka Connect
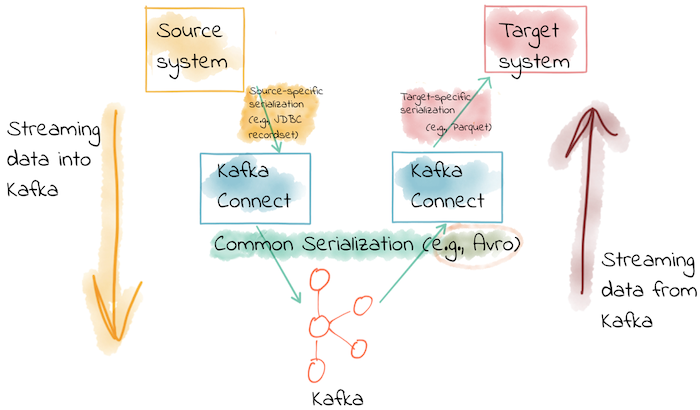
우리는 서버로부터 생성되는 데이터를 실시간으로 Kafka에 보내기도 하고, Kafka Topic에 쌓여있는 데이터를 실시간으로 RDBMS, Object Storage와 같은 시스템에 보내기도 합니다. Kafka Connect는 위의 그림과 같이 다양한 시스템과 Kafka 사이의 연결을 도와주는 역할을 하는 컴포넌트입니다. Source System에서 Kafka로 들어가는 Connector를 Source Connect라 부르고, Kafka에서 Target System으로 보내는 Connector를 Sink Connect라 부릅니다.
Kafka Connect는 JSON, Avro, Protobuf 등의 다양한 직렬화 포멧을 지원하며 Kafka Schema Registry와 연동시켜 공통된 스키마 지정을 할 수도 있습니다.
사실 Fluentd와 ELK Stack에서 사용하는 Logstash 등 서로 다른 시스템 간의 브릿지 역할을 하는 프레임워크들은 다양하게 존재합니다. 하지만 Kafka Connect가 갖는 강점은 Kafka와 긴밀히 연동되어 있다는 점 입니다.
Kafka Connect를 사용하지 않고 데이터를 실시간으로 전달하기 위해서는 Producer, Consumer API를 사용해야 합니다. 이 과정에서 이미 처리되거나 실패한 데이터를 추적한다거나, 데이터 분산처리, 작업을 배포하는 등의 작업을 수행해야만 합니다.
Kafka Connect는 앞의 모든 작업을 수행할 뿐만 아니라 connector task를 클러스터 전체에 자동으로 배포합니다. 또한, Connect Worker 중에 하나가 실패하거나 Network partition이 발생하더라도 실행하던 작업을 나머지 Worker들에게 자동으로 재조정합니다. Offset을 자동으로 관리, 유지하기 때문에 재시작하더라도 중단 시점부터 다시 시작할 수 있고 (Exactly Once Delivery), High performance Kafka library로 작성되어 빠르며 불필요한 polling 작업을 수행하지 않습니다. 무엇보다 코드 한 줄 없이 사용하기 편하다는 것도 큰 강점입니다. 혹시 Kafka를 이미 중앙 집중형 로그 저장소로 사용하고 있다면 Kafka Connect를 고려해볼만 하다고 생각합니다.
Kafka-Connect-S3
이 글에서는 Confluent로 Kafka를 설치하지 않은 경우를 예시로 들겠습니다. 이미 confluent-hub를 설치하셨거나 Confluent로 Kafka를 설치하셨다면 공식문서를 따라가시면 됩니다.
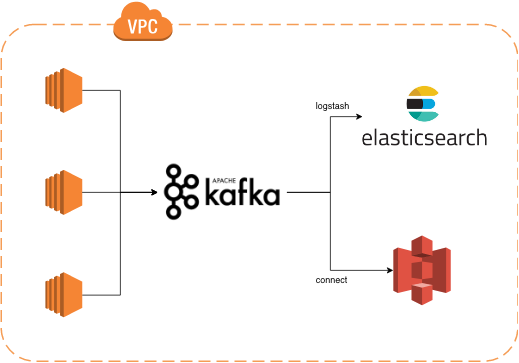
데이터 인프라가 AWS 환경에 구축되어 있다면 S3를 Cold Storage로 많이 사용하게 됩니다. 최대한 단순하게 그림을 그려보면 위의 그림과 같은 아키텍쳐가 나오게 됩니다. 여기에서는 Kafka에서 S3로 실시간 데이터를 저장하기 위해 Kafka-Connect-S3를 사용하게 됩니다.
먼저 confluent에서 kafka-connect-s3를 다운받아 plugins 경로에 추가합니다.
$ wget https://api.hub.confluent.io/api/plugins/confluentinc/kafka-connect-s3/versions/4.1.1/archive
$ unzip archive
$ mkdir -p plugins/kafka-connect-s3
$ cp confluentinc-kafka-connect-s3-4.1.1/lib/* plugins/kafka-connect-s3/이제 kafka config 경로에 connect.properties라는 이름으로 설정 파일을 추가합니다.
bootstrap.servers와 plugin.path 경로는 상황에 맞게 수정하시면 됩니다.
추가로 kafka 클러스터를 private network로 연결하고 싶다면 9093 포트를 사용해주시면 됩니다.
# Kafka broker IP addresses to connect to
bootstrap.servers=localhost:9092
# Path to directory containing the connector jar and dependencies
plugin.path=/home/ec2-user/kafka/plugins
# Converters to use to convert keys and values
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
# The internal converters Kafka Connect uses for storing offset and configuration data
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets기존 클러스터에 Authentication credentials, encryption이 설정되어 있다면, connect.properties에 관련 설정을 추가해주셔야 합니다.
다음 S3에 데이터가 저장될 Bucket을 생성하고, AWS Credentials를 설정합니다.
$ pip install awscli
$ aws configuresink connector 관련 설정 파일을 s3-sink.properties라는 이름으로 config 경로에 추가합니다.
topics와 s3.bucket.name의 이름은 맞게 수정해주셔야 합니다.
name=s3-sink
connector.class=io.confluent.connect.s3.S3SinkConnector
tasks.max=1
topics=my-topic-name
s3.region=ap-northeast-2
s3.bucket.name=my-bucket-name
s3.compression.type=gzip
s3.part.size=5242880
flush.size=3
storage.class=io.confluent.connect.s3.storage.S3Storage
format.class=io.confluent.connect.s3.format.json.JsonFormat
schema.generator.class=io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator
partitioner.class=io.confluent.connect.storage.partitioner.TimeBasedPartitioner
partition.duration.ms=3600000
path.format=YYYY-MM-dd
locale=KR
timezone=UTC
schema.compatibility=NONE이제 Kafka 설치 경로로 이동하고 Kafka-Connect를 실행시킵니다. 여기에서는 standalone mode로 실행시켰지만, 경우에 따라 cluster mode로 실행하거나 docker container로 실행시켜도 됩니다.
./bin/connect-standalone.sh connect.properties s3-sink.properties이제 지정한 S3 Bucket의 topic/my-topic-name/2018-11-16 경로에 가시면 지정한 설정 값에 따라 파일이 저장되는 것을 확인하실 수 있습니다.
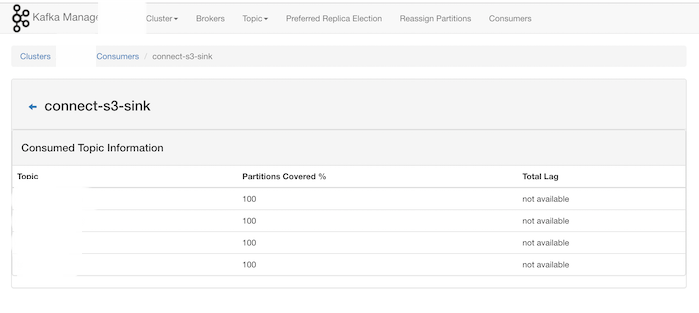
이미 Yahoo의 kafka-manager를 사용하고 계신 분들은 consumers 메뉴로 가시면 topic 마다 lag도 모니터링할 수 있습니다.
Kafka-Connect-S3 Configuration
데이터 인프라에 맞게 수정해야할 옵션은 아래와 같습니다.
- s3.part.size: S3의 multi part upload 사이즈를 지정
- flush.size: file commit 시 저장할 record의 수 (파일 사이즈와 연관)
- partitioner.class: partition 기준을 지정 (TimeBasedPartitioner는 시간을 기준으로 파티셔닝)
이외에도 Avro Format과 Schema Registry를 사용하신다면 format.class, schema.generator.class를 수정해야 합니다.
더 자세한 내용은 공식문서에서 확인하시면 됩니다.
Reference
사실 Kafka는 이미 대부분의 데이터 파이프라인에서 활용하고 있다는 것이 강점이라고 생각합니다. ETL 과정이 다양하고 복잡할 수록 새로운 프레임워크가 추가되고 아키텍쳐가 복잡해지기 마련인데, Kafka의 다양한 컴포넌트들을 잘 활용하면 아키텍쳐를 단순화시킬 수도 있습니다.