


Spark on Kubernetes: 커스텀 스케줄러 (1)
📅 June 08, 2023
•⏱️3 min read
Spark 3.4 버전부터 Customized K8S Scheduler 기능이 GA 되었습니다 👏🏻
그래서 오늘은 커스텀 스케줄러가 왜 필요하고 어떻게 적용할 수 있는지 정리해보려고 합니다.
Spark Kubernetes Scheduling
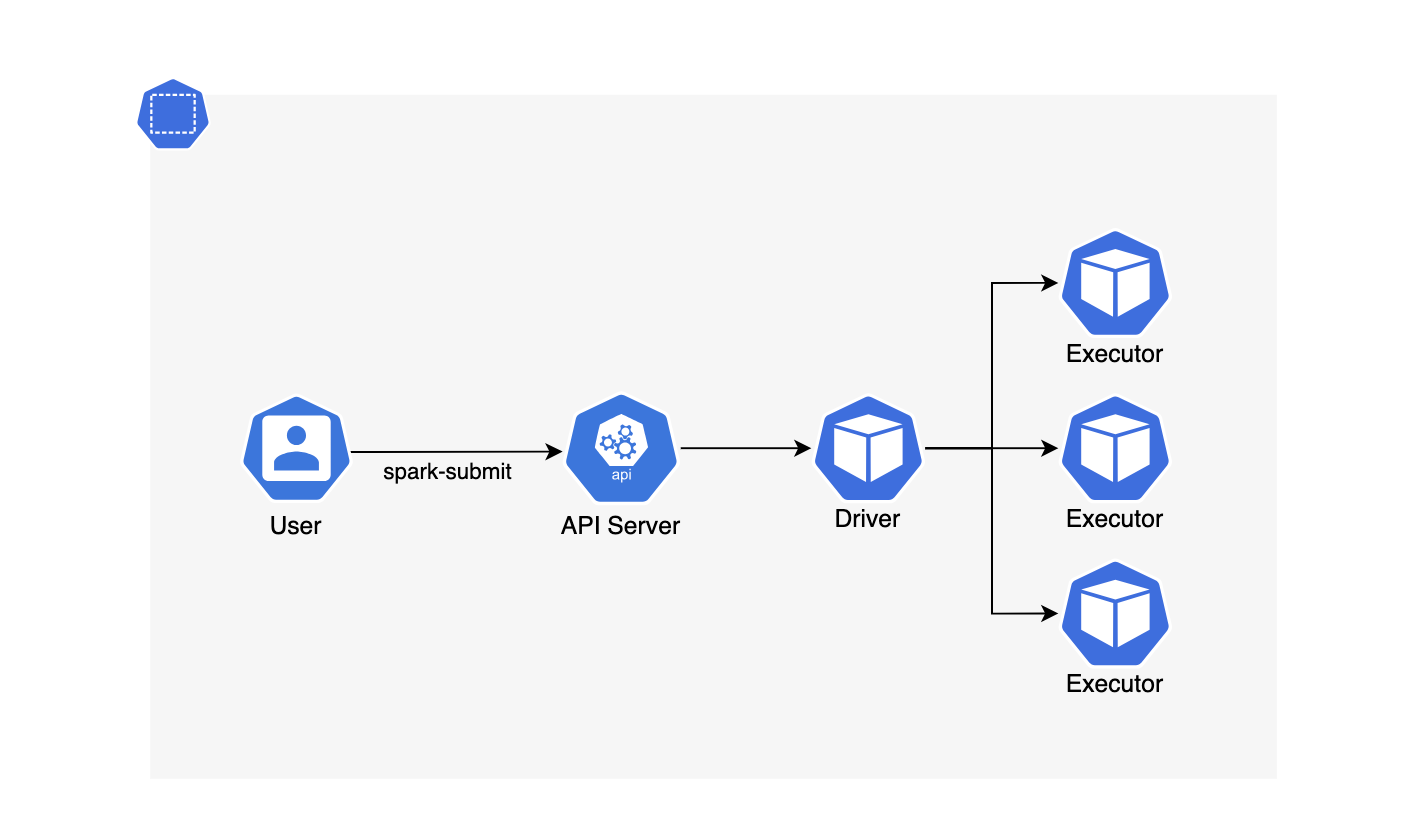
쿠버네티스 환경에서 spark-submit을 실행하면 pod가 실행되는 순서는 다음과 같습니다.
- spark-submit 명령어 실행
- Kube API를 통해 driver pod 생성
- driver pod → API Server에 executor 생성 요청
- Kube API를 통해 executor pod 생성
위와 같이 driver가 executor를 관리함에 따라 동적으로 리소스를 확장할 수 있지만 driver가 생성되기 전까지 전체 executor에 필요한 리소스를 알 수 없다는 단점이 있습니다. 이러한 이유로 클러스터 내에 리소스가 고갈된 상황에서 성능 문제가 발생할 수 있습니다.
클러스터 내에 리소스가 고갈된 경우
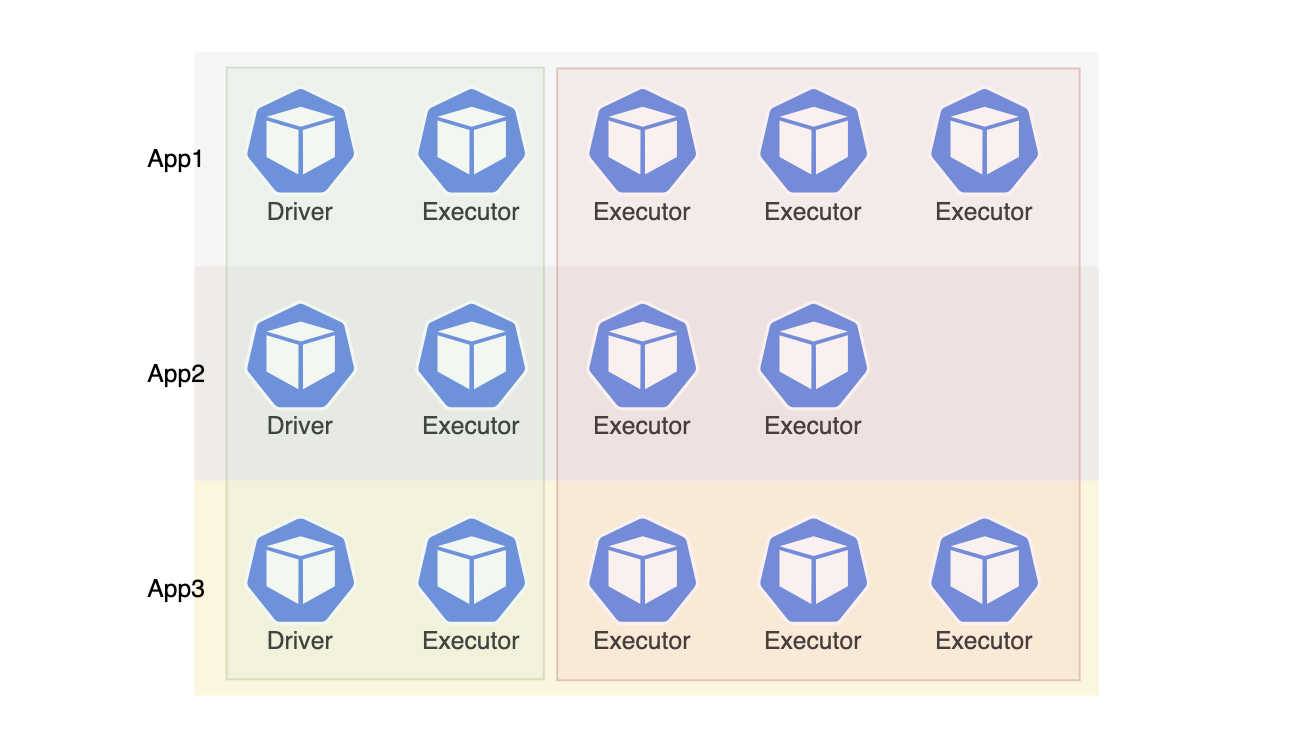
클러스터의 리소스 풀이 요청 받은 리소스보다 부족한 상황이라고 가정해보겠습니다. 위 그림에서 녹색은 실제로 노드에 할당되어 running 중인 pod, 빨간색은 리소스가 부족으로 인해 pending 상태의 pod 입니다.
각 앱은 리소스 경쟁에 의해 driver와 executor 1개씩 정상적으로 생성되어 3개의 앱이 실행 중인 상태입니다. 하지만 3개의 앱은 executor 리소스를 확보하지 못했기 때문에 작업을 완료할 수 없습니다. EKS 환경이라면 노드 리소스를 확보하더라도 VPC IP 고갈 문제로 인해 이러한 상황을 충분히 마주칠 수 있습니다.
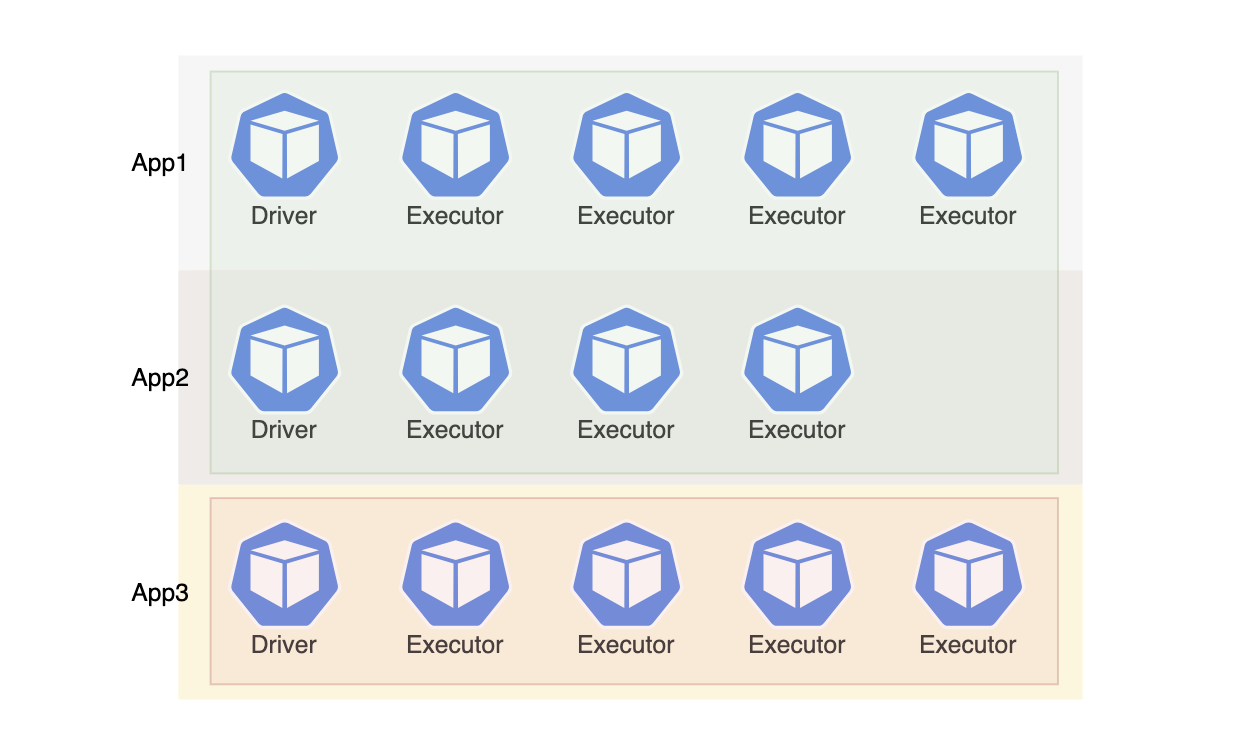
위와 같이 리소스 내에서 가능한 앱이 정상적으로 실행, 종료되고 나머지는 대기하는게 더 효율적이라고 볼 수 있습니다.
쿠버네티스에서는 기본 스케줄러가 배치 작업에 최적화된 형태가 아니기 때문에 위와 같은 문제가 발생할 수 있습니다. 이를 해결하기 위해 kube-batch, volcano, yunikorn 등의 커스텀 배치 스케줄러가 개발되었습니다.
Spark App-aware Scheduling
기본 스케줄러는 filtering, scoring 과정을 거쳐 pod가 실행될 최적의 노드를 찾습니다. 이 때 스케줄 단위는 pod 입니다. 반면 대용량 배치 작업에서는 동시에 수 백개의 pod가 생성되기도 합니다. 또한 동시에 여러 작업이 실행되기 때문에 우선순위, 조직 별 리소스 제한 등을 고려해서 안정적으로 작업을 마치기 위한 대기열이 필요합니다.
커스텀 배치 스케줄러에서는 이를 해결하기 위해 앱 단위로 스케줄을 결정하는 App-aware 방식을 사용합니다. 뿐만 아니라 대용량 배치 작업을 위해 Job Ordering, Hierarchy Resource Queue, Node Sorting 단계에서 다양한 스케줄링 알고리즘을 지원합니다.
Bin Packing
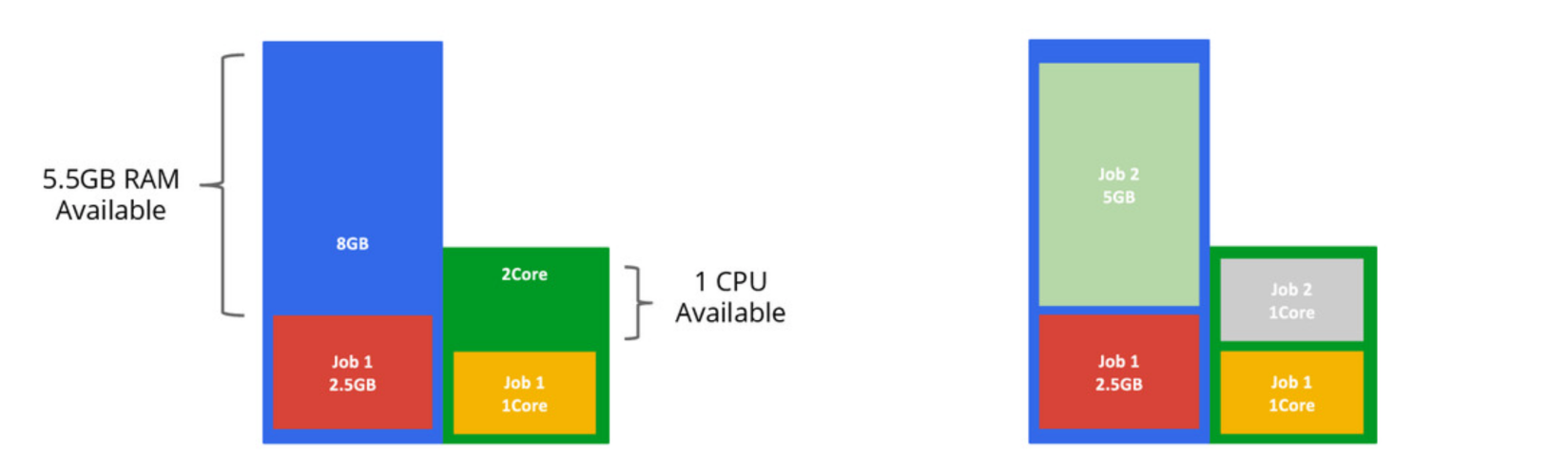
Node Sorting 단계를 예시로 들어보겠습니다. 기본 스케줄러에서 driver, executor pod가 여러 노드에 고르게 분산하면 앱은 네트워크 지연, 셔플 시 원격에서 데이터를 가져와야 하는 상황이 발생합니다.
이 때 테트리스처럼 Bin Packing 방식을 적용한다면 어플리케이션을 최대한 가깝게 할당할 수 있습니다. 클라우드 환경에서 이를 적용하면 노드 scale-in도 원활하게 수행할 수 있습니다.
Spark Gang Scheduling
앞서 리소스가 고갈된 상황의 경우, Gang Scheduling을 사용한다면 안정적으로 작업을 실행할 수 있습니다. 노드가 0대인 상황에서 앱이 제출되었다고 가정해보겠습니다.
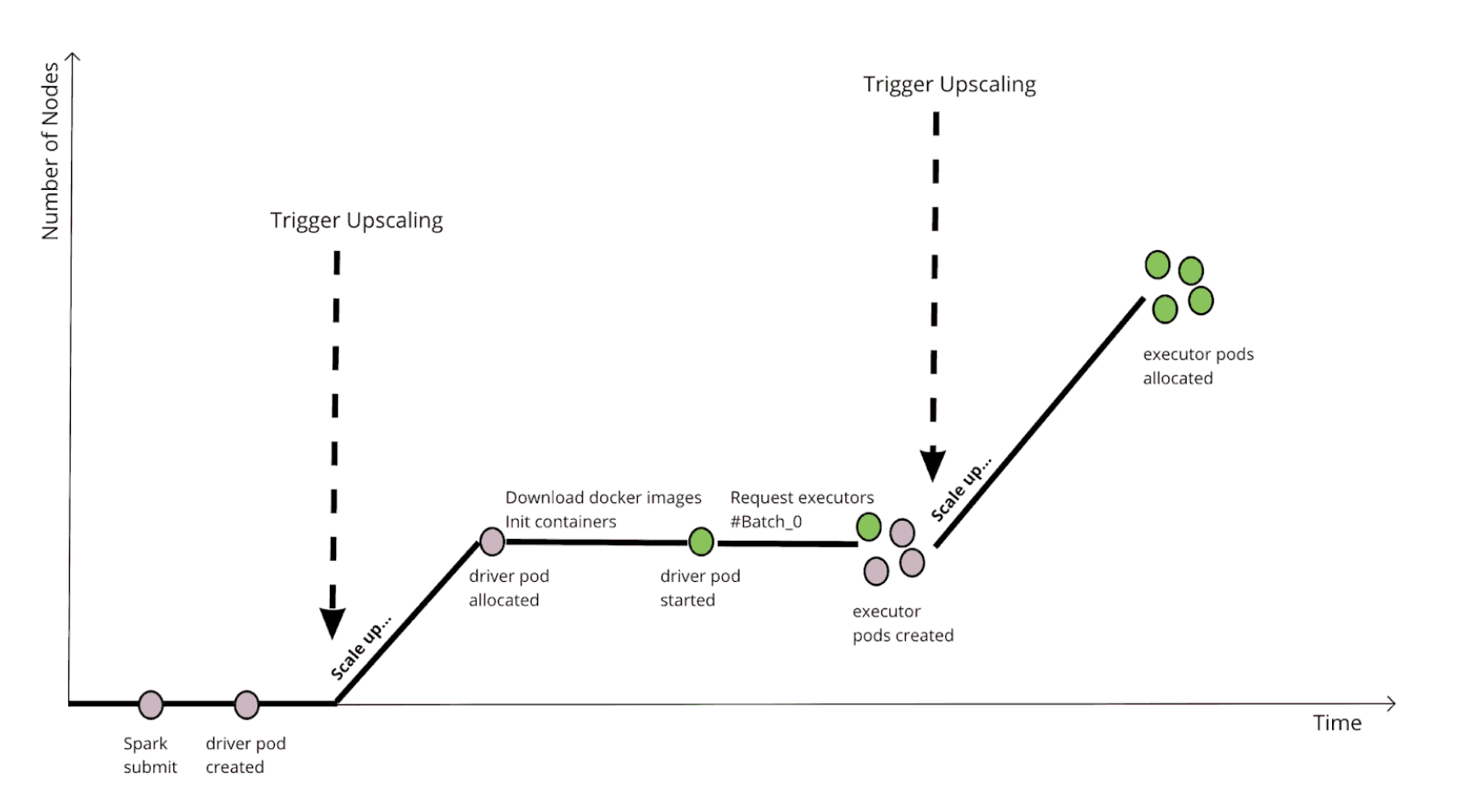
위의 그림은 기본 스케줄러를 적용했을 때 모습입니다.
필요한 최소 리소스가 미리 정해져있으나 노드 생성까지 대기 시간이 발생합니다.
- driver 리소스 요청 → 1대 생성
- executor 리소스 요청 → 2대 생성
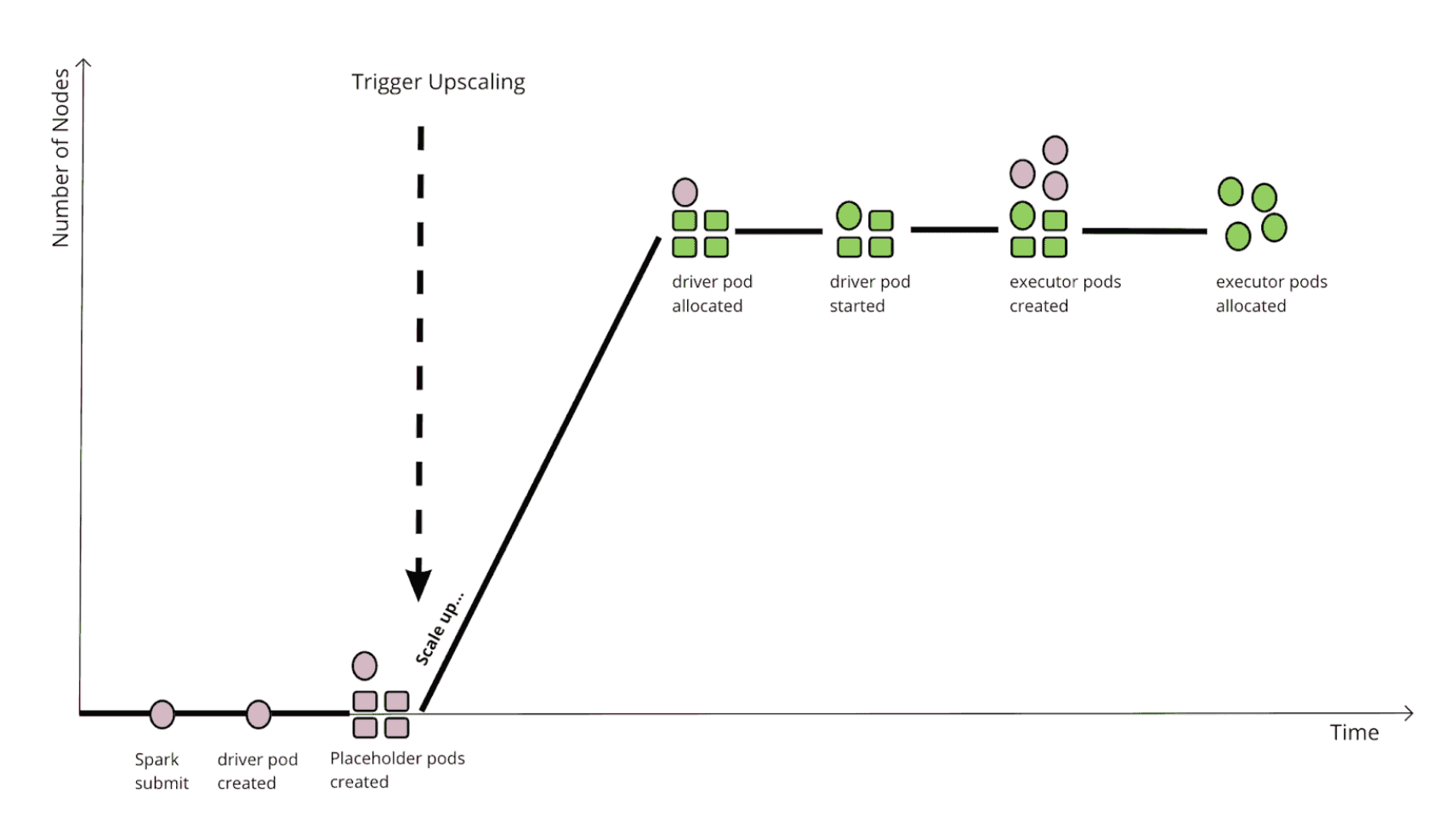
위의 그림은 gang 스케줄링을 적용했을 때 모습입니다.
한번에 필요한 리소스를 확보하여 대기 시간을 최소화합니다.
- driver 리소스 요청 → placeholder 리소스 요청 → 노드 3대 생성
- driver, executor pod 즉시 할당
여기에서 placeholder pod은 아무 동작도 안하지만 미리 리소스를 확보하기 위해 존재하는 dummy pod 입니다. 만약 리소스를 확보하지 못하는 상황이라면 앱은 대기합니다. Gang Scheduling은 FIFO 큐와 함께 실행하여 리소스 경쟁으로 인한 교착상태에 빠지지 않도록 할 수 있습니다.
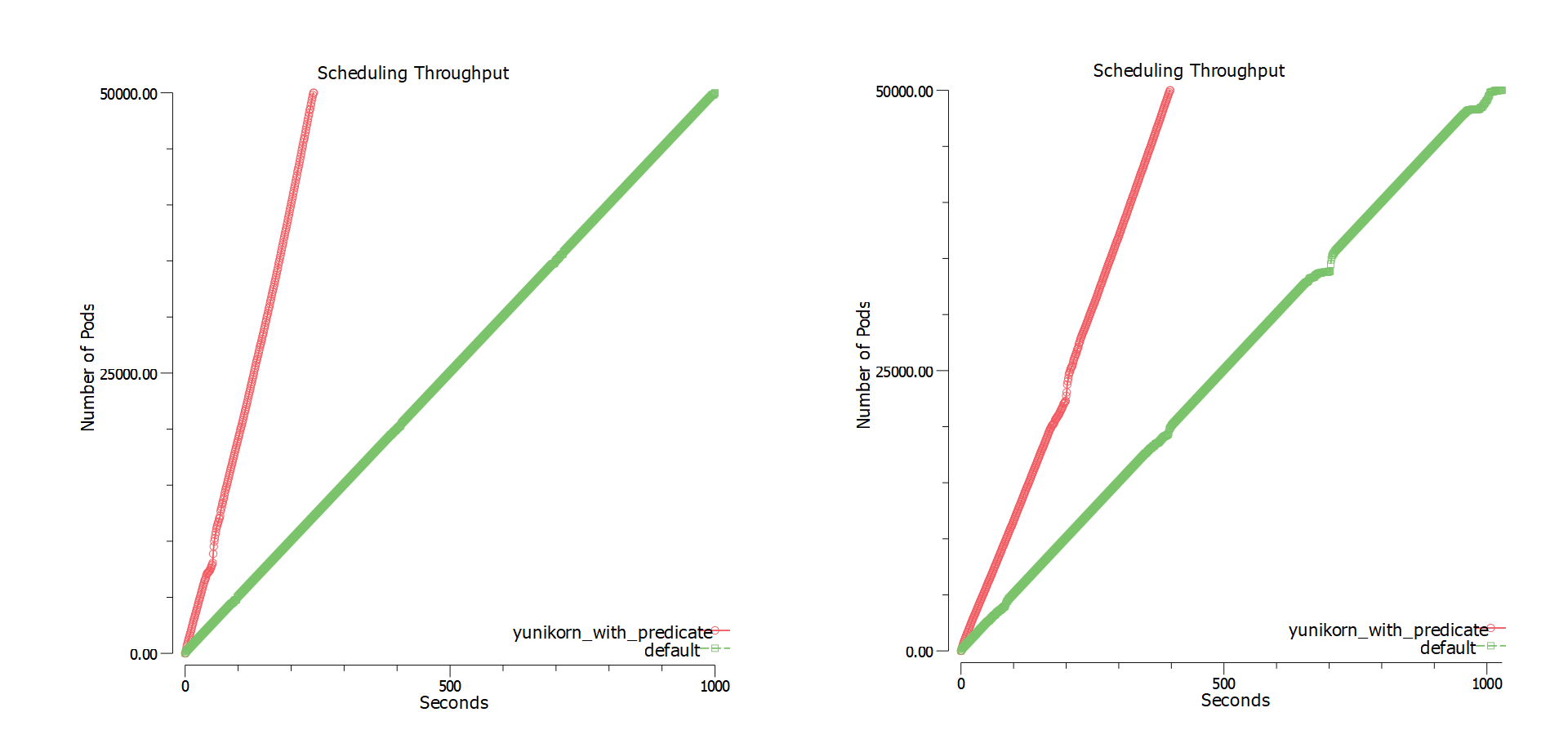
또한 동시 실행 Pod가 많을 수록 스케줄링 성능 향상을 기대할 수 있습니다. 위 그림은 Yunikorn에서 kubemark를 통해 벤치마크한 결과입니다. 회사 환경에서 spark 작업 시간을 기준으로 테스트했을 때도 성능 향상을 확인할 수 있었습니다.
다음 글에서는 Spark 3.4 버전에서 공식적으로 지원하는 Volcano, Yunikorn에 대해 이어서 정리해보겠습니다.