


AI를 통해 변화하는 데이터플랫폼 근황
📅 January 21, 2024
•⏱️4 min read
생성형 AI의 공개 이후 다양한 영역에서 활용하는 사례가 늘어나고 있습니다.
오늘은 데이터플랫폼 영역에서 AI를 통해 어떤 변화가 나타나고 있는지 정리해보려 합니다.
자연어를 SQL로 변환 (Text2SQL, SQL2Text)
지난 수 년간 클라우드 마이그레이션이 늘어남에 따라 Databrics, Snowflake와 같은 Managed DW 서비스도 함께 성장해왔습니다. Managed DW 서비스가 23년 Summit에 내세운 키워드는 생성형 AI 였습니다. 다양한 기능을 공개했지만 핵심은 Text2SQL, SQL2Text 기술이라고 볼 수 있습니다.
Text2SQL이란 주어진 자연어로부터 쿼리문을 생성하는 것을 말합니다.
쉽게 말해 사용자가 AI에게 한글로 질문하면 필요한 쿼리를 만들어주는 기능입니다.
데이터플랫폼에서는 그 동안 쿼리 사용에 어려움을 겪는 비개발자도 쉽게 사용할 수 있도록 다양한 데이터 분석 도구들을 만들어왔습니다. 하지만 이제 UI가 아닌 "자연어" 라는 인터페이스를 통해 쉽게 탐색할 수 있게 되었습니다. Text2SQL 기술을 플랫폼에 적용하는 방식은 크게 두 가지로 볼 수 있습니다.
검색 UI 연동
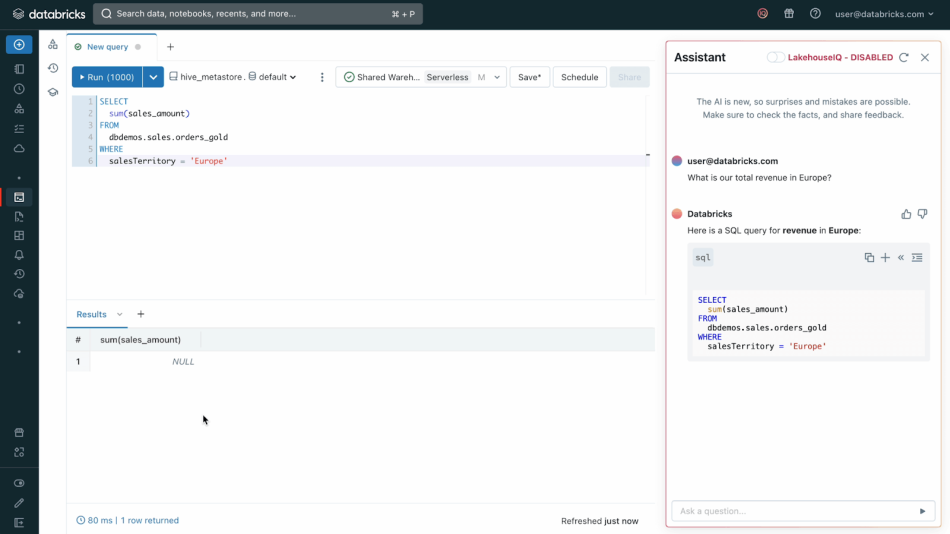
그 중 첫 번째는 검색 UI를 연동하는 방식입니다.
사이드에 어시스턴트를 추가함으로써 ChatGPT 서비스와 유사한 환경을 제공합니다.
검색 UI는 쿼리문을 입력하는 쿼리 에디터 뿐만 아니라 노트북, 카탈로그 등 다양한 기능에 연결되어 있습니다.
SQL 함수, 자연어 SDK 추가
SELECT ai_query(
'my-external-model-openai-chat',
'Describe Databricks SQL in 30 words.'
) AS summary
# english sdk
new_df = df.ai.transform('get 4 week moving average sales by dept')두 번째는 SQL 함수나 자연어 SDK를 추가하는 방식입니다.
이를 통해 사용자는 개발 과정에도 자연어를 활용할 수 있습니다.
검색 UI와 달리 사용자의 검증을 거치지 않고 사용할 수 있지만, 일관된 답변을 보장 할 수 없는 관계로 운영 시스템에 직접 연동은 아직 어려울 것 같습니다.
이처럼 다양한 방식을 지원함으로써 사용자는 AI에 쉽게 접근하고 일관된 개발 경험을 가질 수 있습니다.
기술 문서 검색
개발자는 개발 과정에서 문서 검색에 많은 시간을 사용합니다.
stackoverflow를 통해 검색하는 경우, 내가 사용하고 있는 프레임워크와 버전에 정확히 일치하는 문서를 찾지 못하는 경우도 많았습니다. 이제 데이터플랫폼 내에서 기술 문서와 코드를 기반으로 AI에게 질의할 수 있게 되었습니다.
AWS Amazon Q Assistant
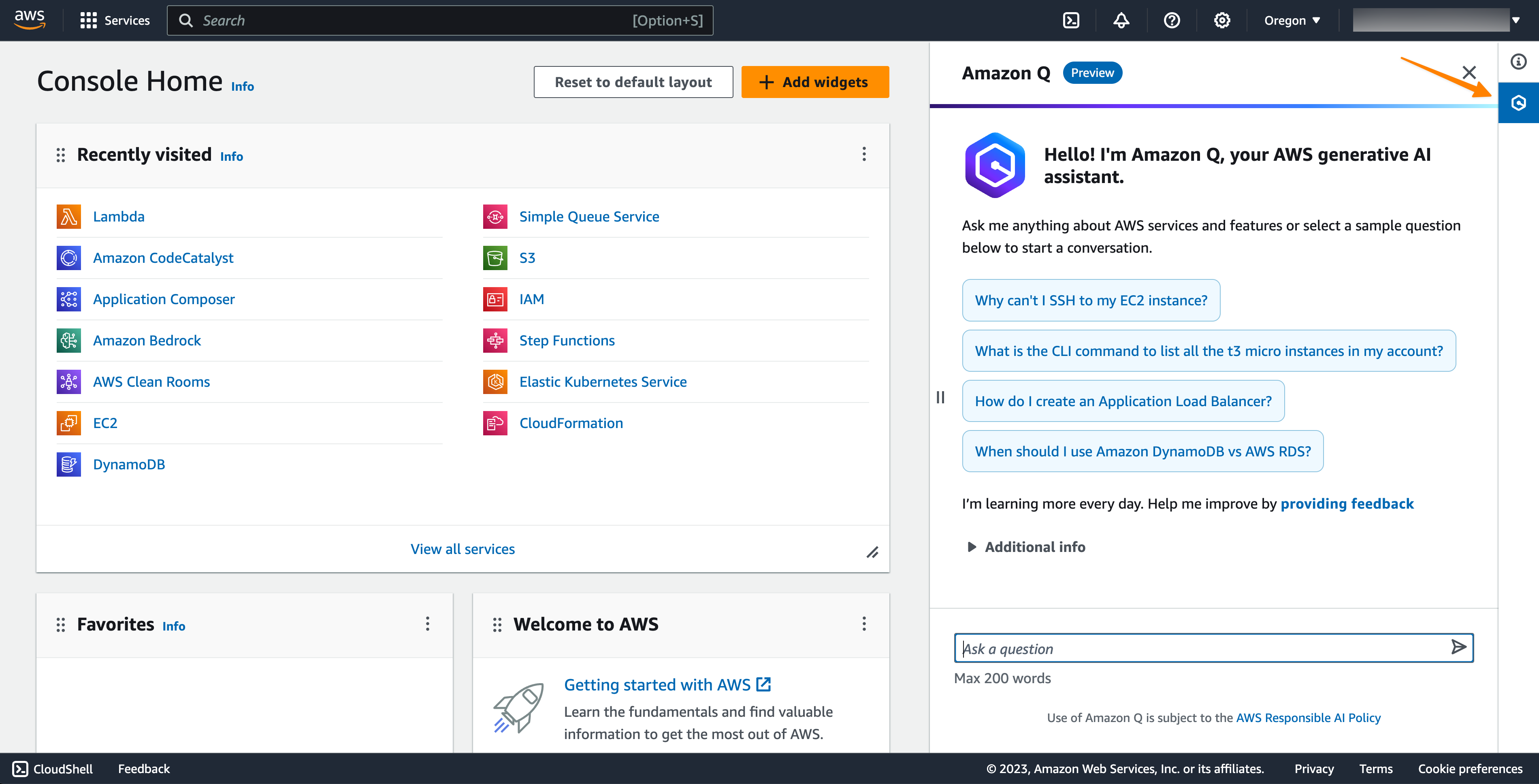
Amazon Q는 AWS에서 출시한 생성형 AI 어시스턴트입니다.
AWS 콘솔 우측에 추가되어 AWS 클라우드와 관련된 다양한 질의를 수행할 수 있습니다.
GitHub Dosu
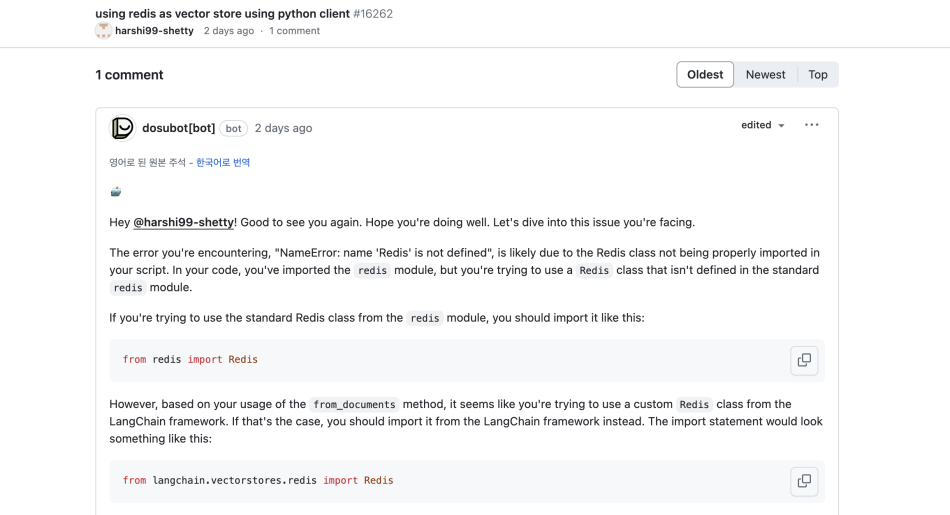
오픈소스 영역에서도 생성형 AI를 통해 Issue, Discussion 문의 대응하는 사례가 생기고 있습니다. 위 그림은 LLM 프레임워크인 LangChain에서 사용하는 Dosu 봇 입니다. 출시 예정인 GitHub Copilot도 이와 유사한 기능을 지원합니다. 이러한 기능을 통해 사용자는 빠르게 문제를 해결하고 메인테이너는 중요한 의사결정에 집중할 수 있습니다.
데이터 거버넌스 도구
데이터 거버넌스는 정책을 만드는 일보다 운영하는데 더 많은 노력이 들어갑니다.
거버넌스 내에는 다양한 영역이 있지만 그 중 데이터 디스커버리와 메타데이터 관리에 AI가 활용되고 있습니다.
데이터 디스커버리 영역의 경우, 기존 UI 기반 검색 엔진에 자연어 질의가 추가됩니다.
이를 통해 앞서 언급한 Text2SQL과 유사한 경험을 제공할 수 있습니다.
다음은 메타데이터 관리 영역입니다. 메타데이터 관리는 데이터 신뢰도를 위해 데이터 생산자와 소비자 모두에게 중요합니다. 하지만 거버넌스 정책이 새로 추가되거나 변경되면 데이터에 대한 오너십을 가지는 도메인 전문가는 이를 항상 인지하기 어렵습니다. 만약 불일치가 발생하면 거버넌스 담당자가 보정하는 작업을 수행하는 경우도 있습니다. 메타데이터 영역의 AI는 거버넌스 정책을 유지하고 메타데이터 입력을 도와주는 역할을 합니다.
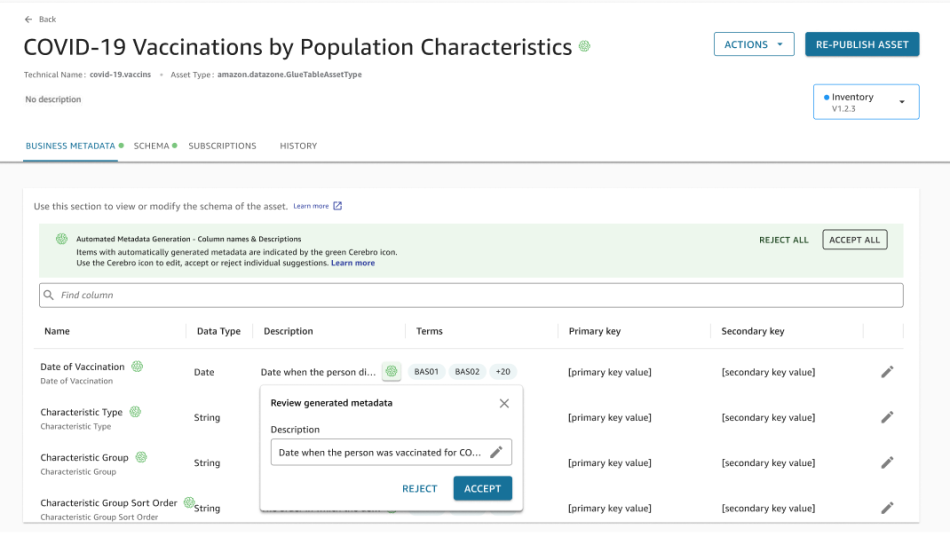
위 예시는 AWS DataZone 입니다.
AI를 통해 입력된 메타데이터를 리뷰하여 올바른 내용으로 교정할 수 있습니다.
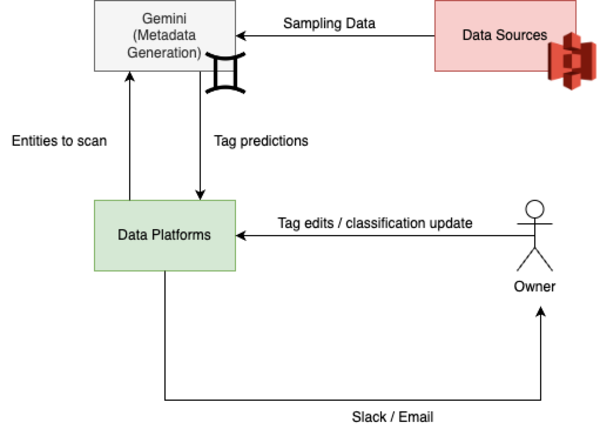
Grab의 경우, LLM이 데이터 분류를 위한 태그를 생성하고 거버넌스 담당자가 확인 후 승인하는 프로세스를 개발했습니다. 이를 통해 민감도 분류, 개인정보 컬럼에 PII 태그를 붙이는 등의 거버넌스 정책을 20,000개 이상 데이터에 일관되게 적용할 수 있었습니다.
플랫폼에 AI를 사용하는 이유
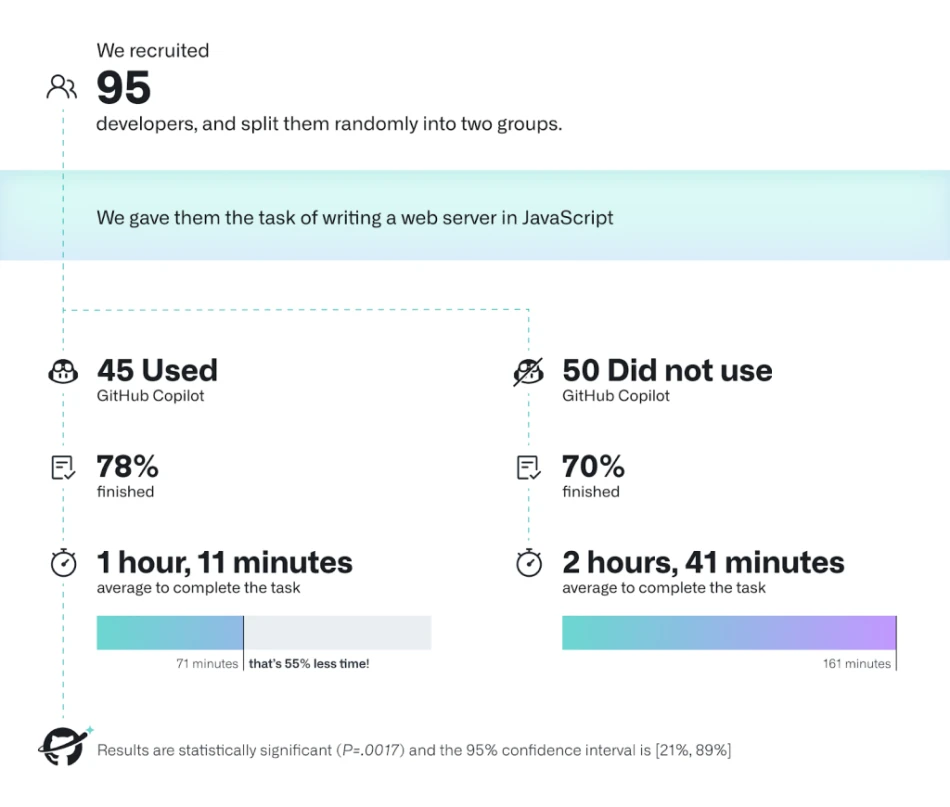
GitHub Copilot Research에 따르면 Copilot 사용 시 55%의 생산성 증가 효과가 나타난다고 합니다.
플랫폼에 AI를 도입함으로써 사용자는 개발 생산성을 얻을 수 있고 기업은 운영 비용을 절감할 수 있습니다. 따라서 앞으로도 다양한 활용 사례가 추가될 것이라 합니다.
Reference
실제 기능에 대한 자세한 내용은 아래 링크를 통해 확인하실 수 있습니다.