


LLM 서비스 최적화: 리전 로드밸런싱과 캐싱
📅 October 13, 2024
•⏱️4 min read
최근 다양한 영역에서 LLM 기반 서비스 개발 사례가 늘어나고 있습니다.
그 중에서도 검색 결과를 바탕으로 자연어를 생성하는 RAG 방식이 많이 활용되고 있습니다.
이번 글에서는 RAG 어플리케이션을 운영하며 고민했던 내용들을 정리해보려 합니다.
Problem
LLM 기반 서비스는 다양한 형태로 구성될 수 있습니다.
간단한 요구사항은 [단일 프롬프트 - 응답] 구조를 통해 쉽게 해결할 수 있습니다.
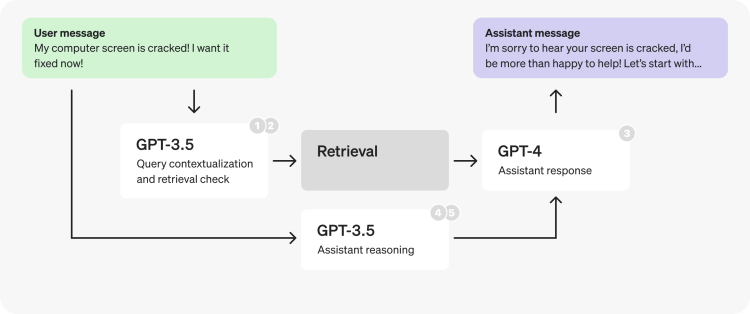
하지만 위의 복잡한 시나리오와 같이 2번 이상의 LLM 요청이 필요한 서비스의 경우,
다음과 같은 문제를 고려해야 합니다.
1. Token Rate Limit
모든 LLM 요청에는 토큰 제한이 존재합니다.
예를 들어 Azure OpenAI API의 경우, TPM(Tokens Per Minute, 분당 토큰 처리 수)과 RPM(Requests Per Minute, 분당 요청 수)을 통해 제한하고 있습니다.
2. Latency
복잡한 Chain으로 구성된 경우, 사용자 요청마다 문서 검색과 여러 번의 LLM 요청으로 인해 응답 지연이 발생할 수 있습니다. 그리고 모델과 API 서비스 상황에 따라 응답 지연이 발생할 수 있습니다.
3. Cost
LLM 요청 시, Input과 Output 토큰 수에 따라 비용이 발생합니다.
따라서 사용자가 많거나 여러 번 호출되는 경우, 비용이 크게 발생하지 않도록 최적화가 필요합니다.
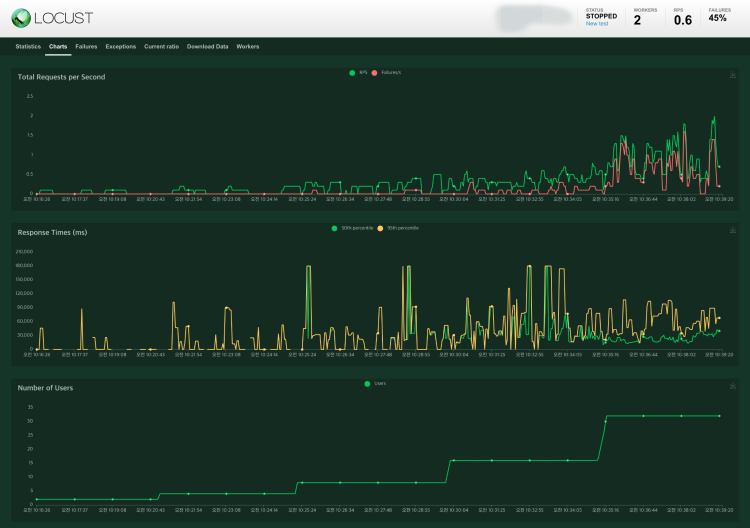
위 부하테스트 결과와 같이 일부 모델에서는 사용자 요청이 증가함에 따라 Timeout, RateLimit 오류도 발생할 수 있습니다.
이러한 문제들은 사용자 경험과 서비스 성능에 직접적인 영향을 미칠 수 있습니다.
따라서 이를 개선하기 위한 3가지 방법에 대해 알아보겠습니다.
Region Load Balancing
API 제공자의 정책으로 인해 사용 중인 리전 내에서 Rate Limit을 늘리기는 어렵습니다. 이에 대한 대안으로 리전 로드밸런싱을 적용할 수 있습니다. 리전 로드밸런싱은 여러 리전의 API 리소스를 생성하여 트래픽을 분산하는 방법입니다. 이 방식을 통해 서비스의 지연 시간을 줄이고, 가용성을 높이며, 장애가 발생할 경우에도 다른 리전으로 요청을 전환(failover)할 수 있습니다.
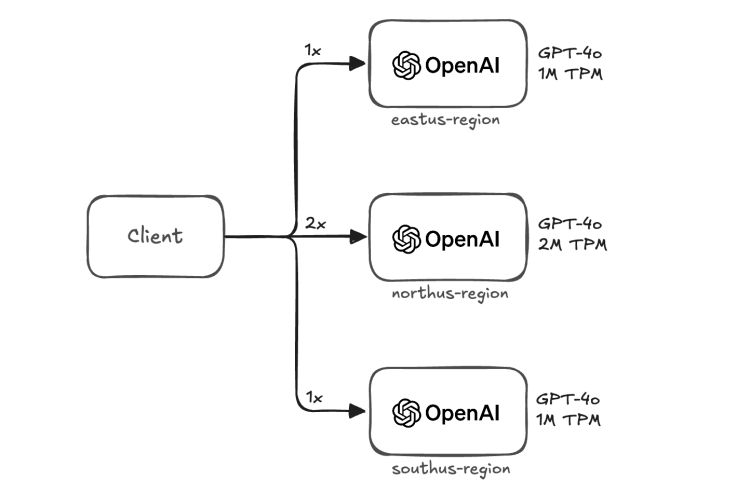
위 예시는 클라이언트 측에서 리전 로드밸런싱을 적용했을 때의 그림입니다. 사용자의 요청은 라운드 로빈(Round-Robin) 방식을 통해 분산됩니다. 리전마다 토큰 제한이 다른 경우를 고려하여 TPM에 비례한 가중치를 부여합니다.
이 방식은 클라이언트 측에서 구현하여 쉽게 적용가능하다는 장점이 있습니다. 반면에 클라이언트에서 리전과 모델 정보를 관리해야 한다는 단점이 있습니다. 모델과 리전의 수가 증가할 수록 API 키 관리가 복잡해지며 리전 정보가 추가되거나 변경될 때마다 클라이언트의 재시작 또는 업데이트가 필요합니다. 또한 여러 클라이언트 사이에서 일관성 유지가 어렵습니다.
AI Gateway
앞서 살펴본 내용과 같이 LLM 기반의 모델과 서비스가 증가함에 따라 클라이언트 방식은 어려움을 마주치게 됩니다. 이를 개선하기 위한 게이트웨이 방식에 대해 알아보겠습니다.
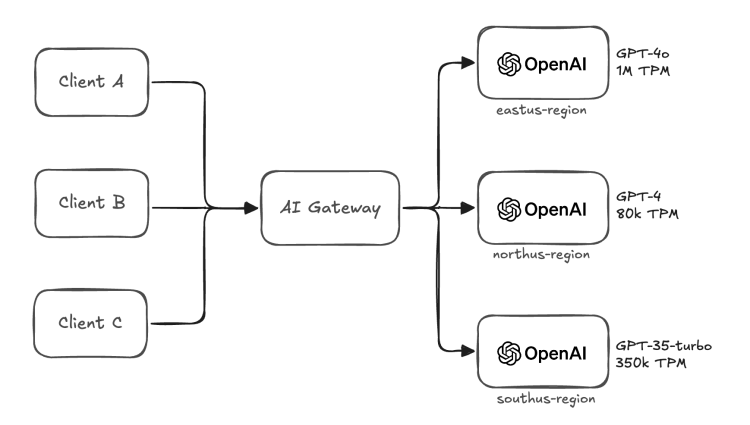
게이트웨이 아키텍처는 클라이언트가 모든 요청을 중앙 로드밸런싱 게이트웨이로 보내고, 게이트웨이가 요청을 적절한 리전으로 라우팅하는 방식입니다. 클라이언트는 리전과 모델 정보를 직접 관리하지 않고, 게이트웨이가 로드밸런싱 역할을 수행합니다.
이 방식은 항상 게이트웨이를 거쳐야한다는 단점이 있습니다. 이는 추가적인 네트워크 통신을 필요로 하며 대량의 트래픽을 처리할 때 게이트웨이의 성능이 전체 시스템의 성능에 영향을 줄 수 있는 단일 장애 지점(Single Point of Failure)이 될 수 있습니다.
반면에 장점은 다음과 같습니다.
- 단순화된 클라이언트 로직: 클라이언트는 모든 요청을 중앙 게이트웨이에 보냅니다. 따라서 클라이언트 측에서는 로드밸런싱이나 서버 상태를 신경 쓸 필요 없이, 게이트웨이에서 알아서 처리합니다. 이를 통해 클라이언트 코드의 복잡성을 크게 줄일 수 있습니다.
- 중앙 집중식 관리: 모든 로드밸런싱 로직이 게이트웨이에서 이루어지므로, 정책이나 설정 변경 시 한 곳에서 이를 제어할 수 있습니다. API 키가 추가되거나 제거되는 상황에서도 클라이언트 코드를 수정할 필요 없이 게이트웨이만 업데이트하면 반영할 수 있습니다.
- 확장성: 게이트웨이가 여러 리전의 상태와 성능을 중앙에서 모니터링하고 로드밸런싱을 수행하므로, 대상이 수십 개에 달하더라도 일관된 방식으로 관리할 수 있습니다. Fallback, Retry와 같은 전략도 함께 반영할 수 있습니다.
- 보안: 클라이언트가 직접 API 정보에 접근하지 않기 때문에, 게이트웨이가 보안 계층의 역할을 수행할 수 있습니다. API 키 관리, 인증 및 권한 부여, 트래픽 필터링 등의 보안 조치를 게이트웨이 레벨에서 쉽게 구현할 수 있습니다.
AI Gateway를 적용하기 위해 많이 사용하는 오픈소스로는 Portkey AI Gateway와 LiteLLM Proxy가 있습니다.
Semantic Cache
마지막으로 지연 시간 최적화를 위한 캐싱 전략에 대해 알아보겠습니다. 기존에 사용하던 Exact Cache는 주어진 질문이 정확히 일치하는 경우에 캐시를 적용하는 방식입니다. 이 방식은 다양한 질문이 들어오는 자연어 질의에서 효과를 보기 어렵습니다.
- 어제 비비큐 주문 수 알려줘
- 어제 BBQ치킨 주문 수 알려줄래?
위의 두 질문은 서로 다른 형태지만, 의미는 동일합니다. Semantic Cache는 단순히 특정 입력에 대해 해당 출력을 캐싱하는 것이 아니라, 입력 질의의 유사도를 기반으로 캐싱된 결과를 재사용할 수 있습니다.
Semantic Cache를 통해 얻을 수 있는 장점은 다음과 같습니다.
- 비용 최적화: LLM의 응답을 생성하기 위한 연산은 상당한 자원과 시간이 소모됩니다. 매번 동일하거나 유사한 질의에 대해 중복해서 모델을 호출하면 자원 낭비와 전체적인 성능 저하가 발생할 수 있습니다.
- 지연 시간 개선: LLM은 복잡한 추론 과정을 통해 응답을 생성하므로, 요청당 지연 시간이 길어질 수 있습니다. 한 번 생성한 결과를 유사한 요청에 재사용하여 지연 시간을 개선할 수 있습니다.
- 일관된 응답 품질: 많은 사용자가 비슷한 질문을 여러 번 하거나, 튜토리얼과 같이 동일한 질문이 여러 세션에서 반복적으로 나타나는 경우가 많습니다. 하지만 LLM의 응답 결과는 불확실하기 때문에 사용자마다 다른 경험을 가질 수 있습니다. 캐시를 사용한다면 일관된 응답을 통해 성능을 개선할 수 있습니다.
Semantic Cache의 구조
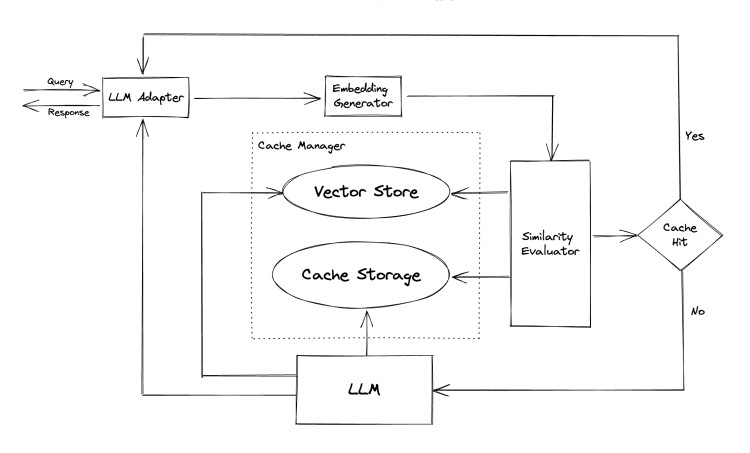
위 그림은 GPTCache의 컴포넌트 아키텍처입니다. 각 컴포넌트는 다음과 같은 역할을 수행합니다.
- Cache Storage: 캐싱을 위해 필요한 QA 데이터와 세션 정보를 저장합니다.
- Vector Store: 유사도 검색에 활용하는 벡터 저장소입니다. 다양한 스토리지 연동이 가능합니다.
- Cache Manager: Eviction 전략, Cache 데이터 보관 등 정책을 정의하고 설정할 수 있습니다.
- Evaluator: 유사도 측정 기준을 결정합니다. 다양한 알고리즘을 적용할 수 있습니다.
Cache Hit 상황에서는 캐싱된 응답을 바로 전달합니다. 반면에 Cache Miss 상황에서는 기존과 동일하게 LLM을 통해 응답을 생성하고 캐시 데이터를 저장합니다. 실제 서비스에 적용 시 일부 질의에서는 약 70%의 지연 시간 단축 효과가 있었습니다.
마치며
이번 글에서는 RAG 어플리케이션의 프로덕션 환경 운영 시 성능에 관한 여러 고려사항들을 살펴보았습니다. 그리고 토큰 제한, 지연 시간, 비용 관리 등의 문제를 개선하기 위한 3가지 방법에 대해 정리해보았습니다. 이 외에도 모델 파라메터나 프롬프트 토큰 최적화를 통한 방법이 있으니 공식 가이드를 읽어보시는 것을 추천드립니다.