


Spark on Kubernetes: 커스텀 스케줄러 (2)
📅 December 10, 2023
•⏱️5 min read
Spark 3.4 버전부터 Customized K8S Scheduler 기능이 GA 되었습니다 👏🏻
오늘은 지난 글에 이어 가장 많이 사용하는 Volcano, Yunikorn 스케줄러에 대해 알아보겠습니다.
3.4 버전 기준으로 Spark에서는 Volcano, Yunikorn 두 가지 커스텀 스케줄러를 공식적으로 지원합니다. 두 가지 오픈소스 모두 네이티브 환경에서 배치 처리를 지원하기 위한 프로젝트이며 최신 버전 기준으로 모두 유사한 기능을 지원하고 있습니다. 먼저 Volcano 부터 살펴보겠습니다.
Volcano
초기의 Volcano는 kube-batch 프로젝트 기반으로 구성되었으나 1.8 버전부터 쿠버네티스 스케줄러 플러그인 방식을 지원하게 되었습니다. 스케줄러 플러그인 기반으로 구성한 커스텀 스케줄러는 기본 스케줄러와 호환 가능하며 버전 업데이트 영향도 적게 받는 장점이 있습니다.
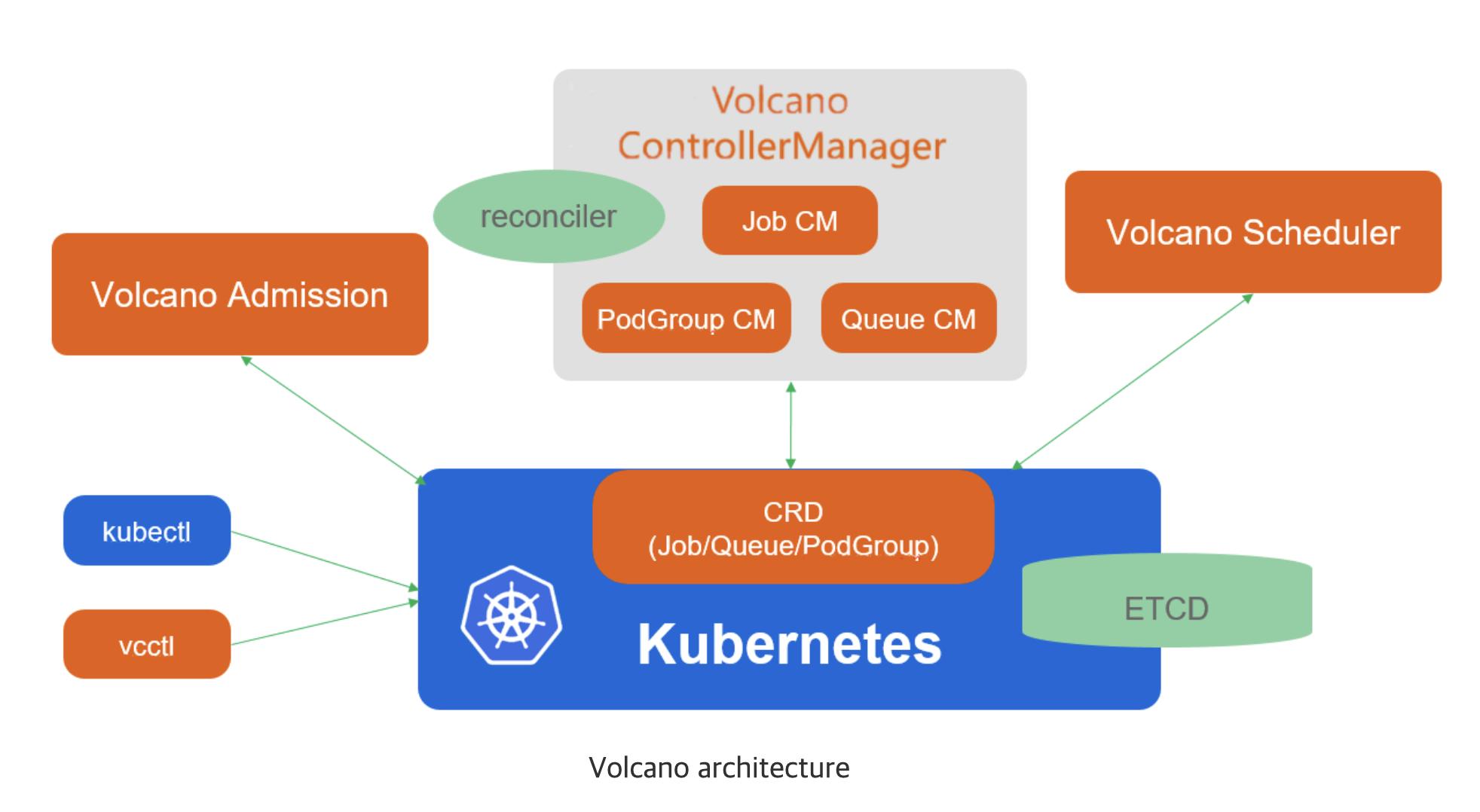
Volcano의 주요 컴포넌트는 다음과 같습니다.
- Scheduler: 여러 스케줄링 알고리즘을 거쳐 가장 적합한 노드에 작업을 할당합니다.
- ControllerManager: CRD (Queue, PodGroup, VCJob)의 lifecycle을 관리합니다.
- Admission: CRD API에 대한 유효성 검사를 담당합니다.
PodGroup을 통해 그룹 단위의 스케줄링이 가능하며, 하나의 Queue에는 여러 개의 PodGroup이 할당될 수 있습니다. 각 PodGroup은 status를 가지고 있어 Pending, Running 등의 상태가 관리됩니다.
스케줄링이 실행되는 워크플로우는 다음과 같습니다.
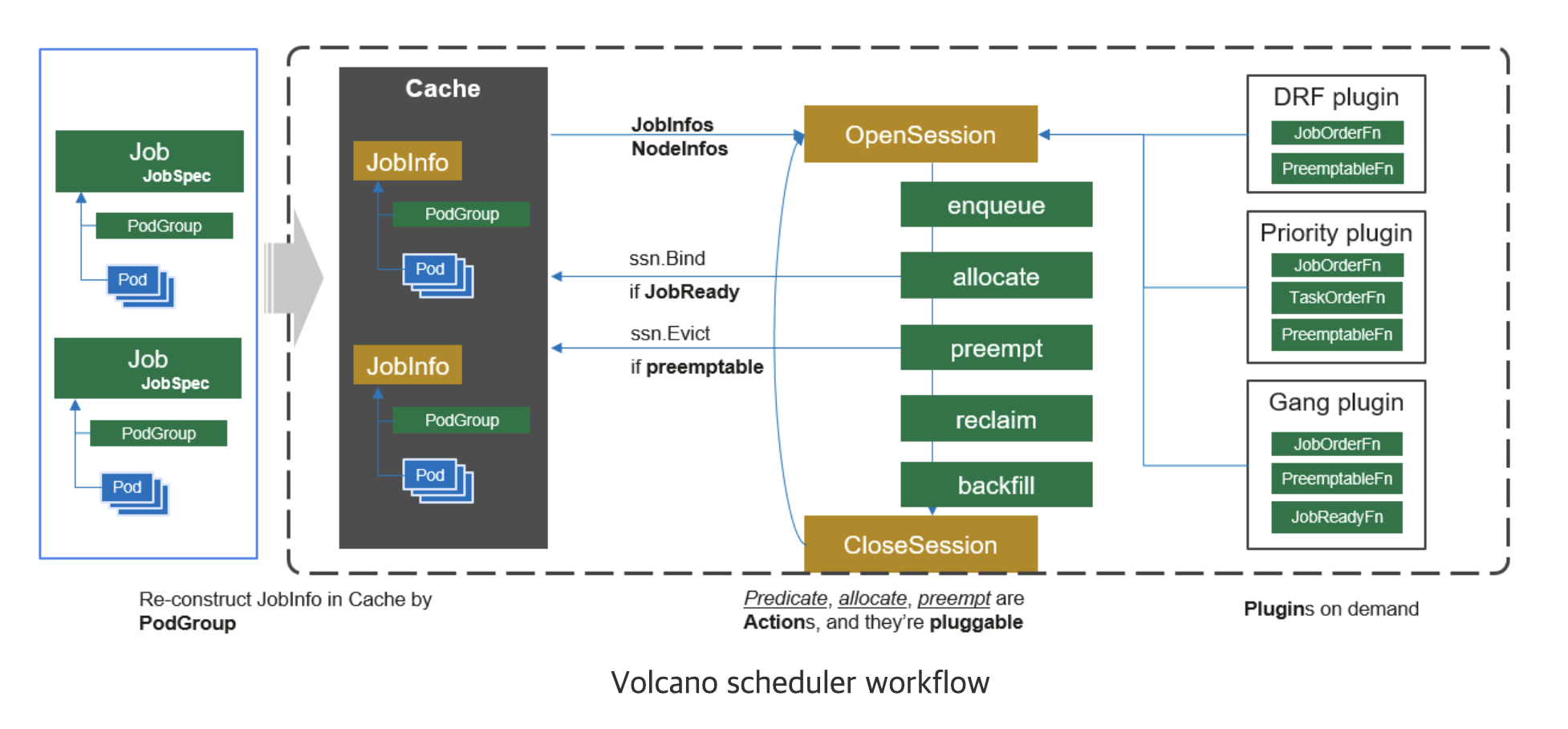
- client가 제출한 작업을 watch하고 캐싱합니다.
- session을 새로 생성하고 스케줄링 사이클을 시작합니다.
- 캐시에 예약되지 않은 작업은 session의 대기열로 보냅니다.
- 필요한 작업을 순회하면서 순서대로 스케줄링 단계를 실행하고 적합한 노드를 찾습니다.
- 작업을 노드에 바인딩합니다.
- 세션을 종료합니다.
Volcano 적용 과정
Volcano 적용을 위해 필요한 단계는 다음과 같습니다.
- Volcano 환경 및 리소스 배포
- Spark Volcano 이미지 빌드 및 배포
- Spark configuration 전달
# Specify volcano scheduler and PodGroup template
--conf spark.kubernetes.scheduler.name=volcano
--conf spark.kubernetes.scheduler.volcano.podGroupTemplateFile=/path/to/podgroup-template.yaml
# Specify driver/executor VolcanoFeatureStep
--conf spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep
--conf spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStepApache Yunikorn
Yunikorn은 Volcano보다 뒤늦게 시작된 Apache 프로젝트입니다. 컨테이너 오케스트레이션을 위한 경량의 범용 스케줄러를 지향하고 있으며 대부분의 스케줄링 알고리즘도 지원하고 있습니다. 또한 Volcano와 동일하게 스케줄러 플러그인 방식을 지원합니다. 추가로 Yunikorn은 조직 단위로 리소스 관리가 가능하도록 계층 구조의 큐를 지원합니다.
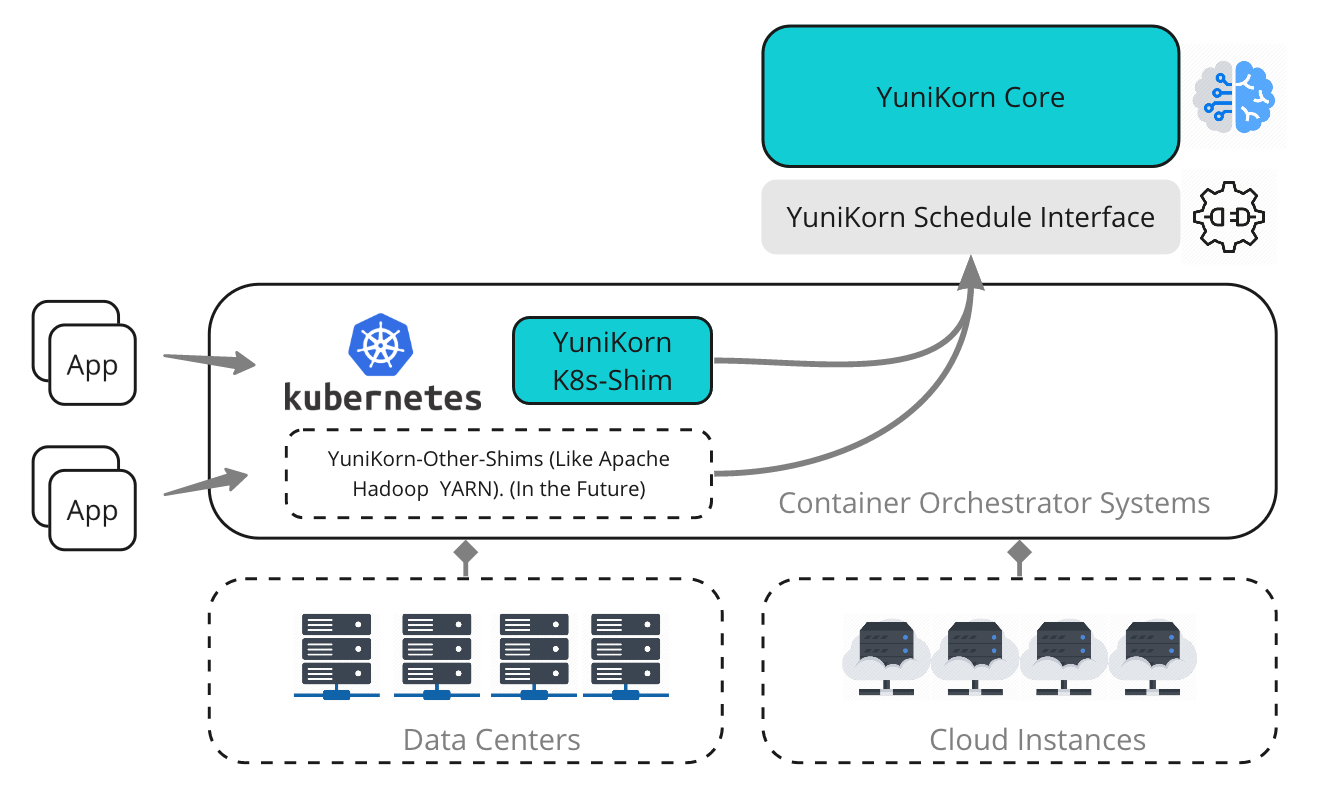
Yunikorn의 주요 컴포넌트는 다음과 같습니다.
- Scheduler Interface: 다른 리소스 플랫폼(K8S, YARN)과 통신을 위한 인터페이스
- Scheduler Core: 스케줄링 알고리즘 구현, 메트릭 수집, 컨테이너 할당 요청
- Kubernetes Shim: 쿠버네티스와 통신을 담당, Pod를 특정 노드에 바인딩하는 역할
- Admission Controller: mutation, validation hook을 담당
Yunikorn은 Volcano와 달리 추가로 배포되는 CRD가 없습니다.
큐와 알고리즘 등 관련 설정은 모두 Yunikorn 배포에 포함됩니다.
간단한 Yunikorn 설정 파일 예시는 다음과 같습니다.
partitions:
- name: default
nodesortpolicy:
type: binpacking
queues:
- name: root
submitacl: '*'
properties:
application.sort.policy: fifo
application.sort.priority: disabled
queues:
- name: prod
resources:
guaranteed:
memory: 300G
vcore: 30
max:
memory: 600G
vcore: 60
- name: stage
resources:
guaranteed:
memory: 100G
vcore: 10
max:
memory: 200G
vcore: 200위와 같이 prod, stage 등 여러 개의 큐를 계층형으로 생성할 수 있습니다.
스케줄링 정책은 크게 node sorting 단계와 application sorting 단계로 나누어집니다.
gang scheduling을 사용하는 경우, application sorting은 항상 fifo를 사용해야 합니다.
Yunikorn에서 Gang Scheduling이 실행되는 단계는 다음과 같습니다.
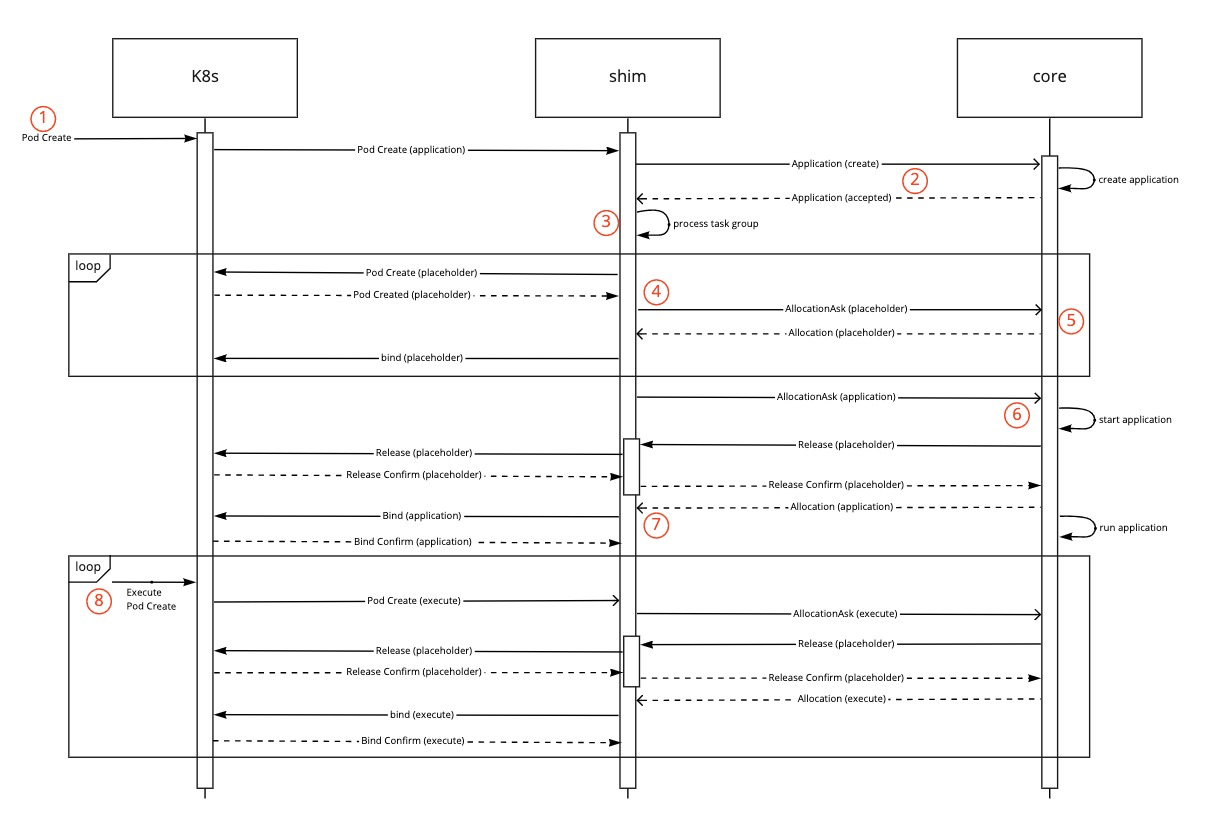
- TaskGroup이 정의된 application을 submit 합니다.
- Shim이 application을 생성하고 이를 Core(Kube scheduler)에 전달합니다.
- Shim은 TaskGroup의 각 member에 대한 placeholder pod를 생성합니다. spark의 경우, member는 driver, executor가 될 수 있습니다.
- pod가 정상적으로 생성되고 나면 AllocationAsks로 처리되어 Core에 전달됩니다.
- placeholder는 Core를 통해 적절한 노드에 바인딩됩니다.
- 이제 실제 pod가 AllocationAsk로 Core에 전달됩니다.
- 실제 pod와 모든 placeholder pod가 스케줄링 완료된 이후 Shim은 실제 pod를 바인딩합니다.
Yunikorn 적용 과정
Yunikorn 적용을 위해 필요한 단계는 다음과 같습니다.
Yunikorn의 경우 annotation 설정을 사용합니다.
- Yunikorn 환경 및 설정 배포
- Spark configuration 전달
--conf spark.kubernetes.scheduler.name=yunikorn
--conf spark.kubernetes.driver.label.queue=root.default
--conf spark.kubernetes.executor.label.queue=root.default
--conf spark.kubernetes.driver.annotation.yunikorn.apache.org/app-id={{APP_ID}}
--conf spark.kubernetes.executor.annotation.yunikorn.apache.org/app-id={{APP_ID}}Volcano vs Apache Yunikorn
앞서 살펴 본 내용을 통해 각 스케줄러의 장단점을 정리해보면 다음과 같습니다.
모두 Helm 차트를 지원하므로 쉽게 구성할 수 있습니다.
Volcano
장점: Kubeflow에 대한 지원
단점: spark 이미지 빌드, CRD 단위로 관리가 필요
Yunikorn
장점: 작업 상태를 확인할 수 있는 Web UI 지원
장점: 경량화되어 있으며 계층 구조의 큐를 지원
장점: 추가로 필요한 부분이 적어 운영이 편리
단점: 주요 설정은 모두 있으나 Volcano 대비 적은 옵션 지원
운영을 하면서 마주칠 수 있는 부분들
다음은 적용한 이후에 운영을 하다보면 마주칠 수 있는 이슈 또는 고민을 정리해보았습니다.
placeholder 리소스 설정
application submit 시 placeholder에 할당할 리소스 사이즈 결정이 필요합니다.
placeholder를 작게 설정하면 리소스 확보가 안되어 스케줄링에 영향이 있을 수 있고 지나치게 크게 설정하면 실제로 여유가 있음에도 리소스 부족 현상 발생할 수 있습니다. spark-on-k8s-operator를 사용한다면 스케줄러에 따라 placeholder 사이즈를 결정하는 로직이 포함되어 있으니 편하게 적용이 가능합니다.
큐 사이즈 조정
만약 큐의 리소스 제한보다 요청한 리소스가 크다면 application reject이 발생하여 실행이 불가능합니다. 또한 큐의 크기가 전체적으로 작은 경우, 신규 요청한 어플리케이션이 빈번하게 대기하는 상황도 발생할 수 있습니다. 스케줄러에서 Prometheus 메트릭을 제공하니 Grafana를 통해 모니터링 후 적절한 큐 사이즈로 설정하는 과정이 필요합니다.
Spark Dynamic Resource Allocation을 사용하는 경우
큐에서 이미 실행 중인 application은 리소스 확장도 가능합니다.
따라서 Spark의 Dynamic Resource Allocation을 많이 사용한다면 미리 설정해둔 제한을 크게 넘어갈 수도 있습니다. 이러한 경우, 큐를 사용하는 의미가 사라지게 됩니다.
Application Cleanup 관련
상황에 따라 application이 accepted 또는 waiting 상태에서 계속 머무르는 이슈가 발생할 수 있습니다. 이처럼 placeholder가 할당되지 못하는 경우, 스케줄러에서 timeout 설정을 통해 실패 처리되어야 다음 작업이 원활하게 진행될 수 있습니다. 만약 좀비 상태로 placeholder가 남는다면 core에서 확인 후 GC를 통해 정리됩니다.
Reference
두 가지 스케줄러 모두 범용적으로 많이 사용되고 있어 운영 중인 환경에 따라 선택하시면 좋을 것 같습니다.
각 스케줄러에 대한 자세한 내용은 아래의 공식문서에서 찾아보실 수 있습니다!