


Pandas 2.0의 Copy-on-Write에 대하여
📅 December 24, 2023
•⏱️7 min read
Pandas 2.0 버전부터 Copy-on-Write (CoW)가 추가되었으며 3.0 버전부터 기본 값이 활성화로 변경됩니다. 이번 글에서는 Pandas Copy-on-Write가 Pandas가 가진 문제를 어떻게 해결하는지에 대해 알아보겠습니다.
Pandas DataFrame
Pandas CoW에 대해 알아보기 이전에 먼저 DataFrame의 내부 구조에 대한 이해가 필요합니다.
DataFrame은 Pandas의 행, 열 기반 2차원 데이터 구조입니다.
초기에 Pandas는 아주 느린 컬럼 기반 연산을 빠르게 처리하기 위해 BlockManager를 추가했습니다.
BlockManager
BlockManager는 numpy array로 저장된 데이터를 참조하는 블록을 관리하는 역할을 합니다.
아래 코드를 통해 자세히 알아보겠습니다.
df = pd.DataFrame(data)
print(df)
c1 c2 c3
0 1 a 10
1 2 b 20
2 3 c 30
print(df._data)
BlockManager
Items: Index(['c1', 'c2', 'c3'], dtype='object')
Axis 1: RangeIndex(start=0, stop=3, step=1)
NumpyBlock: slice(0, 4, 2), 2 x 3, dtype: int64
NumpyBlock: slice(1, 2, 1), 1 x 3, dtype: objectDataFrame을 생성하고 internal API를 통해 BlockManager 구조에 접근할 수 있습니다.
위 예시에서는 2개의 블록이 존재하며 그 중 int 타입을 가지는 c1, c3는 하나의 블록으로 통합되어 있습니다. 이처럼 BlockManager는 메모리 최적화와 효율적인 데이터 접근을 위해 동일한 타입을 하나의 블록으로 통합하여 관리합니다. 이번에는 동일한 타입을 가지는 c4 컬럼을 추가하고 다시 확인해보겠습니다.
df['c4'] = [100,200,300]
print(df._data)
BlockManager
Items: Index(['c1', 'c2', 'c3', 'c4'], dtype='object')
Axis 1: RangeIndex(start=0, stop=3, step=1)
NumpyBlock: slice(0, 4, 2), 2 x 3, dtype: int64
NumpyBlock: slice(1, 2, 1), 1 x 3, dtype: object
NumpyBlock: slice(3, 4, 1), 1 x 3, dtype: int64이번에는 새로운 블록이 추가된 것을 확인할 수 있습니다.
BlockManager는 새로운 블록이 추가될때마다 동일한 타입의 블록을 통합하지 않습니다.
df._data.consolidate()
BlockManager
Items: Index(['c1', 'c2', 'c3', 'c4'], dtype='object')
Axis 1: RangeIndex(start=0, stop=3, step=1)
NumpyBlock: [0 2 3], 3 x 3, dtype: int64
NumpyBlock: slice(1, 2, 1), 1 x 3, dtype: objectDataFrame 연산이 실행되기 직전에 consolidate() 메서드를 통해 자동으로 통합합니다.
구체적으로는 블록 통합이 연산에 유리한 경우에만 블록 통합이 이루어집니다.
Pandas SettingWithCopyWarning
앞서 Pandas가 BlockManager를 통해 어떻게 블록을 관리하는지 알아보았습니다.
이번에는 CoW에서 해결하고자 하는 SettingWithCopyWarning 문제에 대해 알아보겠습니다.
import pandas as pd
df = pd.DataFrame(data)
print(df)
student_id grade
0 1 A
1 2 C
2 3 D위와 같은 DataFrame에서 첫 번째 행의 grade 값을 E로 변경해보겠습니다.
grades = df["grade"]
grades.iloc[0] = "E"
print(df)
student_id grade
0 1 E
1 2 C
2 3 D
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame코드만 보면 grade 변수에만 변경내용이 적용된 것처럼 보입니다.
하지만 실제로는 df 내용도 변경되어 있으며 SettingWithCopyWarning 경고 문구가 나타납니다.
ChainedIndexing을 사용한 다른 예시도 확인해보겠습니다.
df[df["student_id"] > 2]["grades"] = "F"
print(df)
student_id grade
0 1 E
1 2 C
2 3 D이번에도 SettingWithCopyWarning 경고 문구가 나타나며 df에는 어떠한 변화도 없는 것을 확인할 수 있습니다.
이러한 문제가 발생하는 원인은 Pandas, Numpy가 내부적으로 view 또는 copy를 반환하는 방식에서 찾아볼 수 있습니다.
Views and Copies
import numpy as np
origin = np.array([1, 6, 4, 8, 9, 2])
view = origin.view()
copy = origin.copy()
arr[1] = 3
print(origin)
array([1, 3, 4, 8, 9, 2])
print(view)
array([1, 3, 4, 8, 9, 2])
print(copy)
array([1, 6, 4, 8, 9, 2])위 코드 결과를 보면 origin, view는 변경된 값으로 반영되어 있지만 copy는 반영안되어 있는 것을 확인할 수 있습니다. view는 자체적으로 데이터가 없는 numpy 배열 입니다. 반면에 copy는 원본 배열의 요소를 새 배열에 복사하여 전체 복사본의 데이터를 가지고 있습니다.
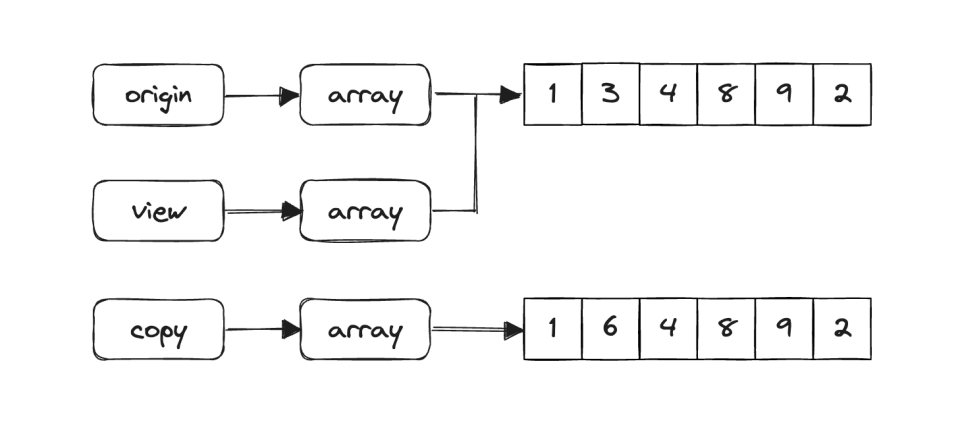
이처럼 view, copy에 따라 원본 객체인지 아닌지 달라지며 이는 일관된 동작을 보장하지 못하게 됩니다.
결국 SettingWithCopyWarning은 코드에서 사용자가 의도하지 않은 동작이 발생할 가능성이 있음을 경고하는 warning 입니다. 이 문제를 해결하기 위해 Pandas 2.0에 Copy-on-Write가 추가되었습니다.
Pandas Copy-on-Write
Pandas Copy-on-Write는 다른 DataFrame으로부터 생성된 모든 DataFrame이 항상 복사본으로 동작하도록 보장합니다. 다시 말해, 더 이상 단일 연산으로 두 가지 이상의 객체가 수정될 수 없습니다. (ex. 처음 예시에서 grade만 변경되고 df는 변경되지 않음)
이를 구현하기 위한 가장 쉬운 방법은 항상 데이터를 복사하는 방법입니다.
하지만 적용 시 성능이 크게 떨어지기 때문에 다른 방식을 적용해야 했습니다.
BlockValuesRefs
불필요한 복사를 방지하려면 복사를 트리거할 시기를 정확히 알아야 합니다.
결국 DataFrame 데이터가 다른 DataFrame과 공유되는 경우에만 복사를 트리거해야 합니다.
df = pd.DataFrame(data)
df2 = df[:]위 코드에서는 df와 df의 view 객체인 df2를 생성합니다.
현재 df와 df2는 동일한 numpy 배열을 참조하고 있습니다.
df.iloc[0, 0] = 100코드를 통해 둘 중 하나가 수정되는 경우, 복사가 트리거됩니다.
이 때 다른 Pandas 객체가 참조하고 있는지를 추적해야 합니다.
이를 위해 BlockValuesRefs가 추가되었습니다.
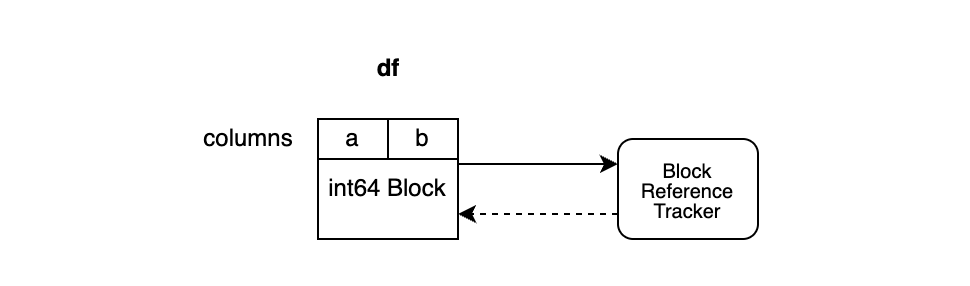
BlockValuesRefs는 numpy 배열을 감싸고 이 참조를 내부적으로 저장하는 블록을 가리키는 weakref를 생성합니다.
위의 예시와 같이 동일한 타입의 a, b 컬럼은 BlockManager를 통해 하나의 블록에 존재합니다.
그리고 블록에 대해 weakref를 가지는 Block Reference Tracker가 추가됩니다.
이제 다음 예시에서 새로운 블록을 추가해보겠습니다.
df2 = df.reset_index(drop=True)
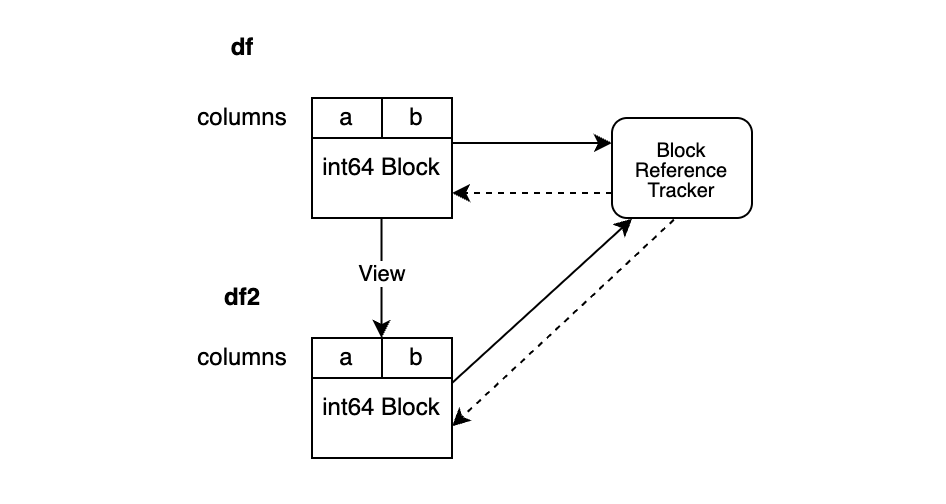
BlockValuesRefs는 이제 df를 위한 블록과 df2를 위해 새로 생성된 블록을 가리킵니다.
이를 통해 동일한 메모리를 가리키는 모든 DataFrame을 항상 인식할 수 있습니다.
동일한 numpy 배열을 가리키는 블록이 몇 개 남아 있는지 참조 추적 객체를 통해 알아낼 수 있습니다.
이러한 과정을 통해 둘 중 하나가 내부에서 수정되면 내부적으로 복사본을 트리거할 수 있습니다.
df2.iloc[0, 0] = 100
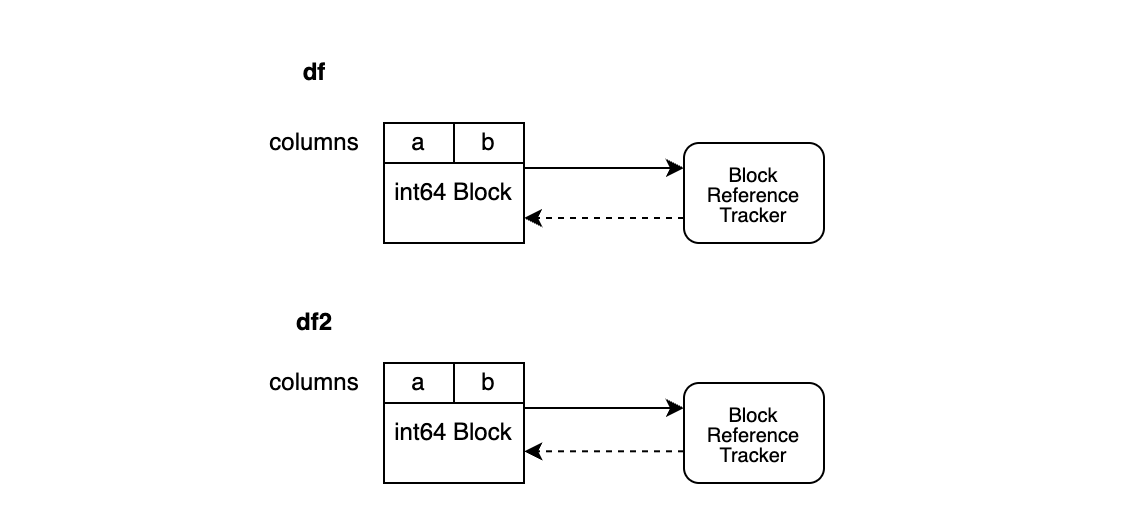
이제 df2의 블록은 전체 복사를 통해 복사되어 자체 데이터와 BlockValuesRefs가 있는 새로운 블록을 생성합니다. df와 df2는 더 이상 메모리를 공유하지 않습니다.
이해를 위해 몇 가지 상황을 더 살펴보겠습니다.
df = None
df2.iloc[0, 0] = 100
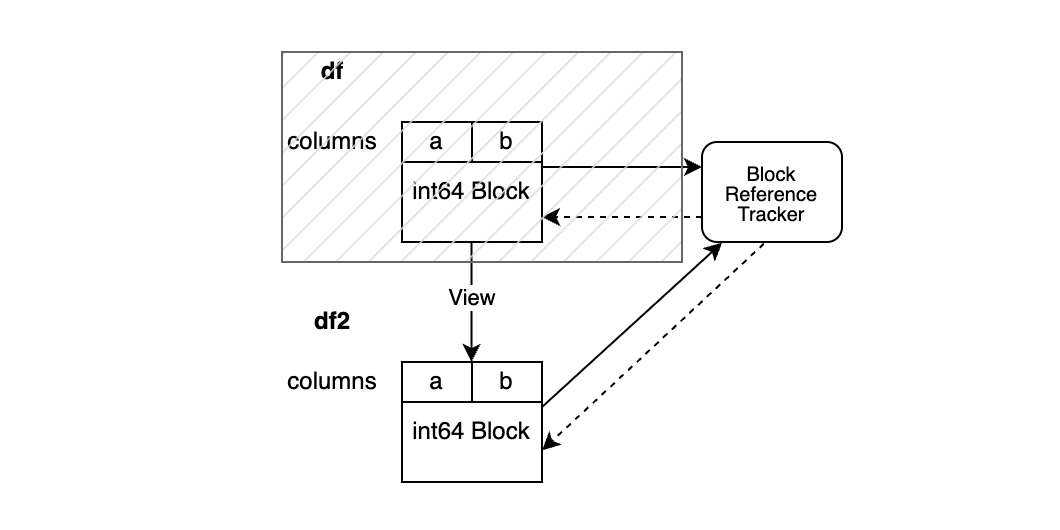
이 경우에는 df2를 수정하기 전 df가 None이 됩니다.
결국 df BlockValuesRefs의 weakref는 None으로 평가되며, 이를 통해 복사를 실행하지 않아도 df2를 수정할 수 있습니다.
마지막으로 BlockValuesRefs 객체는 복사를 트리거하지 않고 하나의 DataFrame만 가리키면 됩니다.
df2 = df.copy()
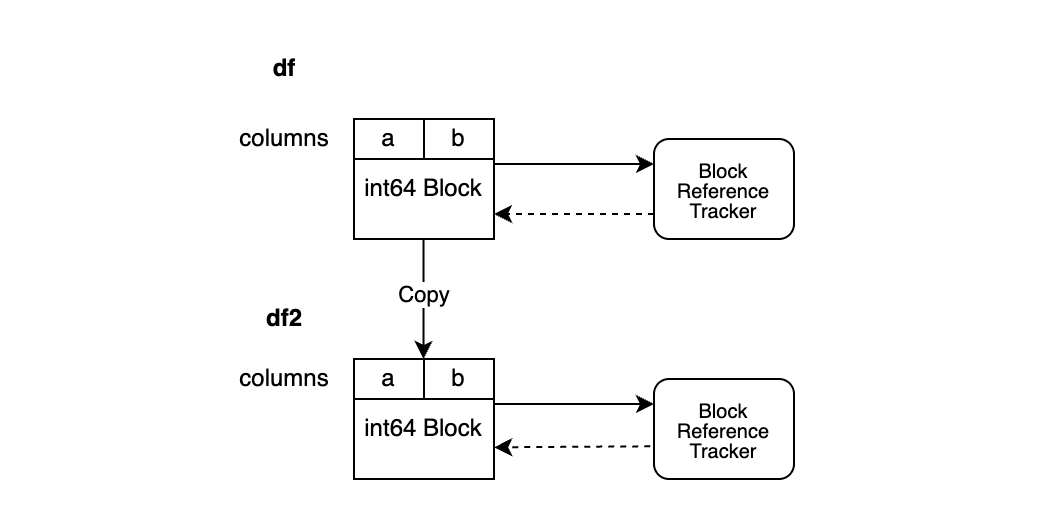
copy를 실행하는 경우는 간단합니다. DataFrame df2에 대한 새로운 BlockValuesRefs가 즉시 생성되며 데이터를 공유하지 않습니다.
Optimizing inplace copies
앞서 복사를 트리거하는 시점에 대해 알아보았습니다.
이번에는 복사본을 최대한 효율적으로 생성하는 방법에 대해 알아보겠습니다.
df.iloc[0, 0] = 100
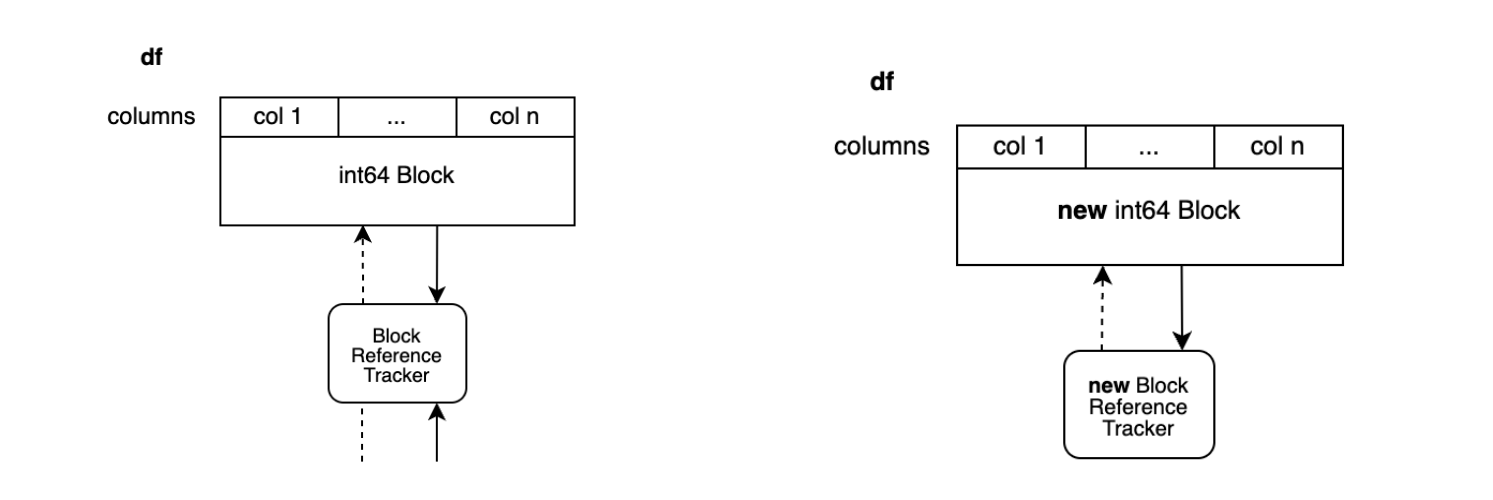
위 예시는 DataFrame에 n개의 정수 컬럼이 있으며 모두 하나의 블록으로 통합되어 있습니다.
다른 블록에서도 DataFrame을 참조하고 있기 때문에 하나의 값을 수정하기 위해 전체 블록을 복사해야 하는 상황입니다.
이 방식은 위 그림과 같이 복사할 필요가 없는 n-1개의 컬럼을 복사해야 합니다.
CoW에서는 이러한 상황을 최적화하기 위해 Block Splitting을 추가했습니다.
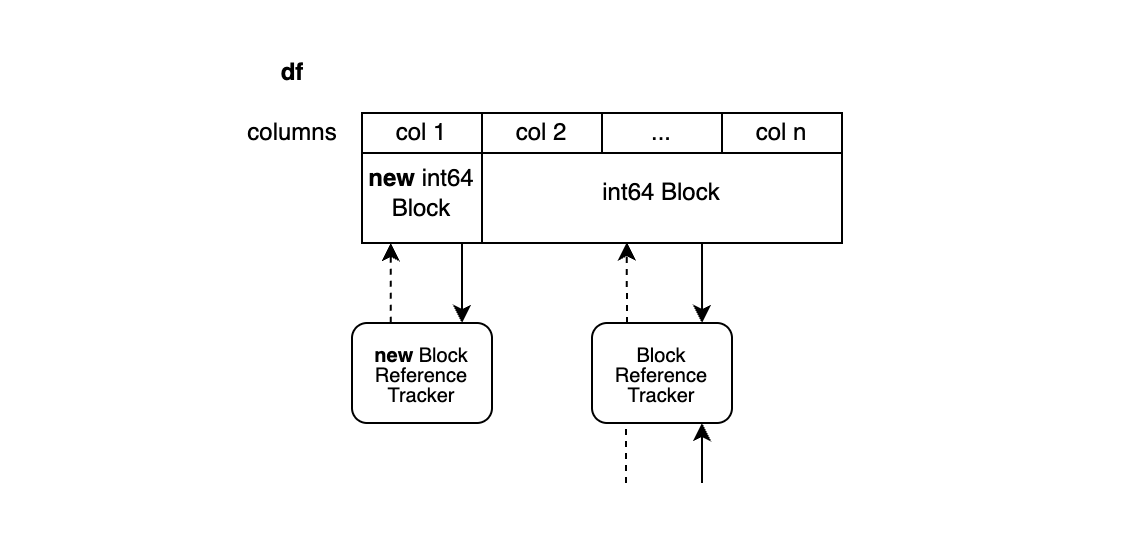
위 그림과 같이 Block Splitting을 통해 분할되어 내부적으로 첫 번째 컬럼만 복사됩니다.
다른 모든 컬럼은 이전 배열의 view로 간주되며 새로운 블록은 다른 열과 참조를 공유하지 않습니다.
이전 블록은 view일 뿐이므로 그대로 다른 객체와 참조를 공유합니다.
이 방식은 불필요한 복사를 방지할 수 있지만 이전 블록에 대한 정보에 새로운 블록까지 추가하므로 더 많은 메모리를 사용한다는 단점이 있습니다.
Pandas Copy-on-Write Mode
Pandas CoW를 통해 복사에 대한 지연, 최적화를 통해 빠른 성능을 얻을 수 있으며
DataFrame의 일관된 동작을 보장할 수 있습니다.
2.0 버전의 경우, 간단한 설정만 추가하면 Copy-on-Write 모드를 사용할 수 있습니다.
pd.options.mode.copy_on_write = True간단한 체이닝 연산을 통해 수행 시간의 차이를 확인해보면 다음과 같습니다.
%%timeit
(
df.rename(columns={"col_1": "new_index"})
.assign(sum_val=df["col_1"] + df["col_2"])
.drop(columns=["col_10", "col_20"])
.astype({"col_5": "int32"})
.reset_index()
.set_index("new_index")
)
# without CoW
2.45 s ± 293 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# with CoW
13.7 ms ± 286 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)위 예시에서는 대략 200배 정도 개선되었지만 연산에 따라 결과는 다를 수 있습니다.
특히 drop(axis=1), rename()과 같은 연산에서 큰 성능 향상을 확인하실 수 있습니다.