


GFS, HDFS 그리고 MapReduce
📅 March 14, 2017
•⏱️2 min read
데이터가 급속히 늘어나면서 기존의 방법으로 처리가 힘들어지자, 빅데이터를 위한 대용량 분산 파일 시스템이 나타나기 시작했습니다. 여기에서는 GFS, HDFS 그리고 Map Reduce 개념에 대해 정리해보려고 합니다.
GFS (Google File System)
Google File System은 2003년 논문을 통해 소개되었습니다. 이전에 구글에서 사용하던 파일 시스템은 Big File 이었는데, 구글의 데이터가 급격히 늘어남에 따라 핵심 데이터 스토리지와 구글 검색 엔진을 위해 최적화 된 파일 시스템이 필요하게 된 것 입니다.
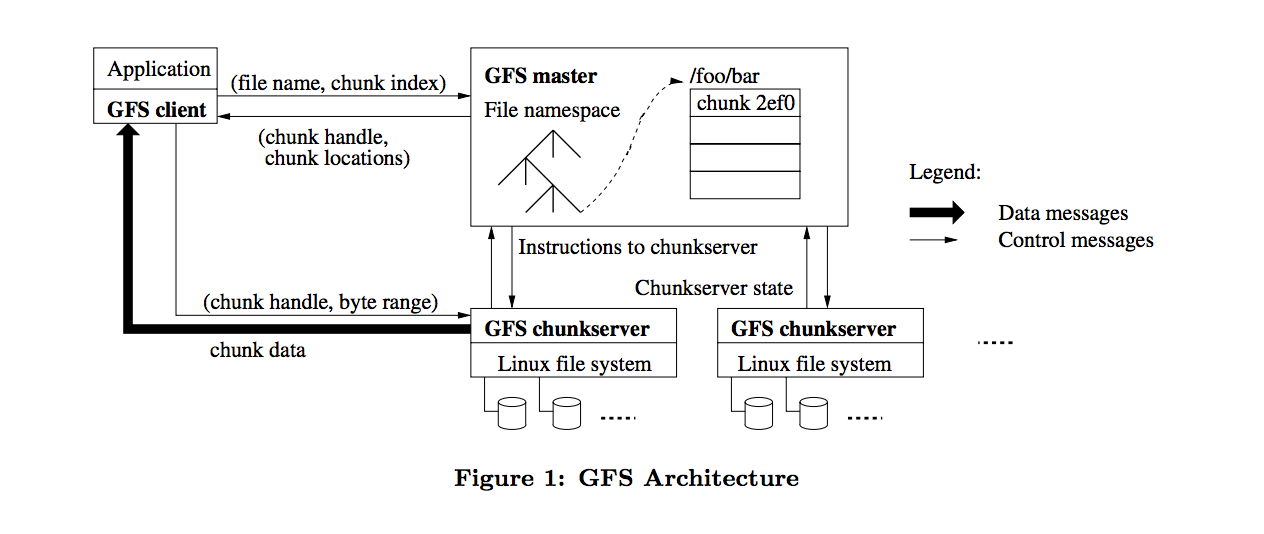
GFS는 크게 하나의 master node와 여러 개의 slave node로 구성되어 있습니다. 기능으로 보면 Master, Chunk Server, Client로 이루어져 있습니다.
- Master: GFS 전체를 관리하고 통제하는 중앙 서버의 역할
- Chunk Server: 물리적인 서버, 실제 입출력을 처리
- Client: 파일 입출력을 요청하는 클라이언트 어플리케이션
수행과정은 다음과 같습니다. 먼저 Client가 Master에게 파일의 읽기, 쓰기를 요청하게 되면, Master는 Client와 가까운 Chunk Server의 정보를 Client에게 전달합니다. Client는 전달받은 Chunk Server와 직접 통신하며 IO 작업을 수행하게 됩니다.
GFS의 엄청난 강점은 Failuer Tolerance 입니다. 다시 말해서, 물리적으로 서버 중 하나가 고장이 나도 정지하지 않고 잘 돌아가도록 설계되었습니다. 예를 들어, Chunk Server 중 하나가 고장이 나면 Master는 고장나지 않은 Chunk Server의 정보를 전달하고 Master Server가 고장이 나면 다른 서버가 Master를 대체하게 됩니다. 이러한 이유로 Chunk Server는 가격이 저렴한 범용 컴퓨터들로 구성할 수 있게 되었고, 클러스터 환경에서 잘 동작할 수 있게 되었습니다.
MapReduce
Map Reduce는 마찬가지로 2004년 구글의 논문(저자: 구글의 전설 제프 딘)을 통해 소개되었습니다. 논문의 제목은 MapReduce: Simplified Data Processing on Large Clusters 입니다. 즉, MapReduce는 말 그대로 대용량 분산 클러스터에서 데이터를 간단히 처리하는 방법입니다.
그는 논문을 통해 2가지 Function을 제시하는데 바로 Map과 Reduce 입니다. 논문에서 제시한 MapReduce의 예시 수도코드는 다음과 같습니다.
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1")
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v)
Emit(AsString(result))먼저 Map 함수는 어떤 key-value를 input으로 받아서 각 단어와 관련 발생 횟수를 출력합니다. 그리고 Reduce 함수는 특정 단어에 대해 생성된 모든 카운트를 합산합니다.
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(v2)Map 함수는 key-vale를 읽어서 필터링하거나 다른 값으로 변환시켜주며, Reduce 함수는 Map을 통해 출력된 리스트에 새로운 key를 기준으로 Groupping하고 이를 Aggregation한 결과를 출력합니다.
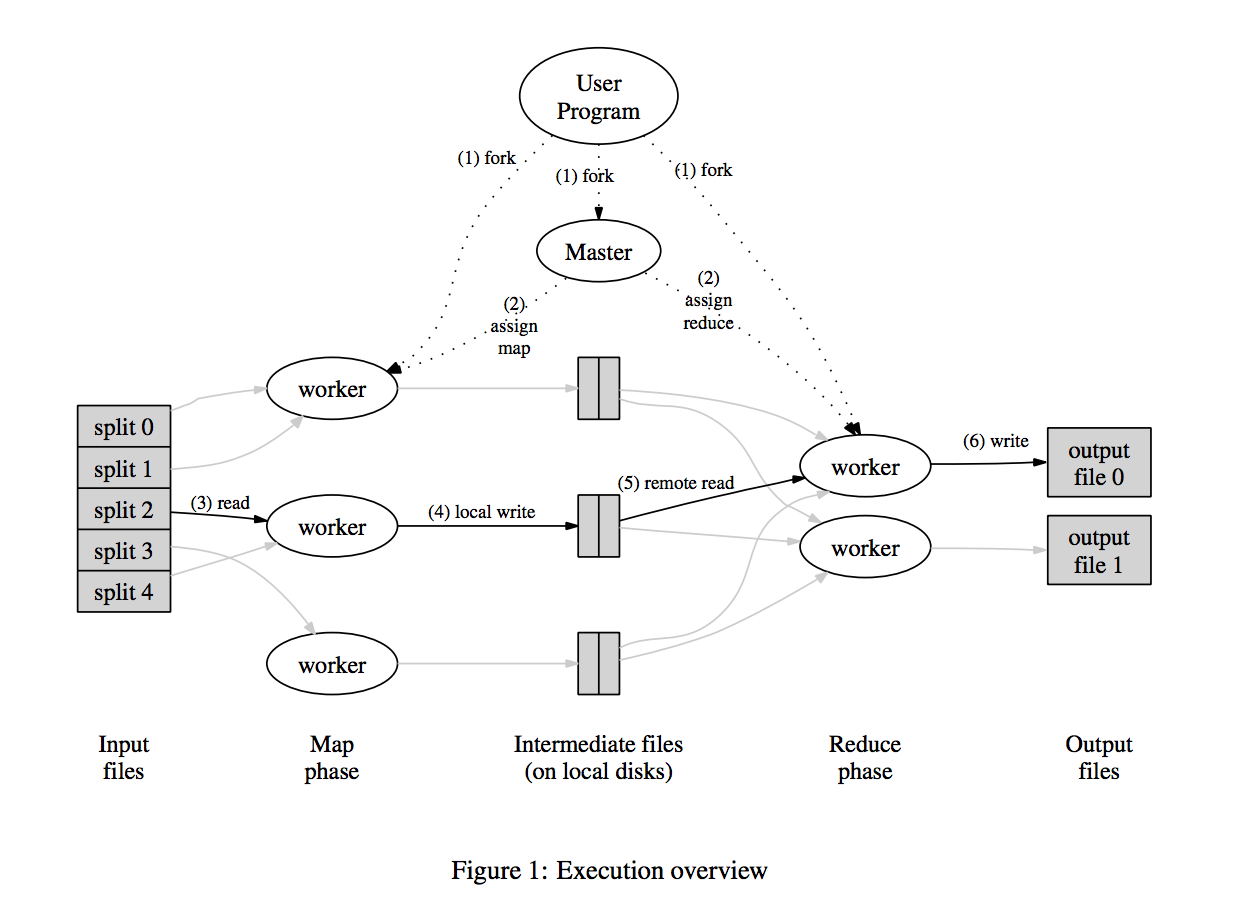
MapReduce는 여러 대의 컴퓨터에서 데이터를 처리하는 경우, 병렬처리를 하기 때문에 확장이 쉽습니다. 스케줄러가 데이터를 분산 배치하면 worker에서 작업을 수행하고 각 중간 결과는 로컬 디스크에 저장되며, 나중에 Reduce 연산을 할당받으면 중간 결과를 읽어와서 작업을 수행하고 마찬가지로 파일 시스템에 저장합니다. 위의 그림과 같이 Master 노드에 모든 데이터를 받아서 처리하던 옛날 방식과 통신 처리면에서 확실히 줄어든 것을 알 수 있습니다.
구글은 MapReduce를 URL 접근빈도, Web-Link Graph를 계산하는데 사용하였고, 이를 통해 인덱싱, 정렬 등에서 엄청난 성능향상을 보여주었습니다.
HDFS (Hadoop Distributed File System)
Hadoop은 2006년 Doug Cutting과 Mike Cafarella가 개발한 분산처리 프레임워크입니다. 이들은 구글의 GFS를 대체하기 위해 HDFS 와 MapReduce 를 구현하였습니다.
GFS가 C++로 구현되었다면, Hadoop은 자바로 개발된 데다가 아파치 재단의 오픈소스로 넘어가면서 인기가 많아졌습니다. GFS를 구현한 결과물이기 때문에 크게 달라진 것은 없으나 YARN, Hadoop Ecosystem 등 다른 장점으로 인해 많이 사용됩니다.