


분산 컨테이너 환경에서의 디자인 패턴 (3)
📅 April 06, 2019
•⏱️3 min read
구글 클라우드 팀이 Kubernetes와 같은 Container Orchestration 기술을 개발하면서 겪은 분산 컨테이너 환경에서의 디자인 패턴에 대해 정리한 내용입니다. 지난 글에 이어서 배치 작업에 관련된 디자인 패턴에 대한 내용입니다.
- 분산 컨테이너 환경에서의 디자인 패턴 1. Single-Node Patterns
- 분산 컨테이너 환경에서의 디자인 패턴 2. Multi-Node Serving Patterns
- 분산 컨테이너 환경에서의 디자인 패턴 3. Batch Computational Patterns
Batch Computational Patterns
앞서 설명했던 long-running computation 패턴과 달리 이번에는 일시적으로 돌아가는 Batch Computational 패턴에 대한 내용이다. 배치 프로세스는 사용자 로그 데이터의 수집, 데이터 분석 또는 미디어 파일의 변환 등에 자주 사용된다. 일반적으로 대용량 데이터의 처리 속도를 높이기 위해 병렬 처리를 사용한다는 특징이 있다. 이에 대해 가장 유명한 패턴은 MapReduce 패턴이며 이미 많이 사용하고 있다.
Work Queue Systems
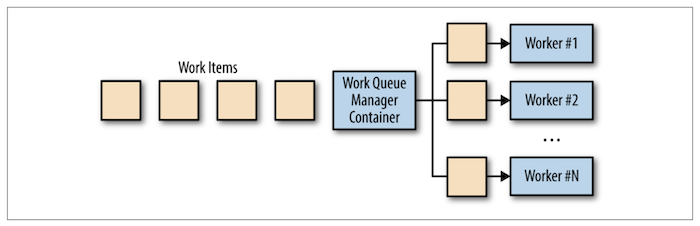
배치 프로세싱의 가장 간단한 형태가 바로 Work Queue System 이다. Queue 형태의 작업 대기열이 있고 이를 관리해주는 컨테이너가 Worker에 작업을 분배해주는 형태이다. 일반적으로 작업 대기열에서 각 작업은 일정 시간 내에 수행되어야 하며 처리량에 따라 Worker는 Scale-out 할 수 있어야 한다. 작업이 지속적으로 지연된다면 큐에 작업이 계속 쌓이게 되고 이는 장애로 이어질 수 있다.
Source, Worker Container Interface
- Source 컨테이너와 Worker 컨테이너에 대한 인터페이스가 필요
- 작업 대기열 스트림을 제공하는 컨테이너와 실제로 작업을 처리하는 컨테이너를 분리
- Source 컨테이너가 Ambassador 역할을 수행 (Storage, Network, Kafka/Redis Queue에 대한 통신을 맡음)
- 현재 대기열에 쌓인 작업 리스트, 작업에 대한 구체적인 정보를 알려주는 Work Queue API 구현 필요
- 작업에 대한 설정 정보는 Kubernetes의 ConfigMap과 ConfigMapVolume을 활용해서 구현
- Worker 컨테이너는 Rolling Update, Dynamic Scaling 기능이 필요
- Work Queue, Worker Process에 대한 모니터링이 필요
Event-Driven Batch Processing
앞서 설명한 작업 대기열 처리는 하나의 입력을 하나의 출력으로 변환할 때 많이 사용한다. 하지만 단일 작업 이상을 처리해야 한다거나 단일 입력에서 여러 출력을 생성해야 하는 경우도 있다. 이러한 경우 여러 작업 대기열을 연결하는 이벤트 스트림 방식을 통해 작업을 수행한다. 이전 단계의 작업이 완료되면 이벤트가 발생하고 이벤트를 통해 다음 단계의 대기열로 이동하는 형태이다.

스트림 처리에 대한 여러 패턴이 존재하지만 위 그림은 그 중 하나인 Sharder에 대한 내용이다. Sharder는 작업 큐 2개를 두고 만일 두 개의 큐가 모두 healthy 하다면, id 기준으로 작업을 분배한다. 만일 어느 하나가 unhealthy 하다면, 새로운 큐를 생성해서 다른 한쪽으로 작업을 분배한다. 이를 통해 단일 큐를 사용하는 것보다 안정적이고 작업을 분산처리할 수 있다.
이외에도 Publisher/Subscriber, Merger, Splitter 등의 패턴이 있다. Spark의 DAG와 같은 그림을 떠올린다면 어떤 내용인지 바로 이해할 수 있을 것이다. 처리 시간이 비교적 짧은 이벤트 기반의 배치 프로세싱은 앞서 소개했던 FaaS 패턴으로 구현할 수도 있다. AWS의 Lambda, Stream, Kinesis Firehose를 떠올리면 된다.
Coordinated Batch Processing
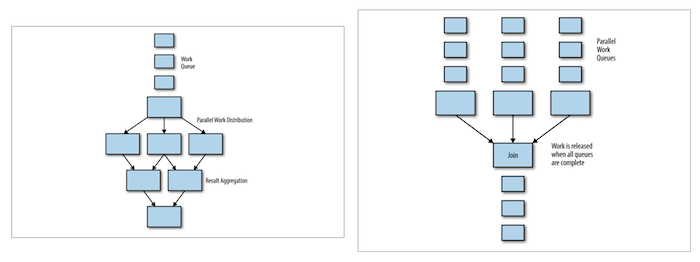
처음에는 단일 대기열로 처리했지만 더 복잡한 배치 작업을 처리하기 위해 대기열을 분할하고 연결했다. 하지만 최종 단계에서는 결국 원하는 결과를 생성하기 위해 여러 출력을 하나로 합쳐야 한다. 합치는 작업은 여러 개의 작업 큐가 모두 종료되고 난 이후에 수행되어야 한다. 이와 관련된 패턴으로 Join과 Reduce가 있다. Join과 달리 Reducer의 경우 parallel 하게 시작할 수 있다는 차이가 있다. count, sum, histogram을 추출하는 작업이 이에 해당한다.
Reference
책을 마무리할 무렵 Kubernetes Korea Group 세미나에서 책 저자의 발표를 들을 수 있었다. 다른 컨퍼런스에서 진행했던 발표들과 내용이 유사했고 Azure Kuberentes Service에 대한 홍보가 짙었지만 클라우드 네이티브와 최근 개발 환경의 변화에 대한 생각을 들을 수 있는 시간이었다.
그동안 개발할 때 정형화 된 패턴을 공부하지 않았음에도 비슷한 형태로 설계된 경우를 많이 볼 수 있었다. 하지만 패턴을 한번 정리하고 나면 더 명확하게 이해되고 현재 상황에 맞는 패턴을 적용할 수 있게 되는 것 같다. 마틴 파울러의 리팩토링 책도 그렇고 이번 책 또한 그런 부분을 느낄 수 있었다.
- GooglePaper - Design patterns for container-based distributed systems
- Designing Distributed Systems: Brendan Burns