


Spark on Kubernetes: 성능 최적화 방법들
📅 September 11, 2021
•⏱️3 min read
Spark 3.1 버전부터 Spark on Kubernetes가 GA로 변경되었습니다. 이 글에서는 Spark on YARN 만큼의 성능을 내기 위해서 필요한 설정들에 대해 알아보겠습니다.
교차 AZ 전송 지연 개선
대부분 사용자들은 가용성을 우려하여 Multi-AZ 사용을 선호합니다. 하지만 driver, executor pod가 여러 AZ에 분산되어 있는 어플리케이션은 AZ 간 추가 데이터 전송 비용이 발생할 수 있습니다. 특히 spark shuffle은 disk IO, network IO에 대한 비용이 많이 드는 연산이므로 latency가 낮은 단일 AZ가 좋은 성능을 보일 수 있습니다.
--conf spark.kubernetes.node.selector.zone='<availability zone>'Spark on Kubernetes에서는 Pod Template 또는 node selector 설정을 통해 단일 AZ 노드 그룹에서 실행되도록 설정할 수 있습니다.
클러스터 노드 가용성 계산하기
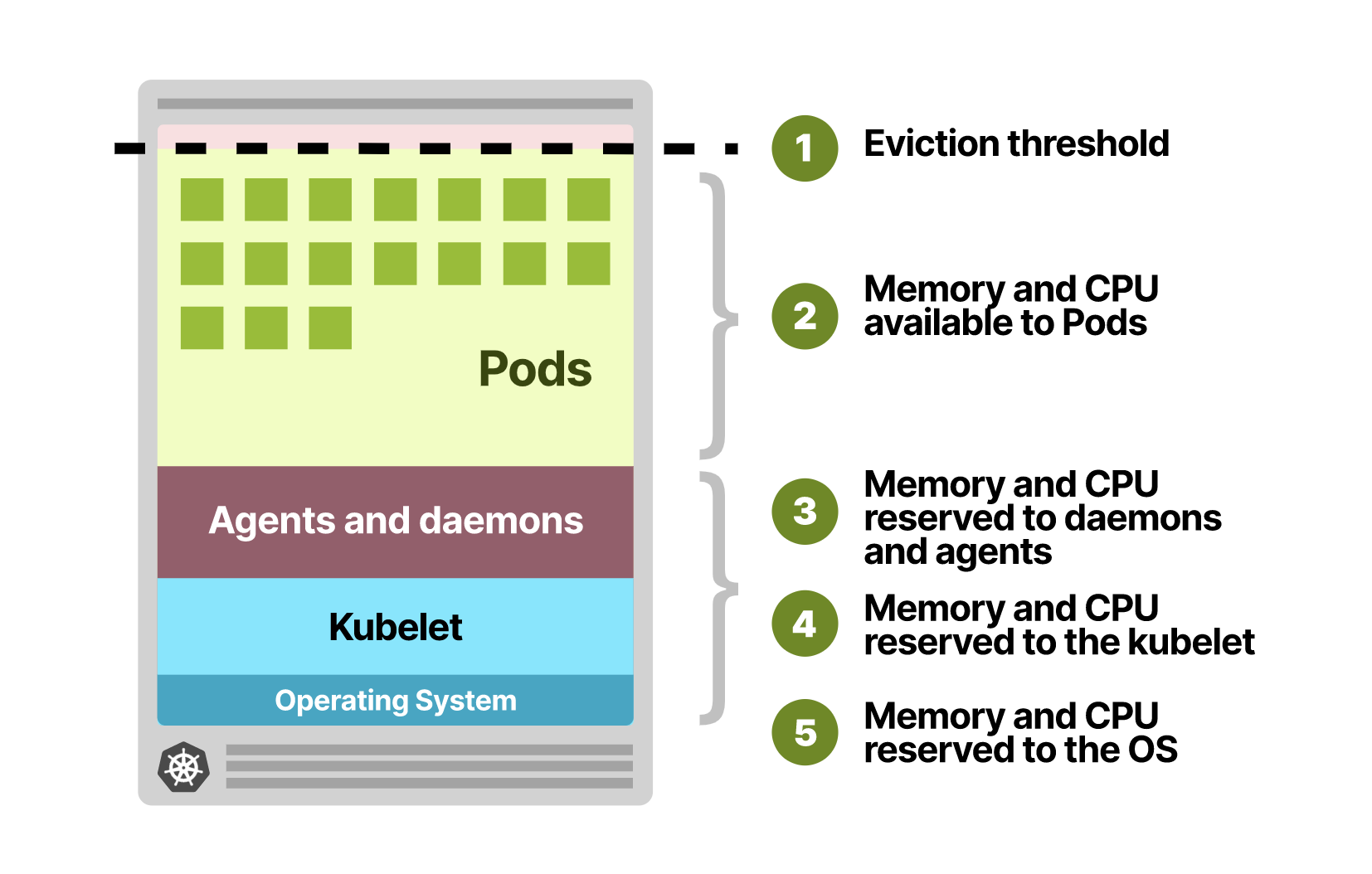
노드 전체의 리소스를 최대로 사용하기 위해 어느 정도의 리소스를 할당할 수 있는지 계산할 수 있어야 합니다. 모든 Kubernetes 노드는 클러스터 운영을 위해 OS 시스템과 Kubelet에서 일정량의 리소스를 점유하고 있습니다. 따라서 Pod에 할당 가능한 리소스를 계산할 때 이 부분은 제외하고 계산해야 합니다. 만약 노드마다 뜨는 daemonset이나 agent와 같은 어플리케이션을 띄웠다면 해당 리소스도 제외되어야 합니다.
클라우드 인스턴스 유형에 따라 빠르게 보고 싶을 때 Kubernetes Instance Calculator를 사용하면 쉽게 계산할 수 있습니다.
셔플 단계에서의 scratch space 개선
Spark Shuffle 발생 시 중간 파일들이 생기게 되는데, 보통 driver나 executor의 로컬 디렉토리를 사용합니다. 하지만 Kubernetes의 경우, 기본 값으로 Pod 내부의 볼륨(emptyDir)을 사용하고 있습니다.
emptyDir 유형의 볼륨은 Docker Storage Driver의 CoW(Copy-On-Write) 오버헤드로 인해 작은 파일 쓰기를 반복하는 경우 속도가 느려질 수 있습니다. 이를 개선하기 위해 Spark on Kubernetes GA 버전에서는 2가지의 설정이 추가되었습니다.
1. [SPARK-25262] Support tmpfs for local dirs in k8s
먼저 tmpfs를 local dir로 활용하는 방법입니다. tmpfs는 RAM 기반 파일 시스템으로 노드 재부팅 시 지워지고, 파일이 컨테이너 메모리 제한에 포함됩니다. 설정 방법은 아래와 같이 간단하지만 tmpfs 사이즈가 커질 수록 Pod OOM이 발생할 가능성이 크다보니 운영할 때는 번거로울 수 있습니다.
"spark.kubernetes.local.dirs.tmpfs": "true"2. [SPARK-27499] Support mapping spark.local.dir to hostPath volume
다음은 host에 마운트된 볼륨을 직접 사용하는 방법입니다. hostPath 볼륨을 spark.local.dir에 할당해서 셔플 과정에서의 디스크 성능을 향상시킬 수 있습니다. 다만 인스턴스에 SSD 또는 NVMe와 같은 볼륨을 추가로 마운트하는 경우에 더 좋은 효과를 볼 수 있습니다.
spec:
...
volumes:
- name: "spark-local-dir-1"
hostPath:
path: "/tmp/spark-local-dir"
executor:
instances: 10
cores: 2
....
volumeMounts:
- name: "spark-local-dir-1"Executor Pod Batch 관련 설정
보통 무거운 작업은 executor 여러 개가 떠서 처리하는 경우가 많습니다. Spark on Kubernetes에는 executor pod을 생성할 때 batch size와 delay가 존재합니다.
예를 들어 executor 10개를 띄울 때 기본 설정 값이 batch size = 5, delay = 1로 되어 있다면, executor pod 5개가 동시에 뜨고 1초 지연 이후에 5개가 추가로 생성됩니다.
이 설정 값은 Kubernetes Scheduler와 driver pod의 부하를 고려해서 설정해주어야 합니다.
"spark.kubernetes.allocation.batch.size": "5"
"spark.kubernetes.allocation.batch.delay": "1s"반면 아직 3.1 버전 기준으로 지원하지 않는 설정들은 아래와 같습니다.
- External Shuffle Service는 지원하지 않음
- Job Queue 없음 (Future Work)