


Spark의 Shuffling 이해하기
📅 August 25, 2017
•⏱️2 min read
효율적인 Spark Application을 개발하기 위해 Shuffling 은 상당히 중요한 개념입니다. 이에 대해 간단히 정리해보았습니다.
Spark Architecture: Shuffle
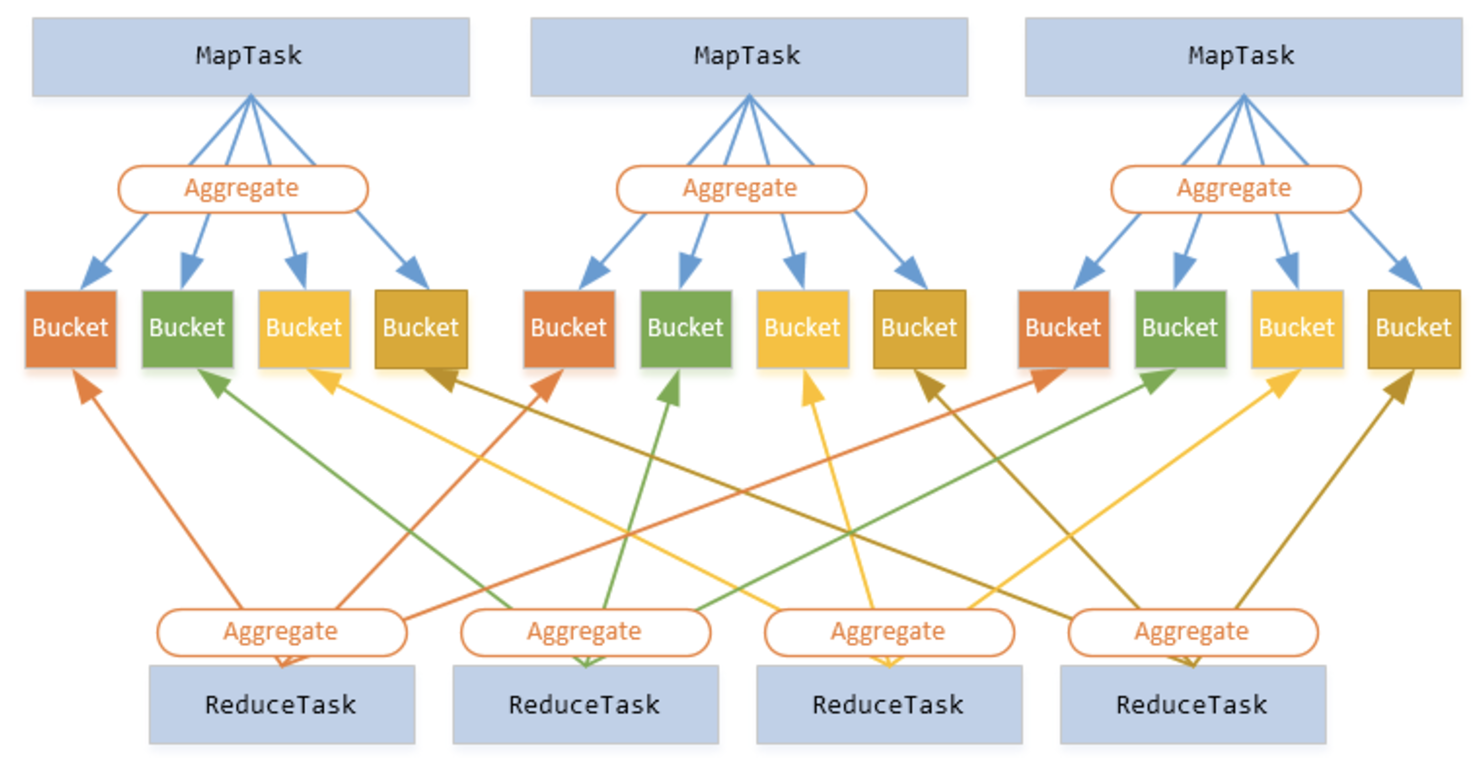
Shuffle을 설명하기 전에 한 가지 예시를 들어보겠습니다. 테이블에 전화 통화 기록 목록이 있고 매일 발생한 통화량을 계산한다고 가정 해보겠습니다. “날짜”를 키로 설정하고 각 레코드에 대해 값으로 “1”을 지정한 다음, 각 키의 값을 합산하여 결과 값을 계산할 수 있을 것 입니다.
만일 데이터가 여러 클러스터에 저장되어 있다면 어떻게 해야 동일한 키의 값을 합산할 수 있을까요? 이를 위한 유일한 방법은 같은 키의 모든 값을 동일한 시스템에 두는 것입니다. 그런 다음 이 값들을 합치면 됩니다.
Narrow and Wide Transformation
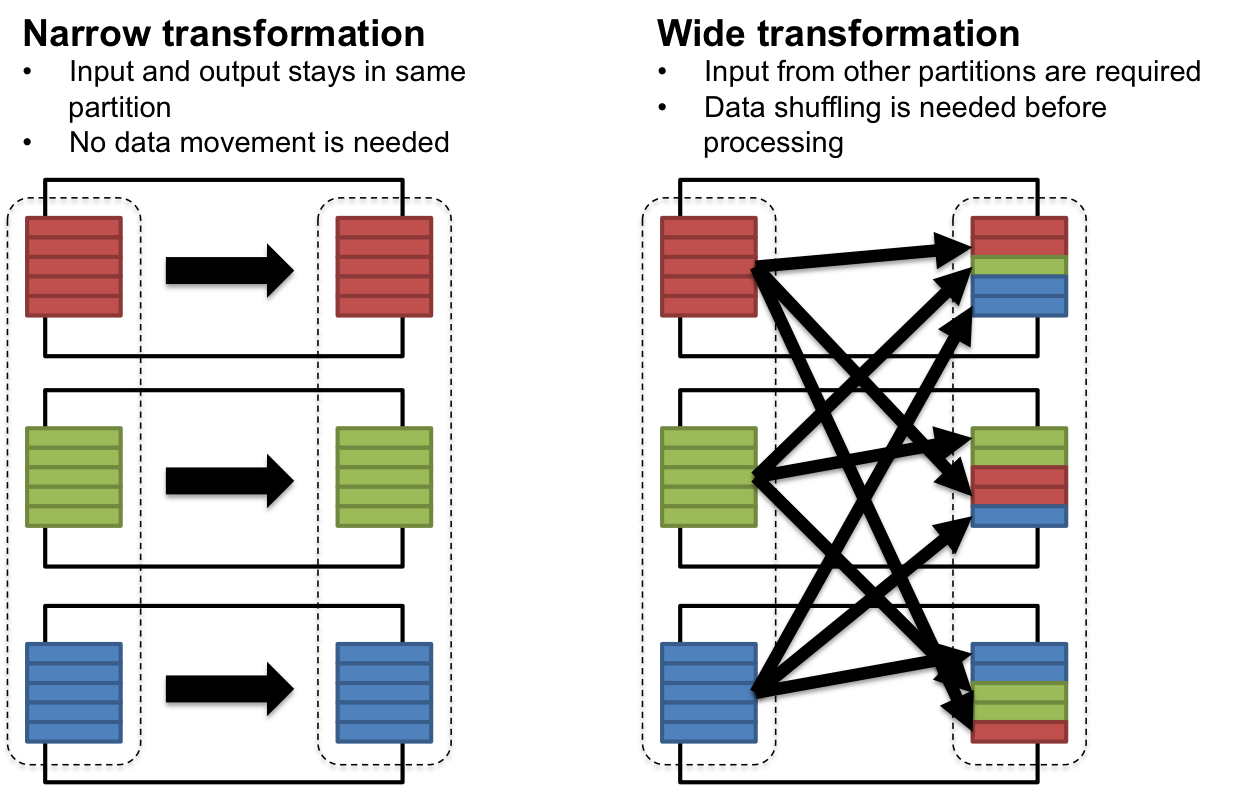
몇 가지 사례를 통해 더 자세히 알아보겠습니다.
만일 데이터가 이미 키 값으로 파티셔닝 되어 있고 키 값에 대해 변화를 주고 싶다면, 좌측의 그림처럼 수행하게 됩니다.
filter(), sample(), map(), flatMap() 등의 transformation이 이에 해당하며, 이 경우 Shuffle이 필요 없습니다.
이를 Narrow Transformation 이라고 합니다.
반면, 서로 다른 파티션으로부터 특정한 값을 기준으로 추출하고 싶은 경우, 그 값을 기준으로 Shuffle이 발생하게 됩니다.
groupByKey(), reduceByKey() 등이 이에 해당하며, 이를 Wide Transformation 이라고 합니다.
Shuffled HashJoin
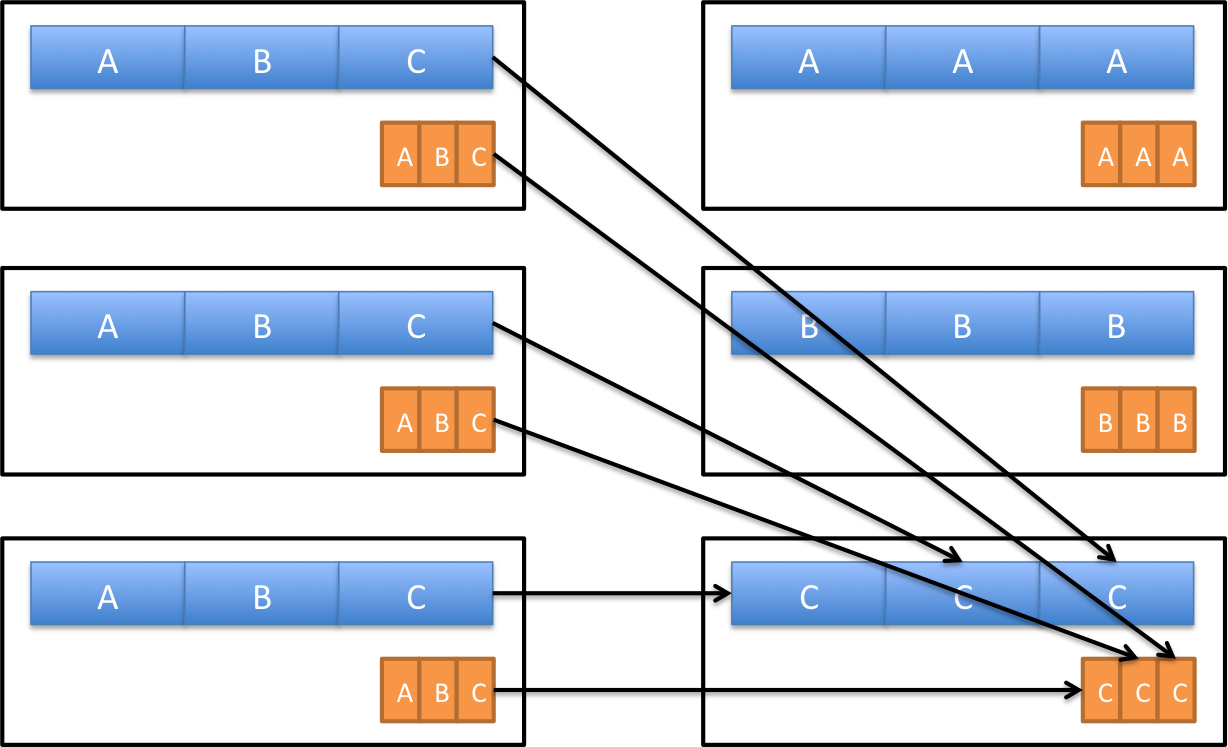
두 개의 테이블을 Join 할 때에도 Shuffle 이 발생할 수 있습니다.
위의 예시 처럼 두 테이블에서 키 값을 기준으로 Join 하게 되면, 동일한 키를 가진 데이터가 동일한 파티션으로 이동합니다.
하지만 이 때, 셔플 되는 데이터의 양이 성능에 영향을 미칠 수 있습니다. 만일 C의 데이터의 크기가 A보다 훨씬 크다면, C에 대한 작업으로 인해 전체의 수행시간이 오래 걸리게 될 것 입니다.
Broadcast HashJoin
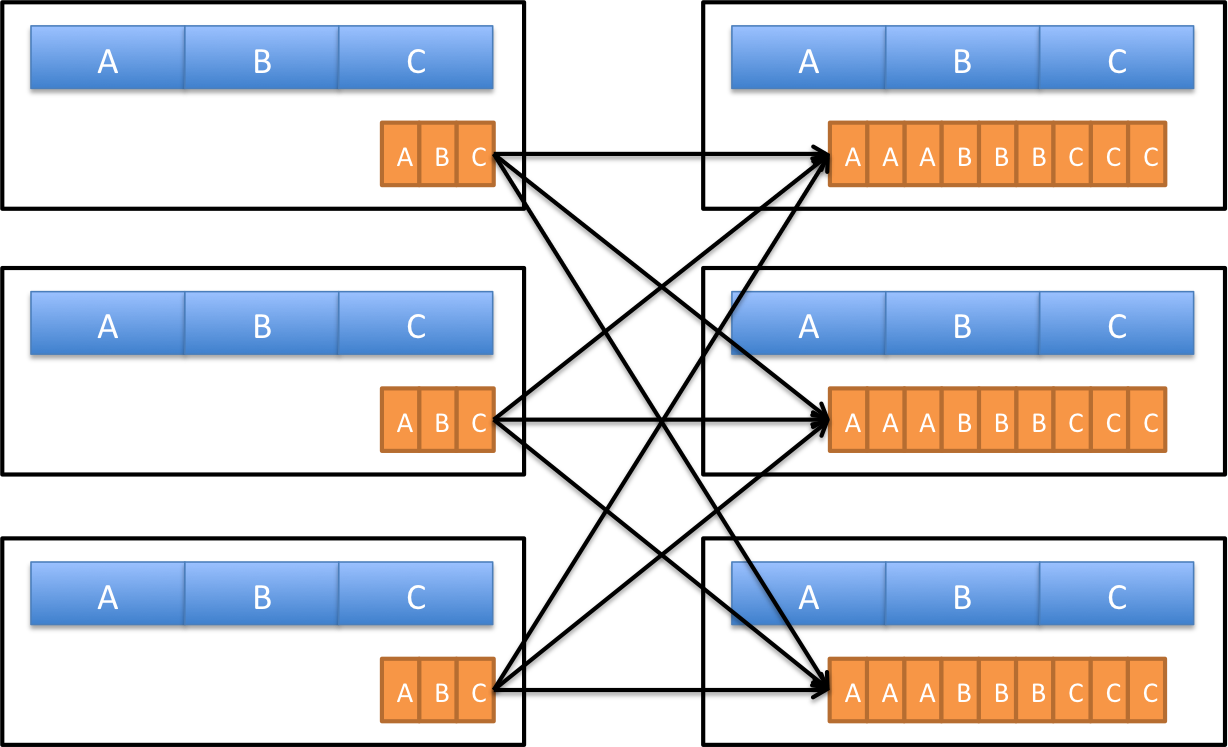
이를 개선하기 위해 Spark에서는 Broadcast Join 을 제공합니다. 이 경우 RDD 중 하나가 모든 파티션으로 브로드 캐스팅되며 복사됩니다. 만일 RDD 중 하나가 다른 것에 비해 상당히 작다면 큰 RDD가 전혀 셔플 할 필요가 없습니다. 작은 RDD 만 모든 작업자 서버에 복사해야 하므로 Broadcast Join은 전체적으로 네트워크 트래픽을 줄여주는 효과가 있습니다.
Spark 1.2에서는 spark.sql.autoBroadcastJoinThreshold 값을 설정해주어야 했지만,
2.0 이후 버전의 경우 Spark SQL이 알아서 최적화 잘 해줍니다.
Spark Shuffle Properties
spark.shuffle.compress: 엔진이 shuffle 출력을 압축할지 여부를 지정spark.shuffle.spill.compress: 중간 shuffle spill 파일을 압축할지 여부를 지정
Shuffle에는 위의 두 가지 중요한 Spark Property 가 있습니다.
둘 다 기본적으로 값이 “true”이며, spark.io.compression.codec 압축 코덱을 기본으로합니다.
그리고 위에서 설명한 것처럼 Spark에는 여러 가지 셔플 구현이 있습니다.
특정 구현에서 사용되는 Shuffle은 spark.shuffle.manager 값에 의해 결정됩니다.
가능한 옵션은 hash, sort, tungsten-sort 이며, “sort” 옵션은 기본적으로 Spark 1.2.0부터 시작합니다.
이외에도 Spark Shuffle 관련된 Property는 아래의 공식문서에서 확인하실 수 있습니다. https://spark.apache.org/docs/latest/configuration.html#shuffle-behavior
Reference
- https://0x0fff.com/spark-architecture-shuffle
- https://www.slideshare.net/databricks/strata-sj-everyday-im-shuffling-tips-for-writing-better-spark-programs