


Why Kubeflow in your Infrastructure?
📅 March 09, 2019
•⏱️2 min read
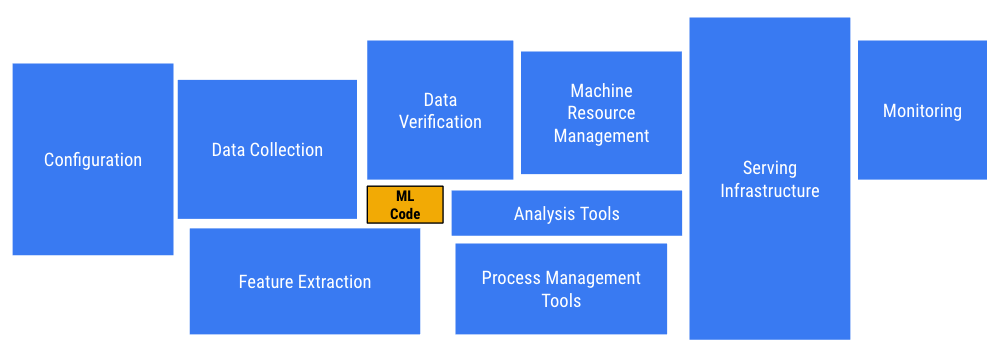
실제 ML을 서비스에 적용시키는 일은 위 그림에 나타난 바와 같이 ML 모델링 보다 이외의 작업들이 많이 필요합니다. 특히 서비스의 여러 기능에 ML을 적용시키려 하는 경우, 이러한 파이프라인이 복잡해지고 유지보수가 힘든 방향으로 가는 경우가 많습니다. 이러한 이유로 규모있는 IT 서비스 회사들은 공통의 ML 플랫폼을 구축하곤 합니다.
앞으로 소개하려는 Kubeflow는 Kubernetes를 기반으로 하는 오픈소스 ML Toolkit 입니다. 아직 버전이 낮아 production 환경에서 사용하는 곳이 많지 않지만 미리 알아두면 좋을 것 같아 컴포넌트들을 하나씩 분석해보려 합니다.
- Why kubeflow in your Infrastructure
- Amazon EKS에 Kubeflow 구축하기
- Kubeflow의 ModelDB
- Kubeflow의 Hyper parameter Tuning (Katib)
Why Kubeflow?
이미 기존의 인프라를 기반으로 자동화된 ML Workflow가 구축되어 있다면, 굳이 Kubeflow로 옮길 필요는 없습니다. 하지만 아래와 같은 상황을 가진 팀이라면 Kubeflow는 좋은 선택지가 될 수 있습니다.
- 이미 Kubernetes 기반의 인프라를 사용하고 있으며, ML 인프라를 구축하려는 경우
- 서비스를 On-premise, Multi-cloud 환경에 배포해야 하는 경우
- Scalable ML이 필수적이며, 기존의 여러 ML 서비스를 쉽게 배포하고 리소스 관리 비용을 줄이려는 경우
- Research Engineer, Data Scientist 를 위한 인프라 관리의 복잡성을 최소화하고 일관된 인터페이스를 제공하여 몇 번의 클릭만으로 설정을 쉽게 하고 싶은 경우
Consistency in Infrastructure
Kubeflow는 Kubernetes 기반의 인프라가 가지는 장점을 그대로 가지고 있습니다. 각 서비스에 대한 Monitoring, Health Check, Replication 등의 기본 요구사항을 갖추고 있으며 쉬운 배포 환경을 제공합니다. 이외에도 아래와 같은 usecase에서 활용될 수 있습니다.
- Research Engineer들이 인프라가 아닌 모델링에만 집중할 수 있는 환경을 제공할 수 있습니다. 모두가 Docker 기반의 추상화된 환경에서 연구를 할 수 있으며, 동일한 데이터, 연구 결과를 공유할 수 있습니다. 가상화된 GPU 환경에서 모델을 분산 학습시킬 수 있으며, TensorFlow, PyTorch, MXNet 등 다양한 프레임워크 환경을 지원할 수 있습니다.
- Kubeflow는 end-to-end를 제공하기 때문에 ML 프로젝트를 production에 반영하는 과정이 단순해집니다. 지속적인 데이터 파이프라인을 구축하여 argo를 통해 모델을 업데이트 하고, seldon을 통해 production 환경을 테스트해 볼 수 있습니다.
- Katib을 통해 Hyper parameter tuning 과정을 쉽게 자동화 할 수 있습니다. Katib에서 제공하는 인터페이스를 통해 여러 어플리케이션으로 확장시킬 수 있으며, 튜닝 결과를 지속적으로 기록하고 공유할 수 있습니다.
Resource utilization by the Training / Serving modules
테스트 환경을 쉽게 구축할 수 있으며, 클라우드 비용을 최적화시킬 수 있습니다. K8S 클러스터는 동일한 인스턴스에 여러 Pod을 실행시킬 수 있습니다. 따라서, 사용하는 리소스를 팀 또는 프로젝트 단위로 namespace를 분리시켜 리소스 사용량을 모니터링 할 수 있습니다.
일반적인 클라우드 인프라 환경을 서비스 라이프사이클과 연계되어 있지 않기 때문에 training job이 끝난 이후에도 인스턴스가 켜져 있기 때문에 그에 대한 비용을 지불해야 합니다. 하지만 Kubeflow를 사용하는 경우, 사용량에 따라 클러스터를 auto scaling 한다거나 spot instance로 training job을 실행시킬 수 있습니다.