


Serverless ETL 서비스들에 대한 리뷰
📅 August 23, 2019
•⏱️5 min read
15년 AWS Lambda가 출시된 이후, 뜨거운 반응을 보이며 다양한 서버리스 서비스들이 출시되었다. 그 중 ETL에 관련되어 있는 서비스들을 사용해보면서 느낀 점에 대해 정리해보려 한다.
Lambda와 Athena를 활용한 쿼리
Athena는 Presto를 기반으로 만든 대화형 쿼리 서비스이다. 쿼리 당 스캔한 데이터의 TB당 5 USD 만 내면 된다. 보통 분석용 쿼리를 위한 클러스터는 리소스 요청이 불규칙적인 경우가 많다. 운영을 위한 비용까지 고려한다면 정말 좋은 서비스라고 볼 수 있다. 하지만 모든 서비스가 그렇듯 장점만 있는 것은 아니다. 특히 Athena를 분석용 쿼리가 아닌 다른 용도로 사용한다면 몇 가지 제한사항을 마주칠 수도 있다.
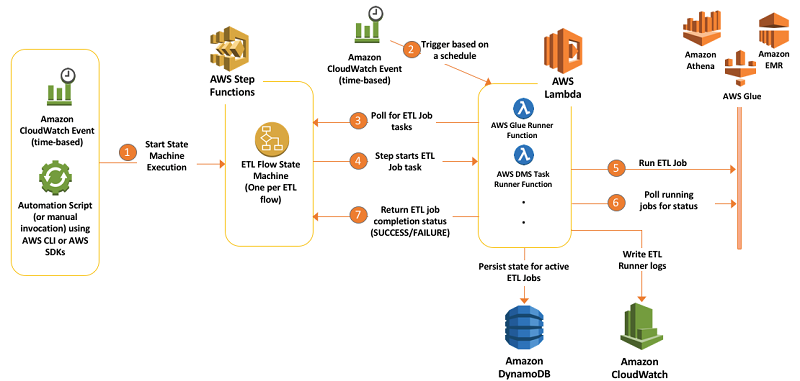
Athena를 ETL 용도로 사용하고 싶다면 위 그림과 같이 Lambda, CloudWatch를 통해 트리거할 수 있다. Athena 뿐만 아니라 Glue, EMR 등 다른 서비스도 모두 Lambda를 통해 실행할 수 있기 때문에 정말 온디멘드로 띄워놓는 인스턴스 하나도 없이 ETL을 구성할 수도 있다. 하지만 정말 데이터가 많고 복잡한 작업이라면 아래와 같은 제약사항들을 잘 이해하고 선택해야 한다.
구글의 빅쿼리와 달리 쿼리 비용을 추정하는 기능이 없다
Athena는 쿼리 비용을 추정하는 기능이 없기 때문에 잘 모르고 쿼리를 막 날린다면 과금 폭탄을 맞이할 수 있다. 물론 처음 사용하는 경우, AWS에 실수한 상황을 설명하면 어느정도 과금을 물러주기도 한다.
Athena에는 동시 쿼리 제한과 시간 제한이 존재한다
Athena의 기본 계정 당 쿼리 한도는 20개이다. Support에 요청하면 늘려주기도 하지만 이 역시 제한이 있다. 또한 30분이라는 쿼리 제한 시간이 존재한다. 따라서 오래걸리거나 무거운 작업에 Athena 쿼리를 활용하는 경우, 앞단에 큐를 두는 경우가 많다.
Athena는 UDF를 지원하지 않는다
어쩌면 크게 다가올 수 있는 제한사항 중에 하나이다. UDF를 많이 등록하고 사용했다면 사용자 입장에서 불편할 수 있다.
Athena의 CTAS 쿼리에는 파티션 한도가 존재한다
CTAS 쿼리란 SELECT의 결과로 채워지는 새 테이블을 생성하는 쿼리를 말한다. CTAS 쿼리를 사용하는 경우, WITH 절의 external_location을 통해 저장될 위치를 지정한다. 이 때 Athena가 생성하는 쿼리 결과 파티션이 100개를 넘어가는 경우 오류가 발생한다.
Glue ETL, Data Catalog
Glue와 S3 Batch는 Athena와 달리 태생부터 ETL을 위해 만들어진 서버리스 서비스이다. 특히 Hive Metastore를 대체할 수 있는 Glue Data Catalog와 자동으로 스키마를 생성해주는 Glue Crawler는 정말 편하게 사용할 수 있다. Glue Data Catalog를 사용한다면 Athena, EMR 내에서 Glue를 중심으로 데이터 소스를 통합할 수 있다.
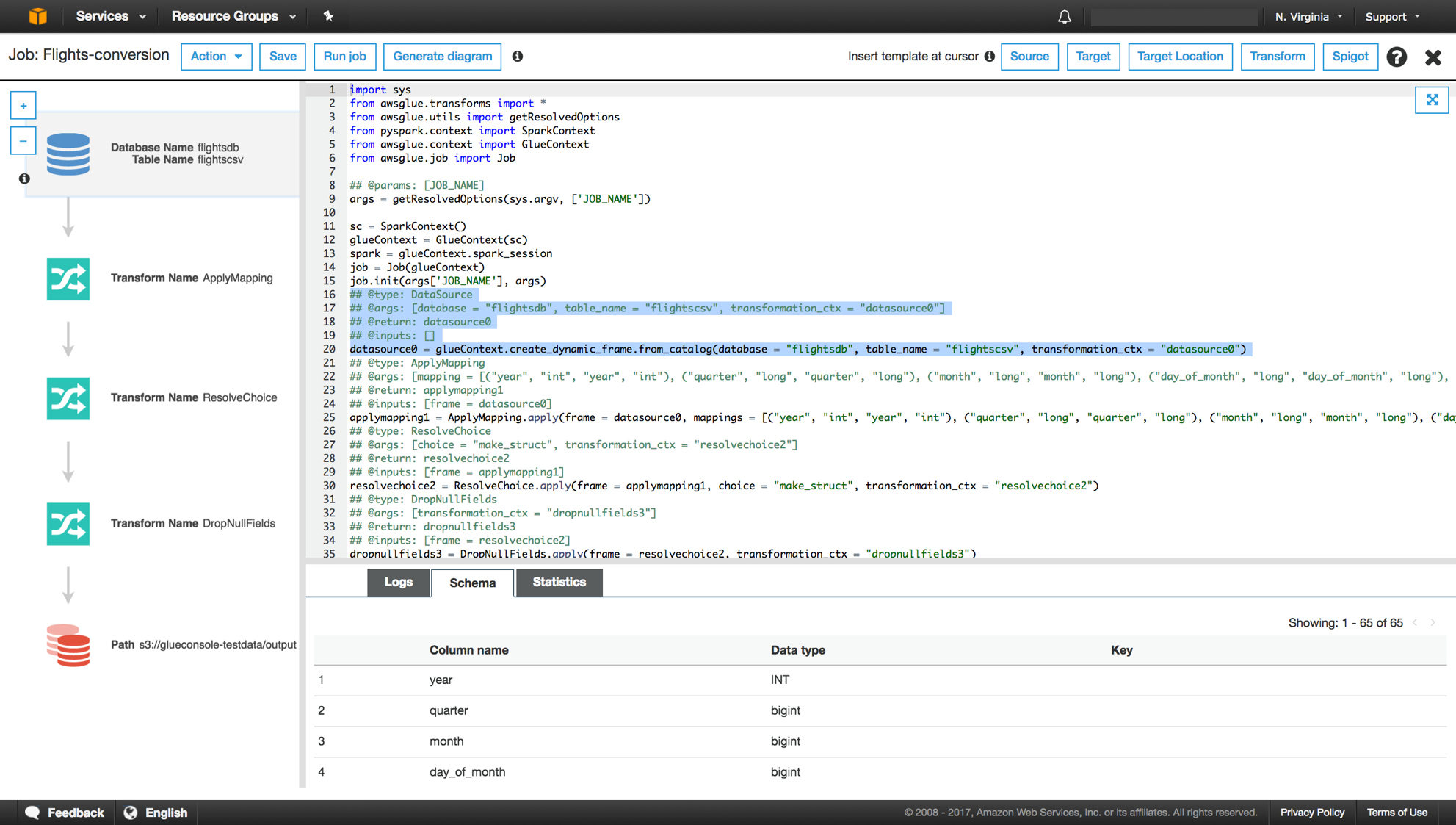
하지만 Glue ETL와 S3 Batch 서비스는 요금에 비해 활용도가 낮다고 생각한다. 먼저 Glue ETL은 위 그림과 같이 input과 output을 정의하고 그 사이에 transform 작업을 정의할 수 있다. Spark의 DataFrame을 기반으로 하며 DynamicFrame, Built-In Transform 등을 사용하여 스크립트를 작성한다. 서비스 중간에 추가되는 간단한 ETL Batch에 사용하기는 무난해보이지만 그게 아니라면 아래와 같은 사항들을 고려해야 한다.
Glue ETL은 DPU를 기준으로 요금이 계산된다
Glue ETL의 요금은 DPU라는 하나의 처리 단위를 기준으로 산정되는데 1 DPU는 4CPU와 16GB의 메모리를 가진다. DPU 시간당 0.44 USD, 초 단위로 청구되며 Apache Spark 유형 ETL 작업당 최소 시간은 10분이다. Spark 기반의 ETL에서는 Executor에 대한 설정이 중요하다. 작업에 따라 CPU가 많이 필요할 수도 있고 메모리가 많이 필요할 수도 있다. 하지만 Glue는 DPU라는 단위로 고정되어 있다보니 비용 효율적으로 사용하기 어려웠다. 만일 자체 클러스터를 사용하고 전체 파이프라인 내에서 리소스를 효율적으로 사용할 수 있다면 GlueContext가 뜨는 시간까지 고려했을때 정말 저렴한 서비스인지 잘 모르겠다.
Glue ETL은 디버깅, 모니터링 기능이 아직 부족하다
Spark에는 Spark UI 라는 휼륭한 모니터링 대시보드가 존재하지만 Glue에서는 아직 이를 지원하지 않는다. 대신 자체적으로 CloudWatch를 통해 메모리, 로그를 제공하는데 아직 지표가 많이 부족해보였다. DAG가 어떻게 구성되는지와 Shuffle 관련 지표도 볼 수가 없어 무거운 작업이라면 많은 노력이 필요하다. 아직 오픈한지 얼마 지나지 않은 서비스라 이 부분은 앞으로 많이 개선될거라 생각한다.
Step Function을 사용한 ETL Workflow 관리
Step Function은 Serverless 기반의 Workflow 서비스다. 여기에서는 가장 많이 사용하는 Airflow와 비교해가며 Serverless ETL이 가지는 특징을 설명해보려 한다.
Step Function은 ASL이라는 언어로 정의된다
Step Function에 들어가는 각 단계에는 Lambda, Fargate 등의 서버리스 서비스가 들어갈 수 있다. 그리고 각 단계는 Amazon States Language 라는 json 기반의 구조화된 언어로 정의된다. Airflow가 많이 사용되는 이유 중에 하나가 파이썬으로 DAG를 구성할 수 있다는 점인데 이에 비해 json 기반의 Step Function은 너무 복잡하게 느껴졌다.
Step Function에는 Operator, Sensor가 없다
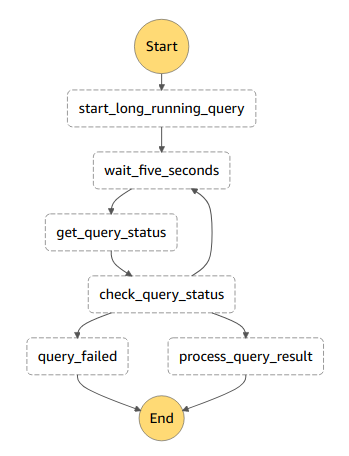
Lambda와 같은 서버리스 서비스는 수행에 대한 제한 시간이 존재한다. 각 단계가 대부분 람다 기반이다 보니 위 그림과 같이 Loop를 돌며 체크하는 패턴으로 Sensor를 구현한다. Airflow에는 리소스마다 미리 정의된 Operator, Sensor가 많지만 Step Function에서는 이를 다 구현해야 한다. 만일 Loop를 피하고 싶다면 Fargate로 Sensor를 구현할 수 있지만 Fargate는 요금이 많이 나온다.
정리하면서
쓰다보니 단점만 나열한 것 같아 보이지만 AWS 서비스와 요금은 지속적으로 업데이트 되기 때문에 나중에는 이러한 제한사항들이 해결될지도 모른다. 그리고 상황에 따라 적절히 사용한다면 장점이 많다. 그리고 서버리스가 아니라 언급하지 않았지만 Managed Cluster 서비스인 EMR을 사용해서 모두 해결하는 방법도 있다. 만일 Event 기반의 간단한 ETL 이라면 Serverless ETL이 가지는 장점을 크게 활용해보길 추천한다.