


데이터 파이프라인의 Write-Audit-Publish 패턴
📅 March 31, 2024
•⏱️3 min read
Write-Audit-Publish (WAP) 패턴이란, 데이터 엔지니어링 영역에서 데이터 품질과 안정성을 보장하기 위해 ETL에서 사용되는 설계 패턴입니다. 이번 글에서는 WAP 패턴을 알아보고 이를 통해 얻을 수 있는 장점에 대해 알아보겠습니다.
Write-Audit-Publish 패턴
오늘날 데이터 환경에는 데이터 생산자와 데이터 사용자가 존재합니다. 일부 데이터 생산자는 데이터 사용자에게 신뢰할 수 있는 데이터를 제공하기 위해 데이터 품질을 적용하고 있지만 이를 전체로 확산하는 것은 어렵습니다. 이러한 문제를 해결하기 위해 WAP 패턴은 데이터 사용자가 항상 신뢰할 수 있는 데이터에 접근하도록 보장합니다.
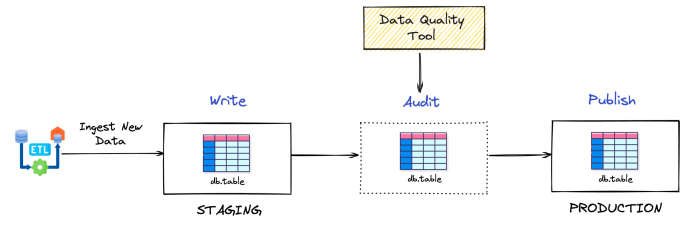
WAP 패턴은 다음과 같이 3단계로 구성되어 있습니다.
- Write: 데이터 소스로부터 처리한 데이터를 데이터 사용자가 접근할 수 없는 영역에 저장합니다. 임시 또는 스테이지 영역이 될 수 있습니다.
- Audit: 새로 생성된 데이터에 대해 품질 테스트를 수행하여 데이터를 검증합니다. 이 단계에서 NULL 값, 중복 데이터 식별, 참조 무결성 테스트 실행 등과 같은 부분을 확인합니다.
- Publish: 프로덕션 테이블에서 데이터를 사용할 수 있도록 배포합니다. Publish 단계는 테이블 사용자가 모든 변경 사항을 볼 수 있거나 전혀 볼 수 없도록 Atomic하게 이루어져야 합니다. 테이블 포멧을 통해 스냅샷을 만들고 병합하는 방식으로 이를 구현할 수 있습니다.
Write-Audit-Publish 패턴의 장점
Write-Audit-Publish 패턴을 통해 얻을 수 있는 장점은 다음과 같습니다.
데이터 무결성과 품질을 보장
WAP 패턴은 Audit 단계를 통해 데이터의 정확성, 품질, 표준화 준수 여부를 확인하여 불일치나 예외 사항을 모두 수정합니다. 이러한 검증 과정을 통해 신뢰할 수 있는 데이터 원본만 프로덕션에 게시되도록 보장합니다.
파이프라인의 신뢰성, 안정성 강화
Write, Audit, Publish 단계를 분리하면 오류 대응과 롤백 프로세스가 가능하다는 장점이 있습니다. 일반적인 소프트웨어 엔지니어링의 Blue-Green 배포는 언제든지 되돌릴 수 있으며 모든 트래픽을 새로운 버전으로 라우팅하는 구조를 가지고 있습니다. WAP 패턴도 Blue-Green 배포와 유사한 구조를 가지고 있어 데이터 파이프라인의 전반적인 신뢰성과 안정성이 강화됩니다.
데이터 보안 강화
여러 단계를 통해 구조화된 패턴은 원천 데이터와 감사된 데이터를 분리하여 민감하고 검증되지 않은 정보를 조기 노출로부터 보호하는 보안 계층을 제공합니다. 이를 통해 데이터 보안을 유지하는데 도움을 줄 수 있습니다.
WAP with Apache Iceberg
Apache Iceberg 테이블 포멧에서는 공식적으로 WAP 패턴을 구현하는 데 필요한 Branching 기능을 지원하고 있습니다. Branching 기능을 통해 Git의 Branch와 같이 분기를 통해 데이터 테스트 환경과 운영 환경을 격리할 수 있습니다. Iceberg에서 Branch는 테이블의 특정 시점을 가리키는 스냅샷과 동일하며 Branch에 데이터 쓰기를 수행할 수 있습니다. WAP 패턴에 적용하는 경우, 작업 절차는 다음과 같습니다.
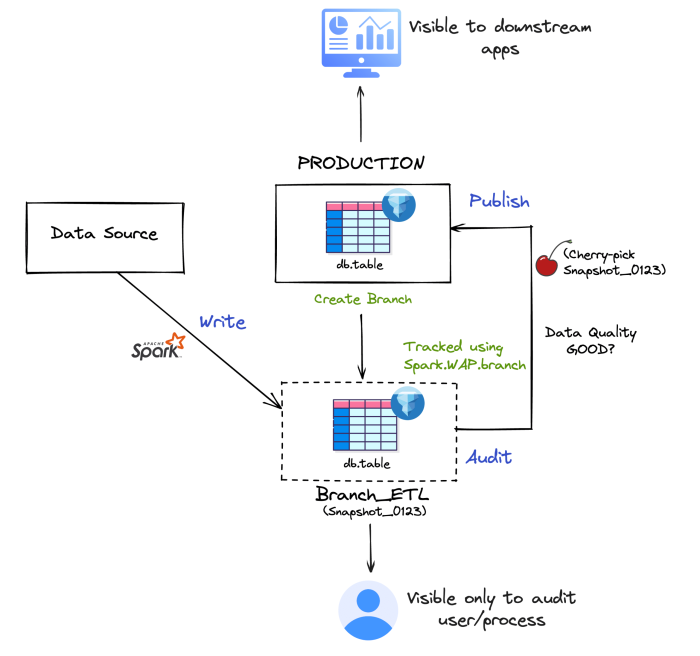
Write:
기존 Iceberg 테이블에서 새로운 작업 Branch를 생성하고 새로 작성된 ETL 변경 사항을 Branch에 반영합니다. 예시에서는 feature-0305 라는 이름의 Branch를 사용하겠습니다.
ALTER TABLE db.table SET TBLPROPERTIES (
'write.wap.enabled'='true'
);
ALTER TABLE db.table CREATE BRANCH feature-0305 RETAIN 7 DAYS;
SET spark.wap.branch = feature-0305;
INSERT INTO db.table VALUES (3, 'c');Audit:
Branch에서 필요한 품질 테스트를 수행합니다.
이 단계에서는 Great Expectations와 같은 Data Quality 도구를 활용할 수 있습니다.
Publish:
프로덕션 테이블에 새로운 데이터를 배포합니다. 반영이 완료되고 안정성이 확인되면 작업 Branch는 삭제합니다. Publish 작업은 기본적으로 원본 데이터를 변경하거나 제거하지 않고 기존 스냅샷에서 새 스냅샷을 생성하는 Iceberg의 cherry-pick procedure에 의해 실행됩니다.
CALL catalog_name.system.cherrypick_snapshot(
'db.table', 'main', 'feature-0305'
);
ALTER TABLE db.table DROP BRANCH feature-0305;만약 Iceberg 1.2 이전 버전을 사용한다면 WAP.id property를 사용해야합니다.
Reference
Write-Audit-Publish 패턴을 통해 대규모 데이터를 처리할 때 프로덕션 워크로드에 영향을 주지 않고 격리된 품질 테스트 및 검증을 수행할 수 있습니다. 데이터 품질 커버리지를 확대하고자 할 때 WAP 패턴을 고려해보시면 좋을 것 같습니다. 그리고 Iceberg와 같은 테이블 포멧을 사용한다면 더 나은 개발 경험을 제공할 수 있습니다.