


분산 컨테이너 환경에서의 디자인 패턴 (2)
📅 March 23, 2019
•⏱️5 min read
구글 클라우드 팀이 Kubernetes와 같은 Container Orchestration 기술을 개발하면서 겪은 분산 컨테이너 환경에서의 디자인 패턴에 대해 정리한 내용입니다. 지난 글에 이어서 멀티 노드에 관련된 디자인 패턴에 대한 내용입니다.
- 분산 컨테이너 환경에서의 디자인 패턴 1. Single-Node Patterns
- 분산 컨테이너 환경에서의 디자인 패턴 2. Multi-Node Serving Patterns
- 분산 컨테이너 환경에서의 디자인 패턴 3. Batch Computational Patterns
Multi-Node Serving Pattern
지난 번에 소개했던 싱글 노드 패턴들은 컨테이너 간에 커플링이 강하다는 특징이 있다. 반면 이번에 소개할 멀티 노드 패턴들은 컨테이너 간에 커플링이 약하다. 서로 다른 노드 간에 네트워크 호출을 통해 통신이 이루어지며 Parallel, Coordinate via loose synchronization에 대한 이슈가 존재한다. 특히 어플리케이션이 MSA 아키텍쳐로 구성된 경우, 컨테이너 간의 커플링이 낮다보니 스케일링에 이점이 있다. 하지만 여러 노드에서 복잡한 구조로 동작하다보니 디버깅이 어려울 수 있다.
Replicated Load-Balanced Services
LoadBalancer가 트래픽을 관리하는 패턴이다. 가장 간단하면서 잘 알려져 있다. stateless한 서비스의 경우, LoadBalancer + Replica 형태로 쉽게 구성할 수 있다. 처리해야 하는 요청에 따라 Scale-Up, Down을 쉽게 구성할 수 있어야 한다.
- LoadBalancing 패턴은 서비스의 network layer에 해당 (TCP/IP)
- Caching Layer는 web 서비스에서 유저의 요청을 메모리에 캐싱하는 프록시
- Caches Server에서 유저의 요청을 캐싱하고 있기 때문에 2번 요청을 보내더라도 실제 서버에는 1번만 요청
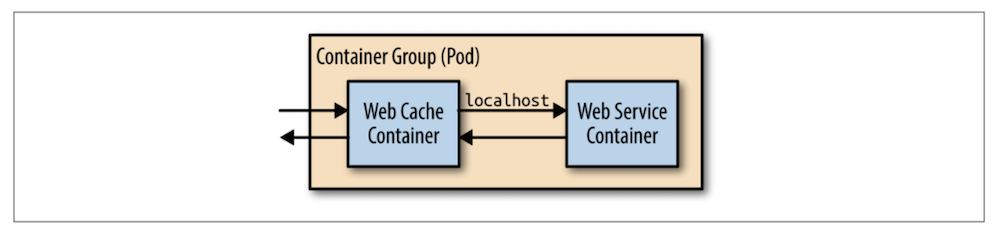
가장 간단하게 웹 서버와 캐시 서버를 구성하는 방법은 위 그림과 같이 앞서 배웠던 Sidecar를 활용하는 방법. 이 방법은 간단하게 구현할 수 있지만 내 웹 서버와 동일한 레벨에 있기 때문에 각자 스케일링하기 어렵다. Kubernetes의 Deployments와 Service로 동일한 환경을 쉽게 구성해볼 수 있다.
Shared Services
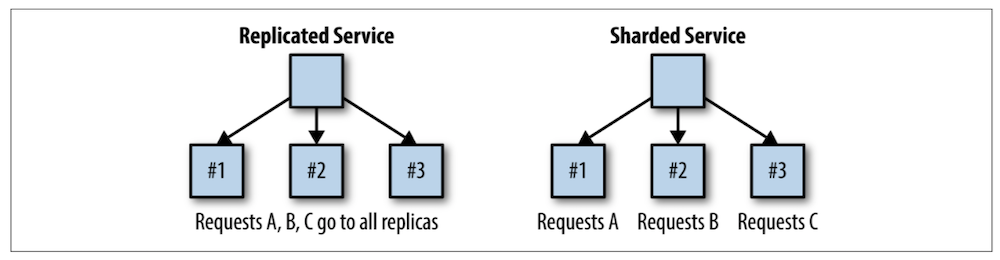
위의 Load-Balanced Services가 stateless 하다면 shared service는 stateful. Replicated Service에서는 각 Pod에서 모두 동일한 요청을 처리하고, Shared Service에서는 root가 routing 해주면서 서로 다른 요청을 처리한다.
- 앞의 글에서 ambassador 패턴을 활용해 shared cache를 만드는 예제의 응용편
- 요구사항: Cache Proxy에서 적절한 Cache Shard로 라우팅해주어야 한다
- cache hit, miss에 대한 처리 결과를 노드 사이에서 통신
- sharding은 single node에 들어갈 수 없을 정도의 데이터 사이즈가 있는 경우에 장점
- 네트워크 latency와 데이터 등을 파악해서 적절한 아키텍쳐를 구성하는 것이 중요
Scatter, Getter
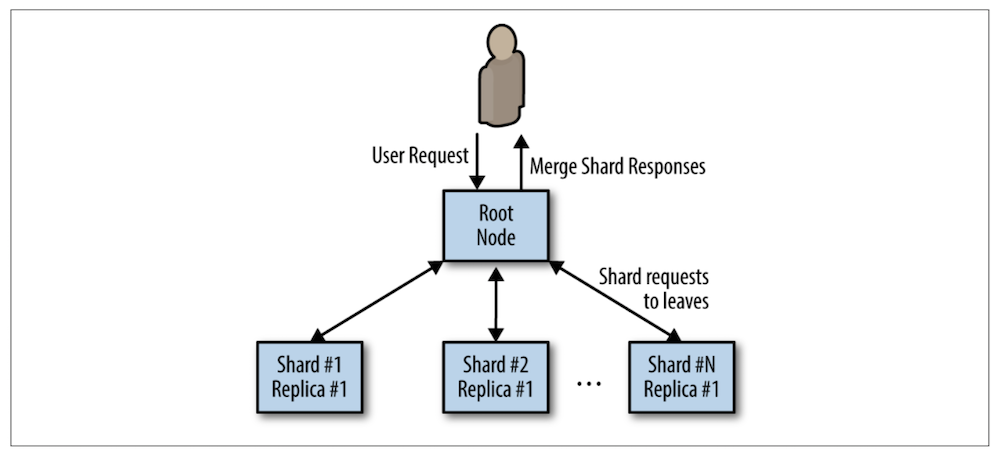
scatter, getter 패턴은 스케일링, 분산처리에 유용한 패턴 중 하나이다. 위에 언급했던 패턴들처럼 트리 구조로 되어 있고, root 서버가 요청을 분산시키거나 여러 서버로부터 받아오는 구조. 이 패턴은 분산처리에서 embarassingly parallel 문제를 해결하는 것과 동일하다.

Hands On: Distributed Document Search
모든 문서 파일로부터 cat, dog 단어가 모두 포함되어 있는지 검색하는 문제를 풀어야 한다고 가정해보자. 왼쪽 그림과 같이 각 노드로부터 서로 다른 단어를 검색하고 결과를 내는 방법이 있다. 하지만 document 하나의 사이즈가 아주 크다면? 하나의 노드에서 처리는 불가능하다. 이 경우, 단어 기준이 아니라 document 기준으로 분산처리해야 한다. (MapReduce의 WordCount 예제와 동일)
이 때 적절한 노드 개수를 선정하는 것이 중요하다. (컴퓨팅과 비용 사이의 문제) 노드가 많아질수록 요청을 분산하고 수집하는데 오버헤드가 발생할 수 있다. 위 경우 처리가 가장 오래걸리는 노드의 시간이 전체 처리 시간을 결정할 것이다. (straggler problem) 이를 해결하기 위해 Erasure Coding을 통해 연산을 추정하는 방법도 있다.
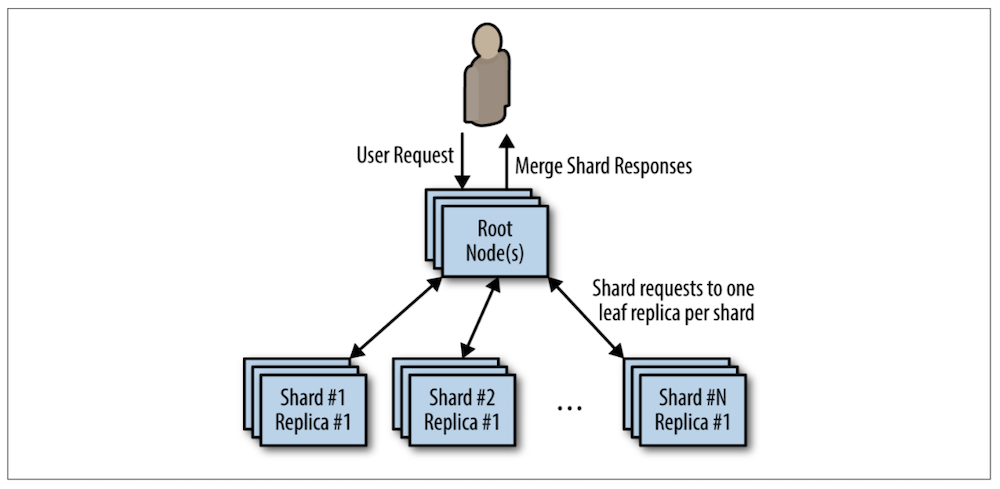
Scaling Scatter/Gather for Reliability and Scale
항상 실패에 대한 대비가 되어 있어야 한다. (Fault Tolerance) 앞서 설명한대로 단순히 샤드의 수를 늘리는 것은 적절하지 못한 방법이다. 각 Shard가 Replica로 구성되어 있기 때문에 동시에 업그레이드도 가능할 수 있어야 한다.
Functions and Event-Driven Processing
방금 전까지는 long-running computation에 대한 패턴에 대해 소개했다면, 이번에는 FaaS 기반의 일시적인 서비스에 대한 패턴에 대한 내용이다. (serverless computing) 서버리스는 좋은 패턴이자 도구이지만 모든 어플리케이션에 무조건 적용하기 보다는 장점과 단점을 잘 이해하고 적절한 경우에 사용하는 것이 좋다.
- 함수 단위로 모듈화하고 바로 클라우드를 통해 서비스할 수 있다는 장점
- 각 서비스가 완전히 독립적이어야 하고 상태를 스토리지에 저장해야 하기 때문에 운영이 복잡해질 수 있음
- 함수 사이에 루프가 생기는 경우, 심각한 문제가 발생 (모니터링 필수적임)
- Event-Driven의 우선순위가 낮은 일시적인 작업을 처리할 때 유용함
- 인메모리 수준의 빠른 처리가 필요한 경우, 함수가 로드되는 오버헤드를 고려하면 부적합 할 수 있음
- 가끔씩 수행되어야 하는 경우, 비용 측면에서 일반 인스턴스보다 저렴
- FaaS는 아주 간단한 Code Snippet으로 쉽게 구현할 수 있음
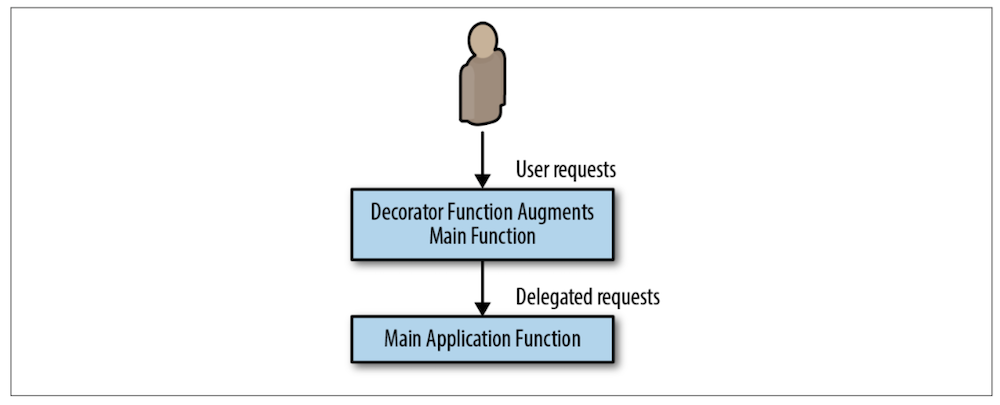
FaaS Decorator Pattern: Request or Response Transformation
Input이 들어왔을 때, transform 해서 output을 내는 패턴이다. 이번에는 Kubernetes 기반의 serverless 플랫폼인 kubeless로 간단한 예제를 진행해보았다. 설치와 실행은 아래와 같이 진행하면 된다. 예제 코드와 이에 대한 자세한 설명은 https://github.com/Swalloow/KubeStudy/tree/master/faas 에서 확인.
# install kubeless, cli
kubectl create ns kubeless
kubectl create -f https://github.com/kubeless/kubeless/releases/download/v1.0.3/kubeless-v1.0.3.yaml
curl -OL https://github.com/kubeless/kubeless/releases/download/v1.0.3/kubeless_darwin-amd64.zip
unzip kubeless_darwin-amd64.zip
sudo mv bundles/kubeless_darwin-amd64/kubeless /usr/local/bin/
# install kubeless UI
kubectl create -f https://raw.githubusercontent.com/kubeless/kubeless-ui/master/k8s.yaml
kubectl get svc ui -n kubeless
kubectl port-forward svc/ui -n kubeless 3000:3000Hands On: Implementing Two-Factor Authentication
- Random Code Generator를 비동기로 생성
- 로그인 서비스에 코드를 등록
- 사용자의 전화로 문자메세지를 전송
Hands On: Implementing a Pipeline for New-User Signup
- 이벤트 기반의 파이프라인 예제
- MSA는 long-running 인 반면, Event Pipeline은 async, short-running
- 빌드, 배포 CI 도구가 좋은 예제 (각 단계의 이벤트가 발생하면 함수 실행)
- 유저가 신규 가입하면, welcome 이메일 전송하는 예제
- A list of required actions (e.g., sending a welcome mail)
- A list of optional actions (e.g., subscribing the user to a mailing list)
9. Ownership Election
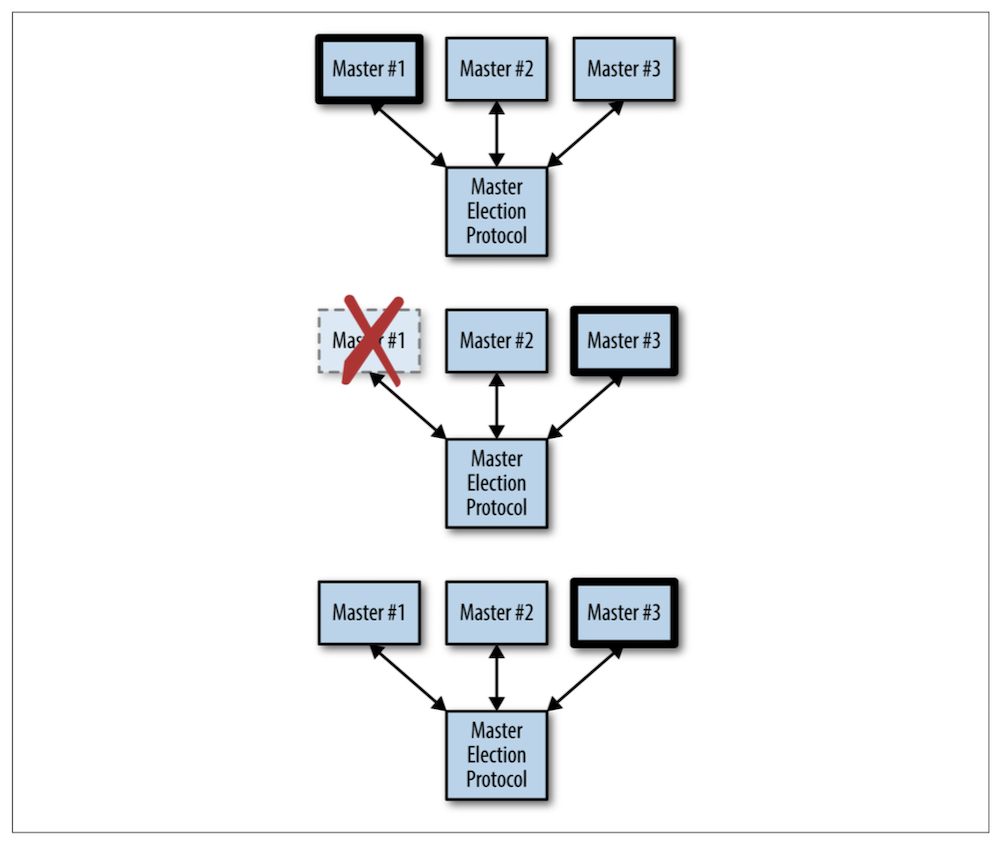
분산 시스템에서는 Ownership을 결정하는 것이 중요하다. 리더가 여러 책임을 가지고 있다. 마스터 노드에 장애가 발생하더라도 Election에 의해 새로운 마스터 노드를 선정할 수 있어야 한다.
Determining If You Even Need Master Election
- 노드가 안정적으로 영원히 돌아갈리가 없기 때문에 필요
- singleton container로 구현하는 방법도 있음
- 컨테이너에 장애가 발생해도 재시작 가능
- health check를 구현했다면, hang에 걸려도 재시작
- 노드에 장애가 발생하면 다른 노드로 이전
- 하지만 이 방법은 uptime이 발생할 수 밖에 없음 (2초~5분 간 서비스 정지)
- 노력하면 uptime을 일부 줄일 수 있겠지만 그 만큼 복잡성이 증가
The Basics of Master Election
가장 잘 알려진 Leader Election 알고리즘으로 Paxos와 Raft가 있다. 자세한 내용은 이전에 작성한 Raft Consensus 글을 참고.
Reference
- GooglePaper - Design patterns for container-based distributed systems
- Designing Distributed Systems: Brendan Burns