


머신러닝을 시작하기 위한 기초 지식 (2)
📅 February 08, 2017
•⏱️2 min read
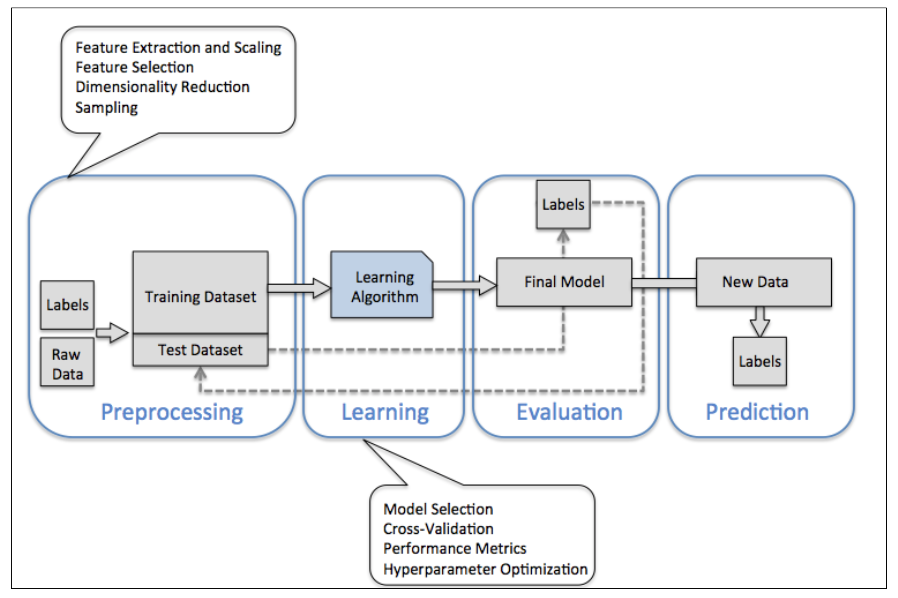
이번 포스팅에서는 데이터를 분석하기 위한 과정에 대해 하나하나 간단히 알아보겠습니다. 일반적으로 어떠한 데이터로부터 어떠한 가치를 창출하고자 할 때, 다음과 같이 [전처리 - 모델링 - 평가 - 예측] 프로세스를 따르게 됩니다.
Preprocessing
전처리 과정은 Preprocessing 또는 Data Cleaning / Wrangling / Munging 과 같이 다양한 용어로 불립니다. 이 과정에서 어떤 일을 하는지 한마디로 요약하자면 비정형 데이터를 정형화시키는 작업을 합니다. 대부분의 우리가 수집한 데이터는 쓰레기의 집합에 가깝습니다. 따라서, 원하는 형태에 맞게 수정 / 변환해주는 작업이 필요한 것입니다.
비정형 데이터를 가치있는 데이터로 변환하기 이전에, 먼저 어떻게 생겼는지 확인해보는 것이 좋습니다. 실제 Kaggle에 가보면 많은 사이언티스트들이 데이터를 시각화해놓은 스크립트를 많이 볼 수 있습니다. 이러한 과정을 통해 모델링 이전에 인사이트를 얻게 된다면, 이후에 많은 시간을 절약할 수 있게 됩니다.
대충 확인했다면 이제 데이터를 정형화시키는 작업을 진행합니다. 이 단계는 데이터에 따라 다르겠지만 약간 노가다 작업이 많이 들어갑니다. 텍스트 날짜 데이터를 datetime 객체로 변환하고 날짜별로 정리한다던지, Null 데이터를 적절한 값으로 채우거나 버리는 작업이 이에 해당합니다.
만일 텍스트 데이터를 분석해야 한다면, 상황에 따라 다음과 같은 과정이 필요할 것입니다. 이 부분에 대해서는 나중에 자세히 다루겠습니다.
- Stopword 제거
- 한글 형태소 분석
- 개체명 인식
- One-Hot Encoding
- Word Embedding
- 그 밖에 여러가지
데이터가 어느정도 깨끗해지고 나면 Training Dataset과 Test Dataset을 나누어 줘야 합니다. Training Dataset으로 학습하고 나면, 모델이 그 데이터에 최적화 되어 있기 때문에 학습에 사용하지 않은 데이터로 나누어주는 것이 좋습니다. Coursera 강의를 보면 일반적으로 Training Dataset을 70%, Test Dataset을 30%로 나누는게 적당하다고 말합니다.
Modeling
모델링 과정은 적절한 Learning Algorithm을 선택하여 Training Dataset을 넣고 학습하는 과정입니다. 먼저 Model Selection 같은 경우, 분석하고자 하는 과정이 Classification인지, Regression인지 등 여러 경우와 데이터에 따라 적절한 모델을 선택하면 됩니다. 이 과정에서 통계적 지식이 조금 요구됩니다.
이렇게 모델을 만들고 나서 바로 Test Dataset 과 비교하는 것이 아니라, Cross-Validation 과정을 거치게 됩니다. Cross-Validation은 학습에 사용된 Training Dataset 중 일부분을 나누어 검증하는 데 사용하는 것을 말합니다. 왜 중간에 검증 과정이 필요한가 하면, 우리가 가지고 있는 데이터는 전체 데이터 중 일부를 샘플링 한 데이터이기 때문에 신뢰도가 100%일 수 없습니다. 따라서, Cross-Validation은 통계적으로 신뢰도를 높이기 위한 과정입니다. 대표적인 방법으로 K-Fold와 Bootstrap이 있습니다.
그리고 모델의 성능을 높이기 위한 방법으로 Hyperparameter Optimization 이 있습니다. Parameter Tuning 이라고 부르기도 합니다. 간단히 말해서 모델에 들어가는 파라메터들을 최적의 값으로 튜닝하는 것입니다. 딥러닝의 경우 뉴럴넷을 통해 알아서 최적화 되지만, 머신러닝 알고리즘의 경우 결과 값을 확인하여 최적화하는 경우가 많습니다. 대표적으로 Grid Search, Random Search 등의 방법이 있습니다.
Evaluation & Prediction
마지막은 모델을 평가하고 결과를 예측하는 과정입니다. 모델을 평가한다는 것은 말 그대로 이 모델이 좋은지 별로인지, 너무 Training Dataset 에만 최적화 된 것은 아닌지 등을 평가하는 작업을 말합니다. 일반적으로 모델 평가에는 performance matrix 나 loss function 이 사용됩니다. Log Loss, F1 Score, RMSE 등의 값들이 이에 해당합니다.
Python Library
다행히 파이썬에는 일련의 과정에 필요한 패키지들이 다양하게 제공됩니다. 그 중에서 제가 자주 쓰는 라이브러리를 간단히 정리해보았습니다.
Data Analysis
- Numpy, Pandas
- Scikit-learn, Scipy
- Gensim, NLTK
- TensorFlow
Data Visualization
- Matplotlib, Seaborn
- Chart.js, HighChart.js, D3.js