


Spark groupByKey vs reduceByKey
📅 August 22, 2017
•⏱️1 min read
Spark Application 성능 개선을 위한 groupByKey, reduceBykey에 대해 알아보겠습니다.
groupByKey vs reduceBykey
# reduceByKey
spark.textFile("hdfs://...")
.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
# groupByKey
spark.textFile("hdfs://...")
.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.groupByKey()
.map(lambda (w, counts): (w, sum(counts)))가장 흔히 알고 있는 word count 예제를 예로 들어보겠습니다. 위의 예시는 reduceByKey를 사용했으며, 아래의 예시는 groupByKey를 사용했습니다. 둘의 결과는 같지만 성능은 확인히 차이가 납니다.
먼저 위의 코드에서 flatMap, map 까지는 동일한 노드에서 실행이 됩니다.
하지만 reducer 부분에서는 모든 동일한 단어 쌍을 같은 노드로 이동시켜야 하기 때문에 Shuffle 이 발생합니다.
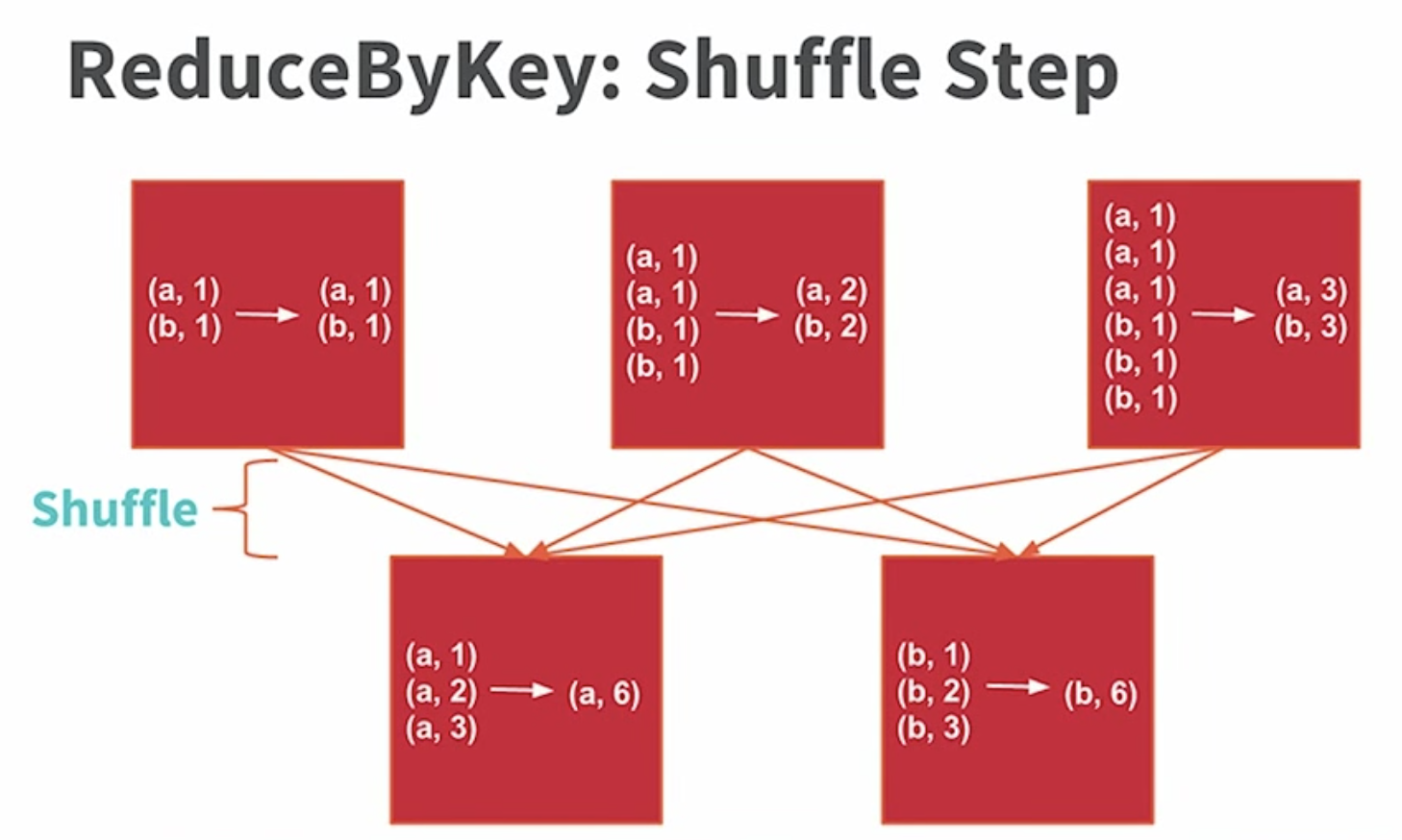
우선 reduceByKey의 경우, 먼저 각 노드에서 중간 집계를 진행하고 이에 대한 결과를 동일한 키 값으로 전송합니다.
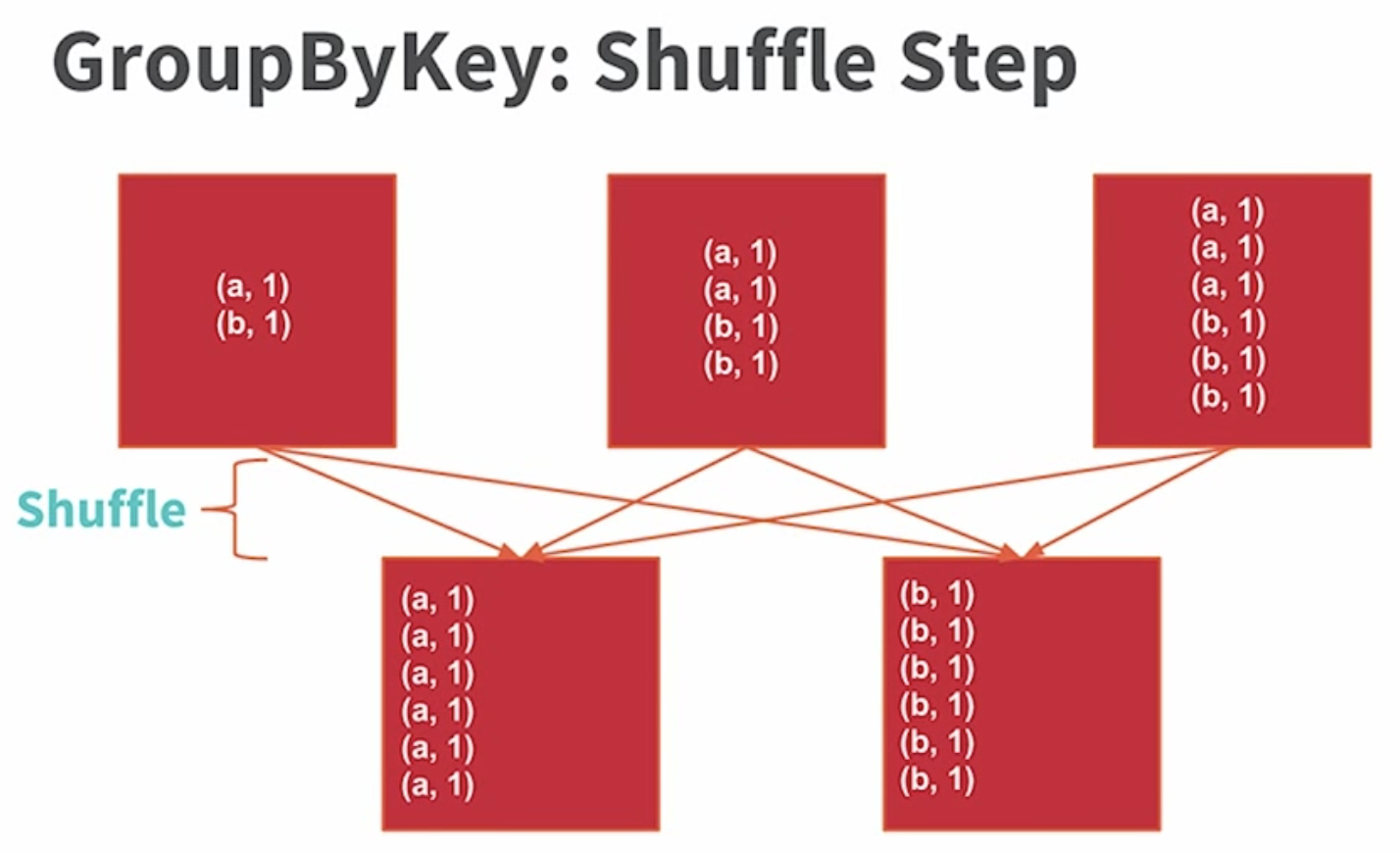
반면, groupByKey는 각 노드에 있는 데이터에 대해 바로 Shuffle 과정을 거치게 되고 결과를 내보냅니다. 따라서 groupByKey는 네트워크를 통해 전송되는 데이터의 양이 많아질 뿐만 아니라, Out of disk 문제가 발생할 수도 있습니다.
Shuffle은 기본적으로 비용이 큰 연산입니다. groupByKey는 reduceByKey로 대체될 수 있기 때문에 많은 문서에서 이를 권장하고 있습니다.