


Data Mesh 아키텍쳐의 네 가지 원칙
📅 September 25, 2021
•⏱️5 min read
이 글은 martinfowler.com의 Data Mesh Principles and Logical Architecture 원문을 정리한 내용입니다. Data Mesh 아키텍쳐의 네 가지 원칙에 대한 내용은 How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh의 후속글 입니다.
The great divide of data
오늘 날의 데이터 환경은 운영 데이터 영역과 분석 데이터 영역으로 나누어 볼 수 있습니다. 운영 데이터는 주로 마이크로서비스에서 사용하는 데이터베이스에 해당하며 트랜잭션과 비즈니스 요구사항을 담고 있습니다. 분석 데이터는 특정 시간 경과에 따라 집계된 비즈니스 데이터이며 주로 BI / 분석 리포트나 ML 모델링에 사용됩니다.
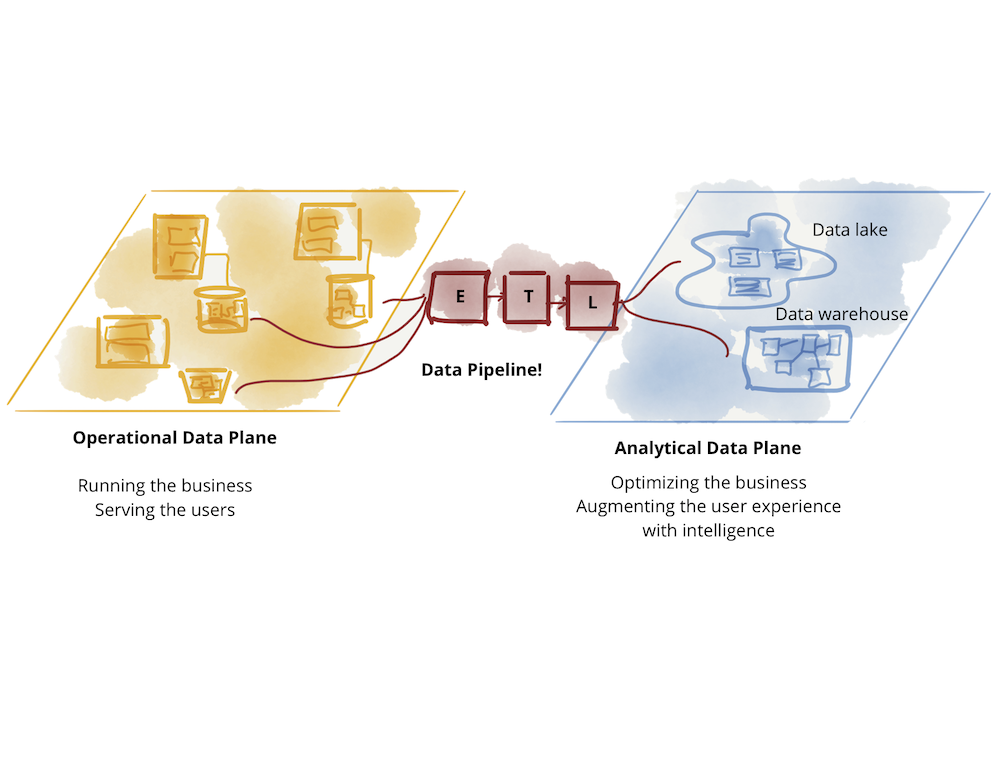
데이터 아키텍쳐와 조직 구조 또한 두 가지 데이터 영역을 반영합니다. 운영 환경으로부터 데이터를 가져오고 ETL 프로세스를 거쳐 분석 데이터를 생성합니다. 그리고 분석 데이터를 또 다시 운영 환경에 활용하는 경우가 많습니다. 이러한 데이터 흐름은 빈번한 ETL 프로세스의 실패와 복잡한 파이프라인으로 이어졌습니다.
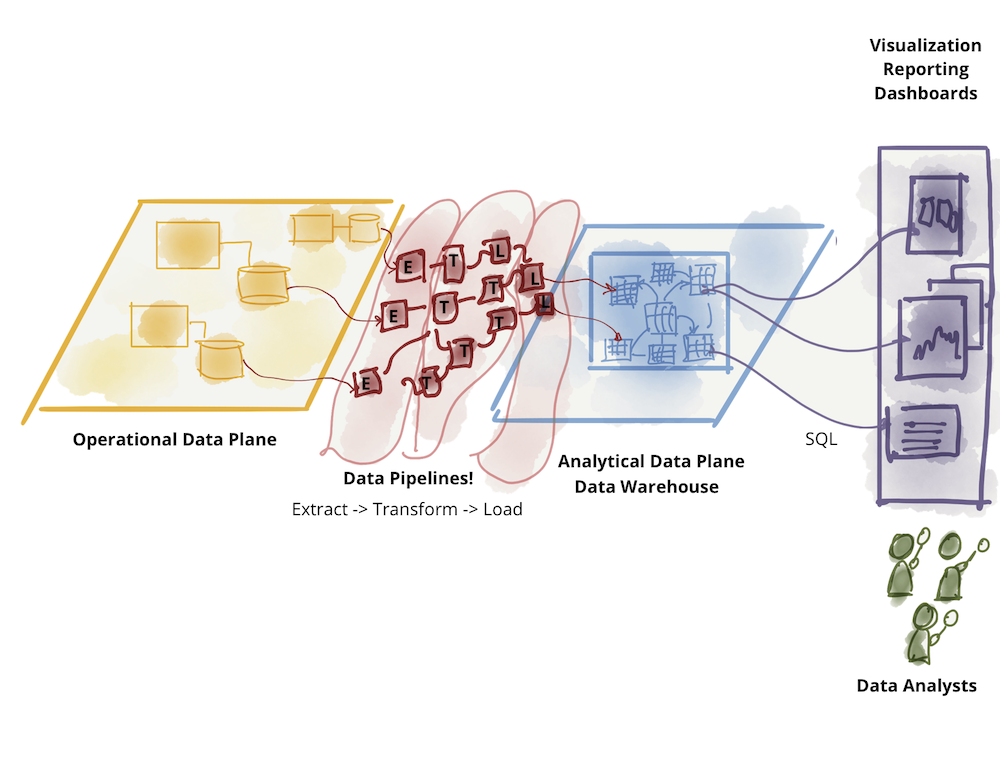
분석 데이터 영역은 데이터 레이크와 데이터 웨어하우스라는 아키텍쳐로 나누어집니다. 데이터 레이크는 데이터 사이언스 환경을 지원하며 데이터 웨어하우스는 분석 리포트 및 BI 도구를 지원합니다.
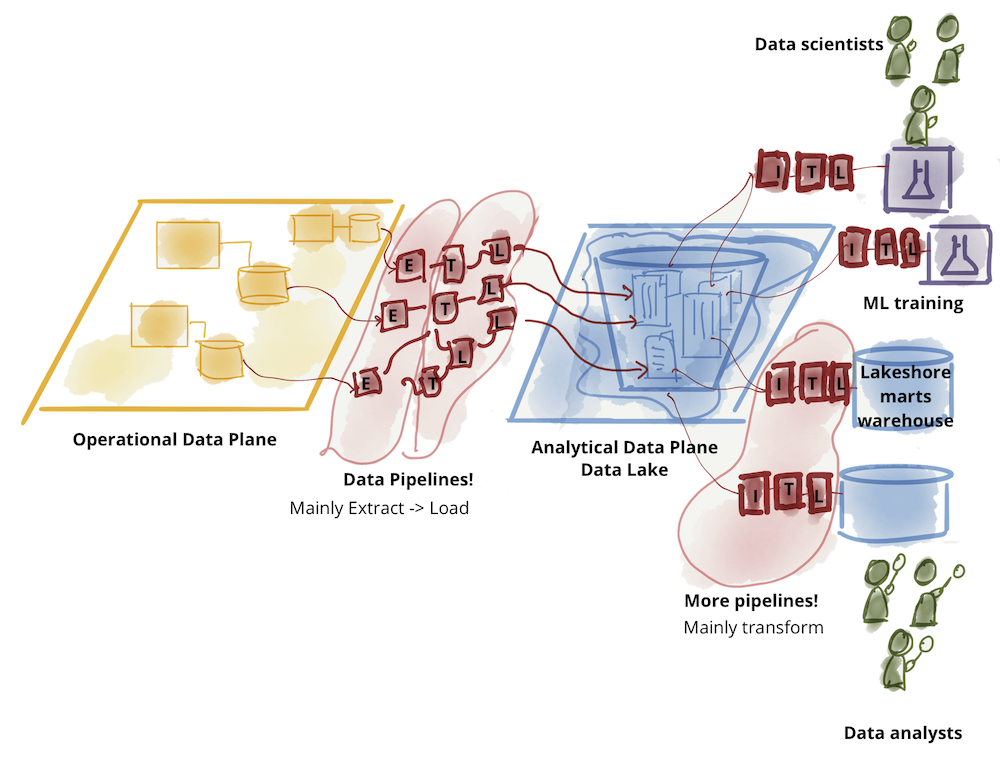
Data Mesh에서는 분석 데이터 영역에 중점을 두고 두 가지 데이터 영역을 연결하고 합니다. 두 가지 영역의 데이터를 관리하기 위해 기술 스택을 나누고 조직과 팀을 분리하면 안 됩니다. 마이크로서비스 아키텍쳐로 인해 운영 데이터도 과거에 비해 많이 성숙해졌으며 데이터는 각 마이크로서비스의 API를 통해 제어됩니다. 하지만 분석 데이터에 대한 관리 및 접근 제어는 여전히 어려운 과제로 남아있습니다. Data Mesh는 이 부분을 중점적으로 해결하고 합니다.
Data Mesh의 목표는 분석 데이터와 히스토리로부터 가치를 얻기 위한 기반을 만드는 것 입니다. 데이터 환경의 지속적인 변화에도 대응하고 데이터의 품질과 무결성을 제공하면서 데이터 사용에 대한 다양한 요구사항을 지원할 수 있어야 합니다. 이 글에서는 이를 달성하기 위한 네 가지 원칙을 제안합니다.
Domain Ownership
Data Mesh는 지속적인 변화와 확장성을 지원하기 위해 데이터를 가장 잘 이해하는 사람들에게 책임을 분산하고 탈중앙화하는데 기반을 두고 있습니다. 여기서 분석 데이터, 메타 데이터에 대한 소유권을 어떻게 나누어야 하는지에 대한 의문이 생기게 됩니다.
요즘 조직 구조는 비즈니스 도메인을 기준으로 나누어집니다. 이러한 구조를 통해 도메인 경계에 따라 지속적인 발전을 할 수 있게 만듭니다. 따라서 비즈니스 도메인의 경계(Bounded Context)를 기준으로 나누는 것이 적절하다고 볼 수 있습니다.
이러한 기준을 가지고 분리하려면 분석 데이터를 도메인 별로 나누는 아키텍쳐를 모델링해야 합니다. 이 아키텍처에서 도메인의 인터페이스에는 운영 데이터 뿐만 아니라 도메인이 제공하는 분석 데이터도 포함됩니다.
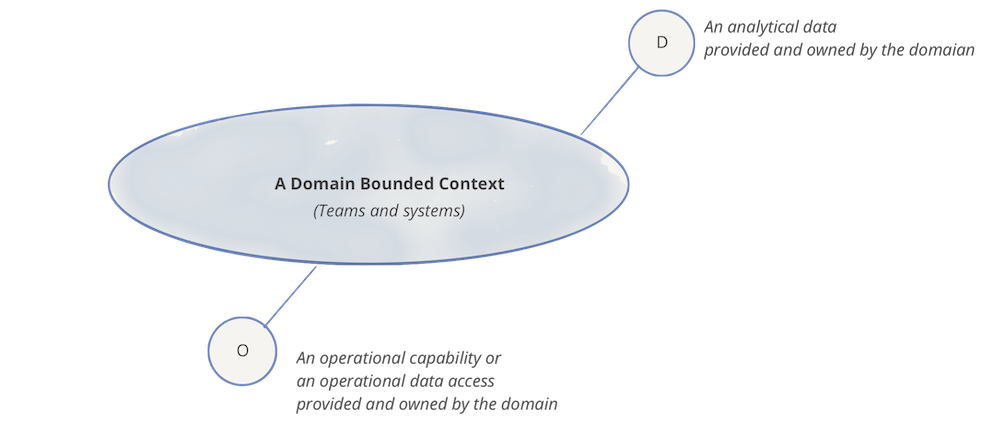
각 도메인은 하나 이상의 운영 API와 하나 이상의 분석 데이터를 제공합니다. 또한 각 도메인은 다른 도메인의 운영 및 분석 데이터와 의존 관계를 가질 수도 있습니다.
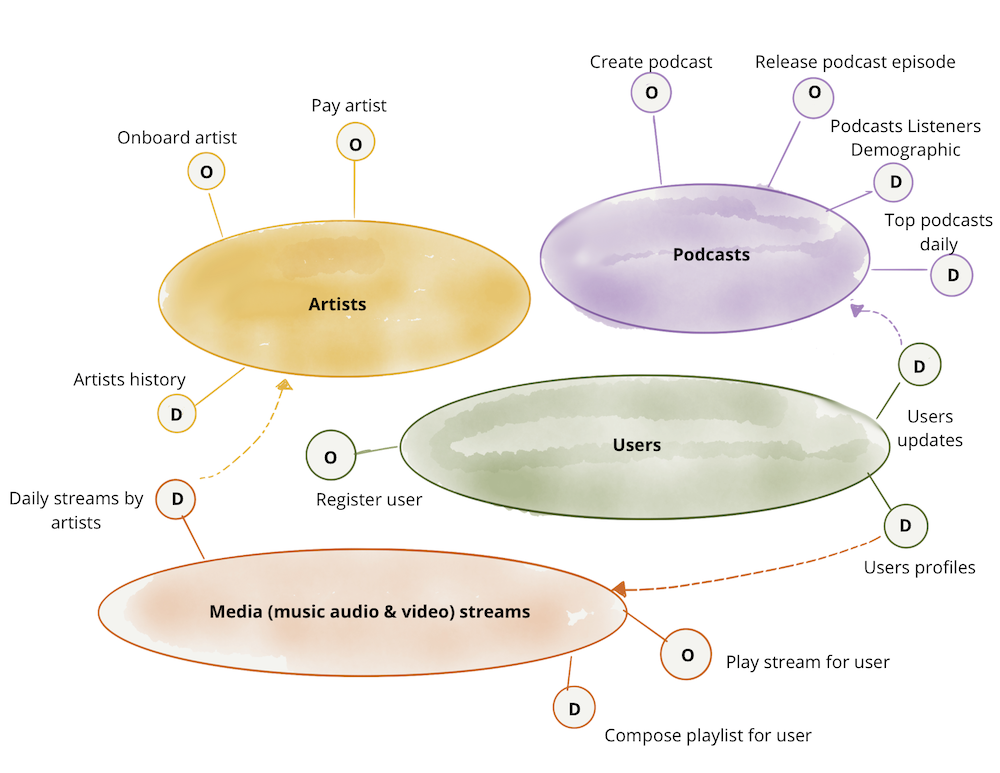
위의 예시와 같이 Podcasts 도메인은 Users 도메인의 데이터를 통해 Podcast 청취자들의 정보를 데이터화 할 수 있습니다.
Data as a product
기존 데이터 분석 아키텍쳐에서 어떤 데이터가 있는지 탐색하고 이해하고 데이터 품질을 유지하는 것이 큰 과제로 남아있었습니다. 이를 해결하지 않으면 Data Mesh 아키텍쳐에서 더 큰 문제로 다가올 수 있습니다. 탈중앙화 원칙에 따라 데이터를 제공하는 곳과 팀의 수가 늘어나기 때문입니다.
Data as a product 원칙은 데이터 사일로와 데이터 품질 문제를 해결하기 위한 방법입니다. 도메인에서 제공하는 분석 데이터는 product로 취급되어야 하며 데이터의 소비자는 고객으로 받아들여야 합니다.
조직에서는 도메인 데이터에 대한 PO(Product Owner)를 지정해야 하며 PO는 데이터가 프로덕트로써 전달되기 위한 여러 역할을 담당합니다. PO는 데이터 사용자가 누구인지, 어떻게 사용하는지 정의하고 데이터에 대해 깊이 이해하고 있어야 합니다. 데이터 품질, 데이터 사용 만족도를 측정하고 데이터에는 이를 지원하기 위한 표준 인터페이스가 개발되어야 합니다. 데이터 사용자와 PO는 꾸준히 커뮤니케이션을 통해 data product를 발전시킬 수 있습니다.
각 도메인에는 도메인의 data product를 구축하고 운영 및 제공하는 데이터 개발자 역할도 있어야 합니다. 각 도메인 팀은 하나 이상의 data product를 제공할 수 있습니다.
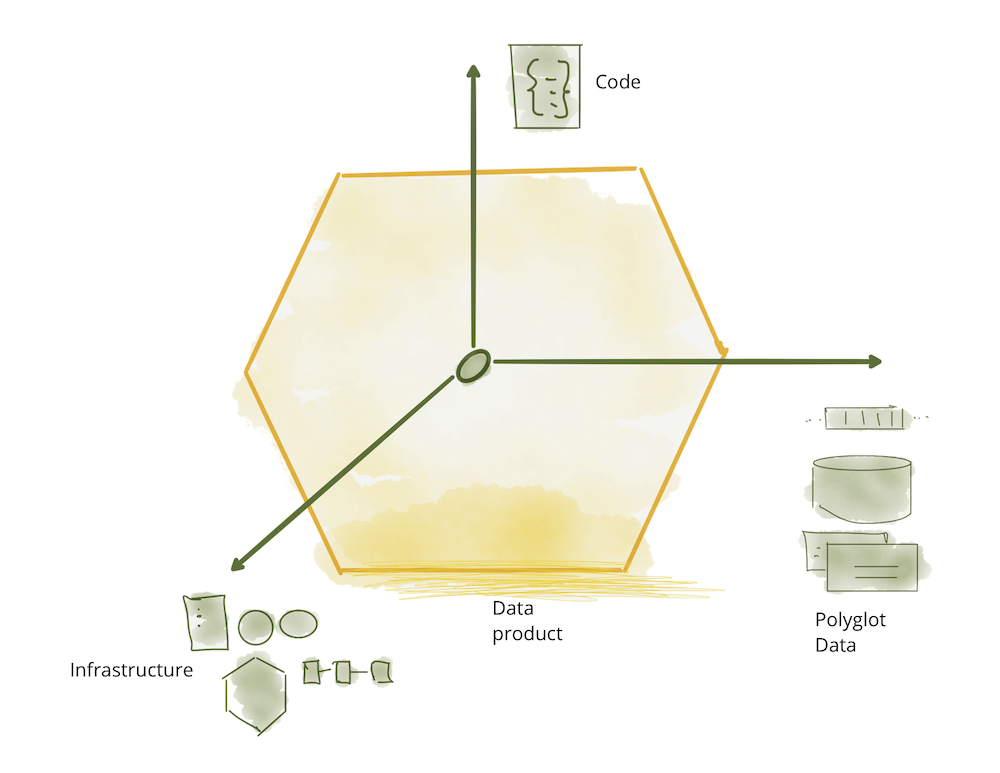
data product는 위와 같이 세 가지 구성 요소로 이루어져 있습니다.
1. Code
- 업스트림 데이터에 대한 ETL 프로세스를 제공하는 데이터 파이프라인 코드
- 데이터 스키마, 데이터 품질에 대한 지표, 메타데이터 적용을 위한 API
- 접근 제어 정책, 데이터 정책을 적용하기 위한 코드 (비식별화 등)
2. Data and Metadata
- 이벤트, 배치, 관계형 테이블, 그래프 등 다양하게 소비되는 데이터
- 각 데이터에 대한 메타데이터 정의
- 생성 로직과 접근 제어 정책
3. Infrastructure
- data product 코드를 구축, 배포 및 실행할 수 있는 인프라
- 데이터 및 메타데이터에 대한 저장 및 접근을 가능하게 하는 플랫폼
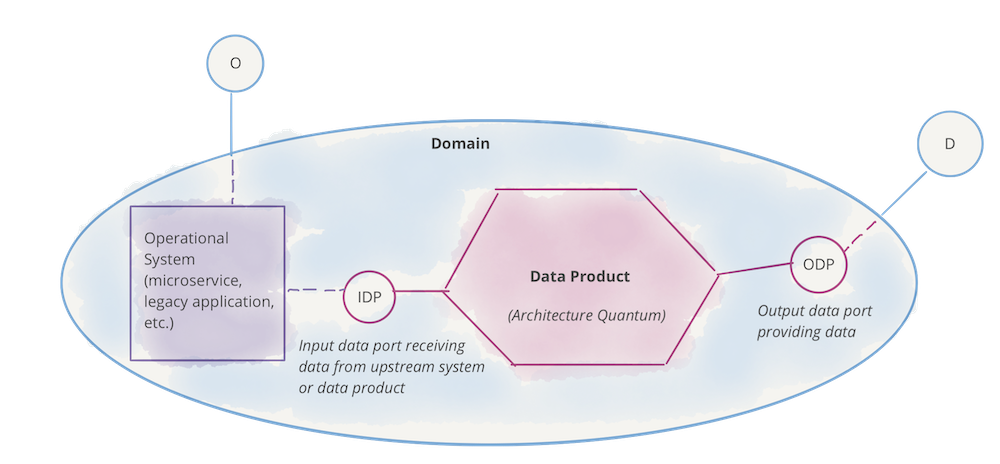
이를 다이어그램으로 표현하면 위와 같습니다.
Self-serve data platform
위와 같이 data product를 구축, 배포, 실행 및 모니터링하려면 이를 위해 많은 인프라가 필요합니다. 이를 구성하는데 필요한 기술은 전문적인 영역이라 각 도메인에서 운영하기 어렵습니다. 각 팀이 data product를 자율적으로 개발하고 운영하기 위해 제품의 수명 주기를 프로비저닝하고 관리할 수 있는 추상화된 인프라가 필요합니다. Self-serve data platform 원칙은 도메인 자율성을 가능하도록 지원하는 플랫폼을 말합니다.
셀프 서비스 데이터 플랫폼은 데이터 개발자의 워크플로우를 지원할 수 있어야 합니다. 데이터 제품을 생성하기 위해 필요한 비용과 진입장벽을 낮추고 스키마, 파이프라인 개발, 데이터 리니지, 컴퓨팅 클러스터 등을 지원해야 합니다.
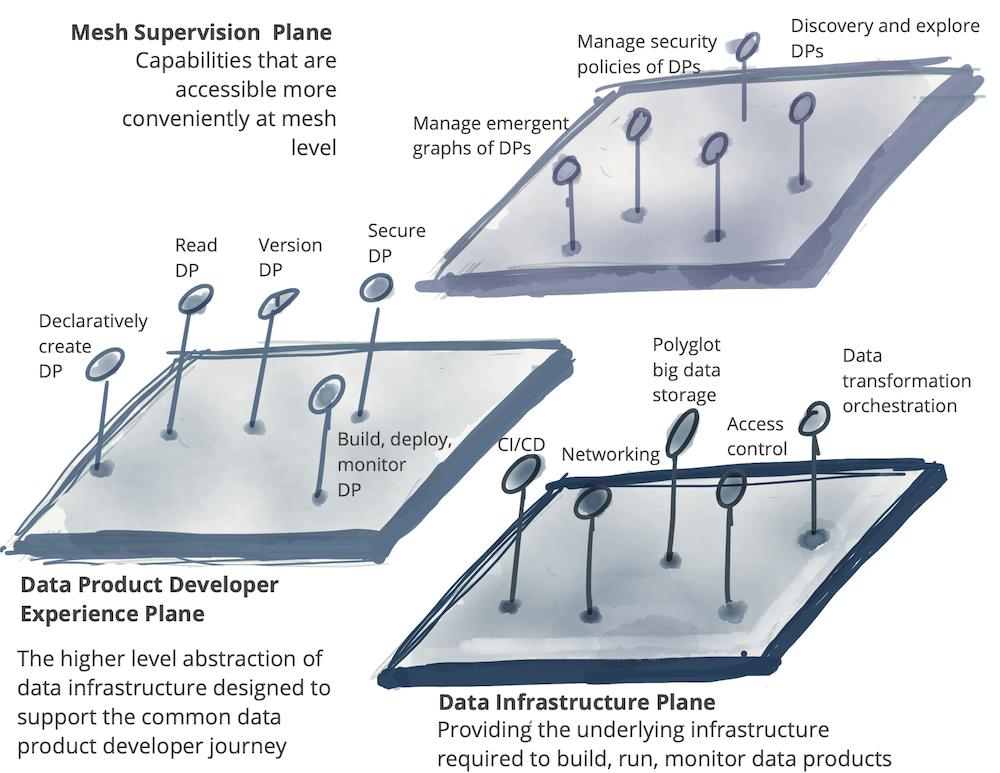
셀프 서비스 플랫폼에는 위와 같이 여러 기능을 제공하는 영역이 존재합니다. 위 그림에서는 아래와 같이 세 가지 영역으로 나누고 있습니다.
1. Data infrastructure provisioning plane
- 경험이 많은 데이터 개발자만 직접 사용
- data product를 실행하는데 필요한 기본 인프라 프로비저닝을 지원
- 분산 스토리지, 스토리지 계정과 접근 제어 시스템
- 데이터에 대한 분산 쿼리 엔진 프로비저닝
2. Data product developer experience plane
- 일반적인 데이터 개발자가 사용하는 기본 인터페이스
- 워크플로우 정의를 위해 필요한 복잡성을 추상화해서 제공
- data product에 대한 빌드, 배포, 모니터링 지원
- 미리 정의된 표준 규칙을 통해 자동으로 구현
3. Data mesh supervision plane
- Data Mesh 수준에서 한눈에 볼 수 있는 인터페이스
- data product를 검색할 수 있는 기능
- 여러 data product에 걸쳐 필요한 기능
Federated computational governance
지금까지 정의한 내용과 같이 Data Mesh 모델은 분산 아키텍쳐 형태를 가지고 있습니다. 독립적인 data product를 가지며 각 팀이 구축하고 배포합니다. 그러나 ML 영역과 같은 곳에서 가치를 얻으려면 각 data product가 상호적으로 운용되어야 합니다. 이러한 상호 운용을 위해 플랫폼에 의한 의사 결정을 자동화하기 위한 거버넌스 모델이 필요합니다. 이를 Federated computational governance 원칙이라고 합니다. 데이터 PO와 데이터 플랫폼 PO가 함께 주도하는 의사 결정 모델은 도메인 의사 결정 권한을 가지며 여러 규칙을 만들고 준수합니다. 이러한 거버넌스를 통해 중앙 집중화와 분산화 사이의 균형을 유지할 수 있습니다.
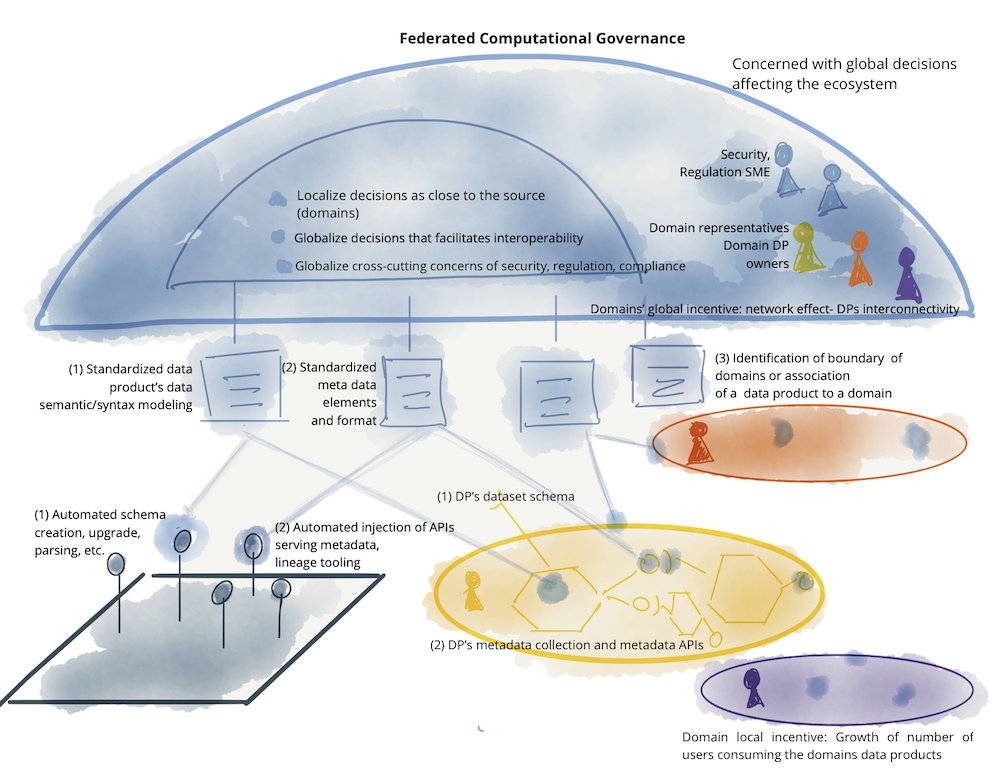
거버넌스 모델을 구현하기 위해 참여해야 하는 조직과 인센티브 모델을 정의해야 합니다. 데이터 플랫폼은 거버넌스로부터 정의된 정책을 자동으로 적용하기 위한 기능을 제공해야 합니다.
Principles Summary
Domain Ownership을 통해 데이터 생성과 사용자 수의 증가, 데이터 접근 정책의 다양성과 데이터의 확장에 대응할 수 있습니다.
Data as a product를 통해 데이터 사용자가 데이터를 쉽게 검색이 가능하고 품질이 보장된 데이터를 사용하며 데이터에 대한 이해도가 올라가고 안전하게 사용할 수 있습니다.
Self-serve data platform을 통해 각 도메인 팀이 자율적으로 제품을 만들고 사용할 수 있도록 하며 data product를 쉽게 구축, 실행 및 운영할 수 있습니다.
Federated computational governance를 통해 데이터 사용자가 상호 운용을 위한 표준을 따르는 생태계로 운영할 수 있습니다. 이러한 표준 정책은 플랫폼에 반영됩니다.